Internet Address 인터넷 주소
IPv4(32 bits)- 현재 사용되는 주소 체계
- 호스트 수의 가능한 수: 42억 9,496만 7,296개
IPv6(128 bits)- IPv4 주소 고갈되어서 IPv4를 대체하기 위해 설계된 새로운 주소 체계
- 아직 널리 사용되지는 않았지만, 결국 사용될 것이다.
- IPv6를 지원하기 위해 라우터를 업그레이드해야 하는데, 시간이 좀 걸린다.
IP address : notations
- Binary notation
- Dotted-decimal notation
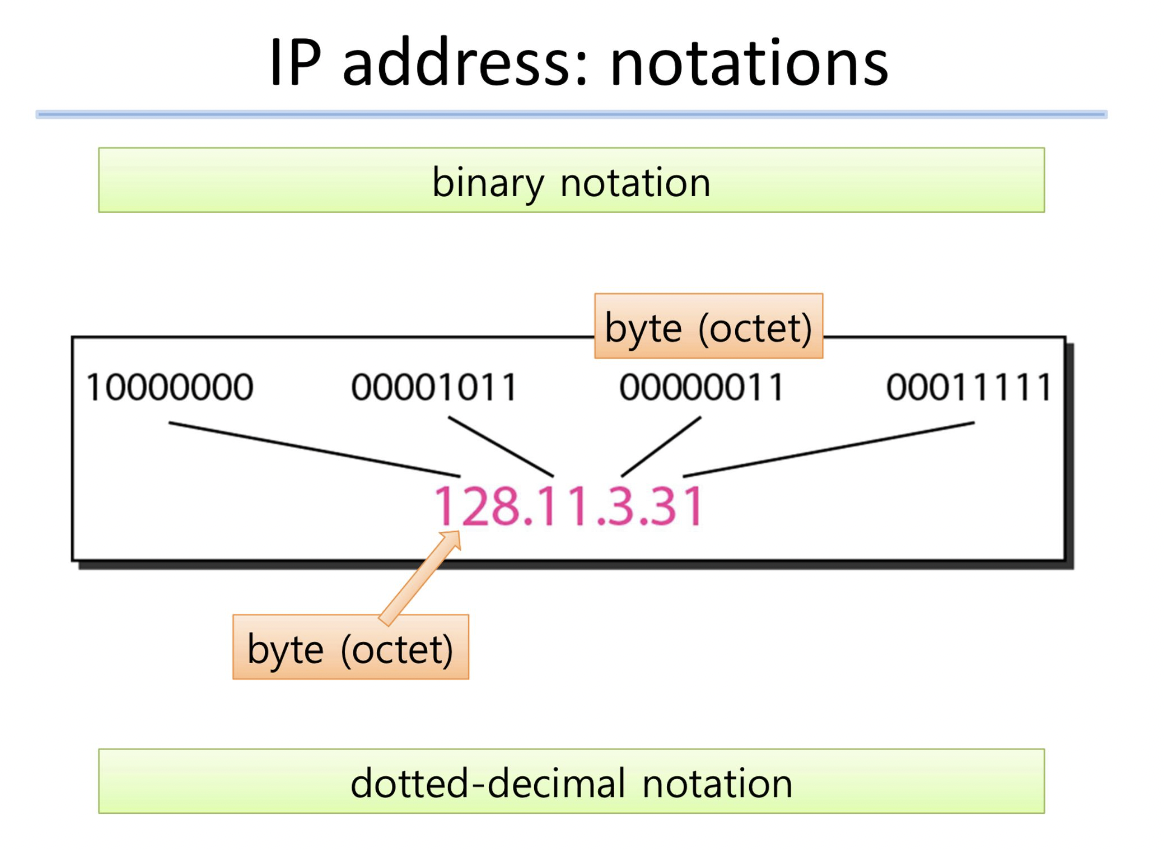
다음 IPv4 주소를 점으로 구분된 십진 표기법(dotted-decimal notation)으로 변환하십시오.
- 10000001 00001011 00001011 11100111 → 129.11.11.231
- 11000001 10000011 00011011 11111111 → 193.131.27.255
점으로 구분된 십진 표기법: 잘못된 사용 예시
- 111.56.045.78 (잘못된 형식, 올바른 형식은 111.56.45.78) →
0을 맨앞에 넣으면 안됨
- 221.34.7.8.20 (잘못된 형식, 올바른 형식은 221.34.7.8) →
.은 3개사용하고, 총4개의 숫자 덩어리
- 75.45.301.14 (잘못된 형식, 올바른 형식은 75.45.255.14)
→ 301은 0부터 255 사이의 범위를 벗어나는 값이므로 잘못된 형식의 주소→ `IPv4 주소` : (`0~255`의 숫자 사용) - 11100010.23.14.67 (잘못된 형식, 올바른 형식은 111.23.14.67) → 이진 표기랑 같이 쓰면 안됨
IP 주소: 계층 구조
IP주소 = 네트워크 주소 + 호스트 주소(Network address + Host address)- 동일한 네트워크 내의 노드는 동일한 네트워크 주소를 가집니다.
- 이더넷 주소(ethernet address) : 평면 구조(flat) (구조가 없음)
IP address : allocation IP 주소 할당
- IP 주소 할당 시스템(IP address allocation system)
- 관리자(Administrator) : IANA (Internet Assigned Numbers Authority, 인터넷 할당 번호 관리 기관)
•대륙에 주소 공간을 할당합니다.
• 아시아: APNIC (Asia-Pacific Network Information Center 아시아-태평양 네트워크 정보 센터) - APNIC는 아시아 국가에 IP 주소를 할당합니다.
• 대한민국: KRNIC (Korea Network Information Center 한국 네트워크 정보 센터) - KRNIC은 한국의 인터넷 서비스 제공자(ISP, Internet Service Providers) 및 기관에 주소 공간을 할당합니다.
- 관리자(Administrator) : IANA (Internet Assigned Numbers Authority, 인터넷 할당 번호 관리 기관)
Classful Addressing 클래스풀 주소 할당
네트워크 크기를 기준으로 주소 공간을 할당하는 시스템
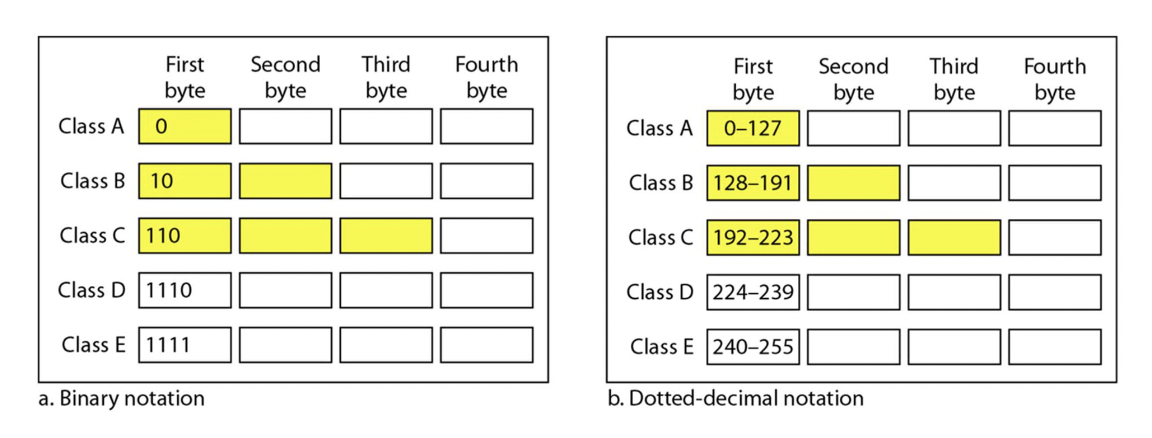
- 클래스 A: IP 주소 (이진 표기법)가 '0'으로 시작합니다.
- 클래스 B: '10'으로 시작합니다.
- 클래스 C: '110'으로 시작합니다.
- 클래스 D : ‘1110’으로 시작합니다.
- 클래스 E : '1111'으로 시작합니다.
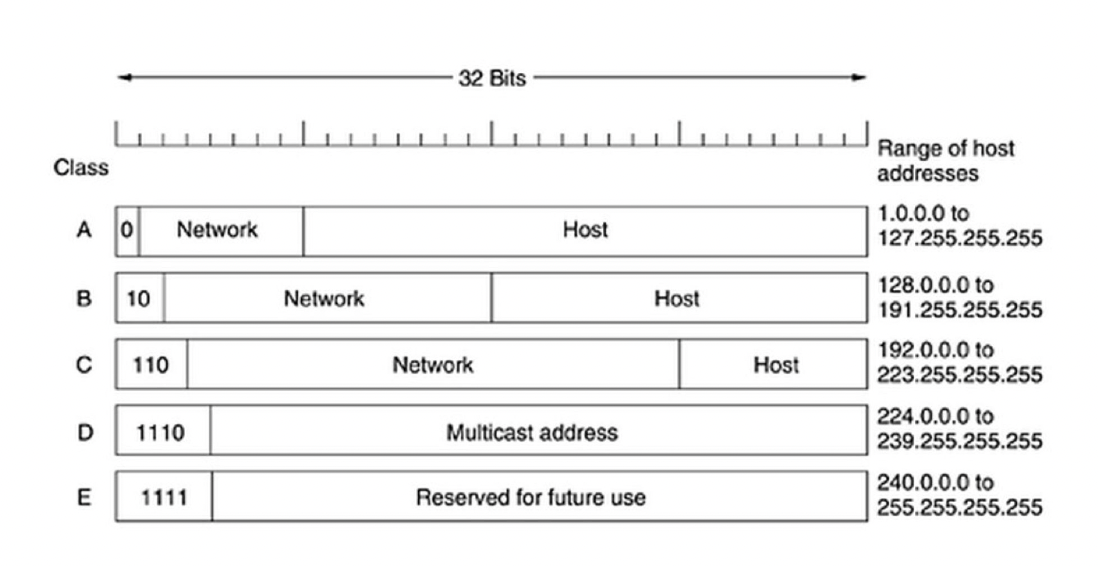
다음 주소들의 클래스는 무엇인가요?
- 00000001 00001011 00001011 11101111: 클래스 A → 0으로 시작
- 11000001 10000011 00011011 11111111: 클래스 C → 110으로 시작
- 14.23.120.8: 클래스 A → 1~127 사이
- 210.115.229.74: 클래스 C → 192~223 사이
- Classful Addressing 문제점
- 클래스 `A 및 B는 너무 크다`: 클래스 A와 B의 주소 공간은 매우 크기 때문에 소규모 네트워크에는 `낭비`적입니다.
- 클래스 `C는 너무 작다` : 클래스 C 주소 공간은 네트워크에 속한 호스트 수가 1000-2000개 정도인 경우에는 `충분하지 않습니다.`
→ `A, B is wasteful and C is not enough`
- 네트워크의 수가 증가함에 따라 주소 공간은 `효율적으로 할당`되어야 합니다.
- 그러므로 Classful addressing은 네트워크의 크기에 제한을 가지고 있어서 주소 공간의 효율적인 할당이 어렵습니다.
- 이로 인해 `Classless inter domain routing (CIDR)이 도입`되었고, CIDR은 Classful addressing의 문제를 해결하고 보다 `유연하고 효율적인 IP 주소 할당`을 가능하게 합니다. `CIDR은 주소 공간을 보다 세분화`하여 `작은 네트워크를 조합`하거나 `필요한 만큼의 주소 공간을 할당`할 수 있도록 합니다. 이를 통해 `주소 공간의 효율성을 향상`시키고 `라우팅 효율`을 높일 수 있습니다.-
네트워크 주소:호스트 그룹으로 네트워크를 나타냅니다.- 클래스 A: 7bit
- 클래스 B: 14bit
- 클래스 C: 21bit
-
호스트 주소:네트워크 내의 호스트를 나타냅니다.- 클래스 A: 24bit
- 클래스 B: 16bit
- 클래스 C: 8bit
-
대형 ISP 또는 기관의 경우, 클래스 A 주소 공간이 할당됩니다.
-
작은 ISP 또는 기관의 경우, 클래스 B 또는 클래스 C 주소 공간이 할당됩니다
→ Large ISP : Class A
→ Small ISP : Class B, Class C
Subnetting : 주소 공간을 재할당 → 여러 개의 서브넷
- 기관은
주소 공간을 재할당(re-allocate)하여여러 개의 서브넷을 구성할 수 있습니다. Subnet Masks는 호스트 부분을 subnet ID와 host ID로 분할하는 데 사용됩니다. →host number = subnet ID + host ID

Classless Addressing = CIDR(Classless Interdomain Routing)
-
슈퍼네팅(Supernetting) : subnet mask를 사용해 여러 개의 네트워크 주소를 결합- 서브네팅과 유사하게
여러 개의 네트워크 주소를 결합하기 위해 서브넷 마스크를 사용하는 것이 가능합니다.
- 서브네팅과 유사하게
-
서브넷 마스크를 사용하여 어떤 크기의 네트워크든 정의할 수 있습니다.
-
CIDR(Classless Interdomain Routing)로도 불립니다.- 현재의 라우터에서 널리 사용됩니다.
- IP 주소 공간을 보다
유연하고 효율적으로 사용할 수 있도록 합니다. CIDR은 IP 주소를 엄격한 클래스 (A, B, C)로 나누지 않고,접두사 길이또는서브넷 마스크를 사용하여 표현합니다. - CIDR은
여러 작은 네트워크를 더 큰 블록으로 통합하여라우팅 항목의 수를 줄이고라우팅 효율성을 향상시킵니다. CIDR은 네트워크 주소를 더세분화하고 IP 주소를 더효율적으로 할당하는 데 도움이 됩니다. - CIDR 표기법은
IP 주소와 해당 서브넷 마스크를 IP 주소 다음에 슬래시 (/)와 함께 유효한 비트 수로 표시합니다. 예를 들어, 192.168.0.0/16은 서브넷 마스크가 255.255.0.0인 네트워크 주소를 나타냅니다. - CIDR은 클래스풀 주소 할당 방식과 비교하여 IP 주소 할당과 라우팅에서 더 유연성, 확장성 및 효율성을 제공하며 현대의 네트워크에서 표준 방법으로 사용됩니다.
-
주소 할당의 새로운 접근 방식
-
No class :
주소가 주소 블록으로 할당됩니다. -
주소 할당의 세 가지 규칙:
- 주소 공간은
연속적(continuous)이어야 하고, 분할되면 안된다. (address space : continuous O, partitioned X) - 주소의
개수는 2의 거듭제곱이어야 합니다. - 블록 내
첫 번째 주소는 블록 내 주소 개수로 나누어 떨어져야합니다.
- 주소 공간은
-
예시: 조직이
16개의 주소가 필요한 경우 - 205.16.37.32 ~ 205.16.37.47로 할당됨
조직이 16개의 주소가 필요한 경우, 주소 블록은 205.16.37.32에서 205.16.37.47까지 할당됩니다. 이러한 주소 할당은 연속적이며, 주소의 개수가 2의 거듭제곱이며(2^4) 주소 블록의 첫 번째 주소인 205.16.37.32는 주소 블록 내의 주소 개수 16으로 나누어 떨어집니다. 이를 통해 조직은 필요한 주소를 효율적으로 할당받을 수 있습니다.
- Network Mask
-
네트워크 마스크는
동일한 네트워크를 나타내는 IP 주소의 접두사입니다. -
IP 주소가 210.115.227.98이고 서브넷 마스크가 255.255.255.0인 경우, 이를 이진수로 표현하면 다음과 같습니다
-
IP 주소: 11010010 01110011 11100011/ 01100010
→ 네트워크 주소 :
210.115.227.0(11010010 01110011 11100011)→ 호스트 주소 :
0.0.0.98(01100010)
서브넷 마스크: 11111111 11111111 11111111 00000000
-
네트워크 마스크는
IP 주소의 네트워크부분을 나타내며,네트워크 주소와 호스트 주소를 구분합니다. 이 경우,네트워크 부분은 IP 주소의 처음 24비트이므로, 네트워크 주소는210.115.227.0입니다.호스트 주소는 IP 주소의 마지막 8비트이므로, 호스트 주소는0.0.0.98입니다. 이를 통해 네트워크 마스크를 사용하여 IP 주소를 네트워크와 호스트로 구분할 수 있습니다. -
네트워크 마스크는
x.y.z.t/n형식으로 표현되며, 여기서n은 서브넷 마스크의 길이(subnet mask) 또는 프리픽스 길이(prefix length)를 나타냅니다. -
주어진 예시인
205.16.37.39/28의 경우, 이를 이진수로 표현하면 다음과 같습니다: -
IP 주소:
11001101 00010000 00100101 00100111
prefix length :28 -
prefix length 28은 이진수로
11111111 11111111 11111111 11110000과 같은28비트의 서브넷 마스크(28개의 1)를 의미합니다. 이로부터 네트워크 주소와 호스트 주소를 추출할 수 있습니다. -
네트워크 주소는 IP 주소와 서브넷 마스크를AND 연산하여 구합니다. 여기서는 IP 주소의 처음 28비트와 서브넷 마스크의 처음 28비트를 AND 연산하여 네트워크 주소를 얻을 수 있습니다. 호스트 주소는 IP 주소의 마지막 4비트이므로, 호스트 주소는 37.39입니다. -
따라서 주어진 IP 주소 205.16.37.39와 프리픽스 길이 28을 사용하여 네트워크 주소와 호스트 주소를 구할 수 있습니다.
💡 네트워크 주소 = IP 주소 && 서브넷 마스크 -
Exercise : ISP 가 IP 주소 블럭에 할당되었다. 주소 중 하나는
205.16.37.39/28이다. 해당 IP주소 블럭의첫 번째 주소는 무엇인가? -
Answer : 205.16.37.32(11001101 00010000 00100101
00100000)주어진 IP 주소 블록인 205.16.37.39/28에서
첫 번째 주소는 호스트 비트를 모두 0으로 설정하여 결정할 수 있습니다.블록의 주소 중 하나가 205.16.37.39이고,
첫 번째 주소는 호스트 비트인 마지막 4비트를 0으로설정하면 된다.블록의 첫 번째 주소인 205.16.37.32의 이진 표현은 11001101 00010000 00100101
00100000입니다. 이 주소는 블록의 네트워크 주소를 나타냅니다.일반적으로 블록의 첫 번째 주소는 주소 블록 자체를 나타냅니다. 따라서 이 경우 205.16.37.32/28은 205.16.37.32부터 205.16.37.47까지의 주소 블록을 의미할 수 있습니다.
→ 블록의 주소 중 하나 : 11001101 00010000 00100101
00100111(205.16.37.39)→ 블록의 첫 번째 주소 : 11001101 00010000 00100101
00100000(205.16.37.32)
-
Exercise : ISP 가 IP 주소 블럭에 할당되었다. 주소 중 하나는
205.16.37.39/28이다. 해당 IP주소 블럭의마지막 주소는 무엇이고, 블록에 있는주소의 개수는 얼마인가? -
Answer :
블록의 마지막 주소를 찾기 위해, 브로드캐스트 주소를 결정해야 합니다. 접두사 길이가 /28인 서브넷에서,
브로드캐스트 주소는 모든 호스트 비트를 1로 설정하여 얻습니다. 이 경우,호스트 비트는 마지막 4비트입니다.
-
호스트 비트(마지막 4비트)를 이진수로 변환하면 다음과 같습니다 :
0011(11001101.00010000.00100101.00100111) -
주어진 주소 (205.16.37.39)에서 호스트 비트를 1111로 대체하면 다음과 같습니다:
205.16.37.47(11001101.00010000.00100101.00101111) -
따라서 블록의 마지막 주소는
205.16.37.47입니다. -
주소 블록의 크기는 접두사 길이에 따라 결정됩니다. 주어진 접두사 길이인 /28에서
호스트 비트는 4비트입니다. 블록에 있는 주소의 수를 계산하기 위해,2^(32 - 접두사 길이)의 공식을 사용할 수 있습니다. 이 경우, 접두사 길이는 28이므로 계산은 다음과 같습니다:
2^(32 - 28)= 2^4 = 16 -
호스트 비트는 2^4 = 16개의 주소를 나타낼 수 있습니다.
-
따라서 블록에는
16개의 주소가 있습니다.
-
첫번째 주소 : 호스트 비트인 마지막 4비트를 0으로 설정
마지막 주소 :호스트 비트인 마지막 4비트를 1로 설정
주소의 개수 : 2^(32-접두사 길이)
Forwarding with CIDR (CIDR를 사용한 포워딩)
- 라우팅 테이블은 항목을 저장해야 합니다.
Entry 항목 : (Destination 목적지, Next Hop 다음 홉)
- 라우팅 테이블의 크기는 성능에 영향을 줍니다.
큰 크기는 처리 속도를 늦춥니다.공간이 너무 많이 필요합니다.
- Solution :
Prefix Routing
Prefix Routing
-
예를 들어,
194.24.x.x가영국 캠브리지 대학의 호스트를 나타낸다고 가정해보겠습니다. -
서강대학교의 라우터로부터,
- 목적지 주소
194.24.1.1, 194.24.83.72, 194.24.235.55는 동일한 next hop 라우터를 갖는 것이 가능합니다. - 따라서, 이러한 목적지에 대해서는
하나의 라우트 항목만 유지됩니다. - 목적지: 194.24.0.0/16
- 만약
목적지의 처음 16비트가 194.24.0.0와 일치하는 경우에 이 항목을 사용해야 합니다.
- 목적지 주소
-
대학교의 호스트 주소가 다음과 같다고 가정해봅시다.
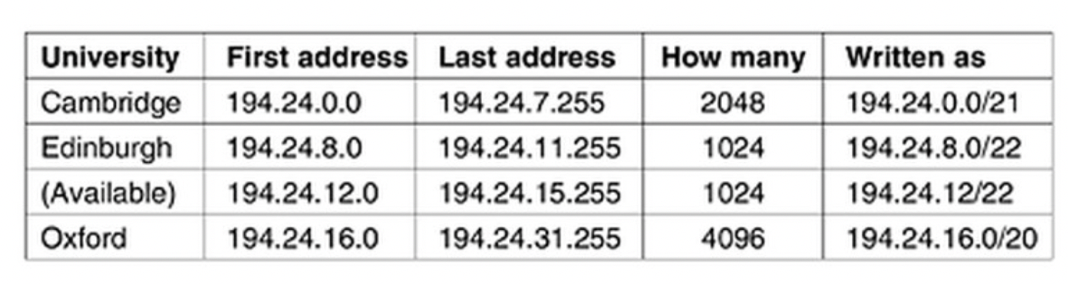
- 그러면 라우팅 테이블은 다음과 같이 유지됩니다.
- 캠브리지: 194.24.0.0/21
- 에든버러: 194.24.8.0/22
- 옥스포드: 194.24.16.0/20
194.24.17.4주소로 가는 패킷의 경우 00010001- 처음 21비트를 194.24.0.0과 비교하면 일치하지 않음 00000000
- 처음 22비트를 194.24.8.0과 비교하면 일치하지 않음 00001000
- 처음 20비트를 194.24.16.0과 비교하면 일치함 00010000
- 따라서,
옥스포드의 경로가 사용됩니다.
- 일치하는 엔트리가 여러 개인 경우
가장 긴 접두사를 가진 엔트리가 사용됩니다.
→ 뒤의 /prefix 에서 prefix만큼의 비트가 일치해야 이걸로 라우팅될 수 있음
—좀 더 설명—
194.24.17.4 주소로 가는 패킷의 경우,
- 먼저, 194.24.17.4 주소의 첫 21비트를 194.24.0.0과 비교하면 일치하지 않습니다. 따라서, Cambridge의 경로는 해당되지 않습니다.
- 다음으로, 194.24.17.4 주소의 첫 22비트를 194.24.8.0과 비교하면 일치하지 않습니다. Edinburgh의 경로도 해당되지 않습니다.
- 그러나, 194.24.17.4 주소의 첫 20비트를 194.24.16.0과 비교하면 일치합니다. 따라서, Oxford의 경로가 사용됩니다.
- 여기서 중요한 점은,
일치하는 엔트리가 여러 개인 경우 가장 긴 접두사를 가진 엔트리가 사용된다는 것입니다. 194.24.17.4 주소는 194.24.16.0/20의 접두사 길이인 20비트와 일치하며, 이것이 다른 경로보다 긴 접두사를 가지기 때문에 Oxford의 경로가 선택됩니다.
따라서, 194.24.17.4 주소는 Oxford의 경로로 전달되며 해당 네트워크로 라우팅됩니다.
목적지 IP 주소: 194.24.17.25 (11000010 00011000 00010001 00011001)
이제 이진 표현과 가능한 경로들을 비교해보겠습니다:
- 케임브리지: 194.24.0.0/21 → 여기는 21이니까 21비트가 같아야함
• 11000010 00011000 00000000 00000000
• 처음 21비트가 일치하지 않으므로 일치하지 않습니다. - 에든버러: 194.24.8.0/22 → 여기는 22니까 22비트가 같아야함
• 11000010 00011000 00001000 00000000
• 처음 22비트가 일치하지 않으므로 일치하지 않습니다. - 옥스포드: 194.24.16.0/20 → 여기는 20이니까 20비트가 같아야함
• 11000010 00011000 00010000 00000000
• 접두사 일치! 처음 20비트가 접두사와 일치합니다.
194.24.17.25의 접두사가 옥스포드의 경로 (194.24.16.0/20)와 일치하므로, 이 패킷은 옥스포드 경로를 통해 라우팅될 것입니다.
가장 긴 매칭 접두사 (Longest matching prefix)
- 만약 목적지 IP 주소가
194.24.14.72인 경우, 어떤Next Hop을 사용해야 할까요?
→ 접두사(맨 뒤에거)가 가장 긴거!
→ 그게 더 구체적인 경로이다
목적지 : 11000010.00011000.00001110.01001000
194.24.0.0/19 : 11000010.00011000.00000000.00000000 ok
194.24.12.0/22 : 11000010.00011000.00001100.00000000 ok, longer → 선택
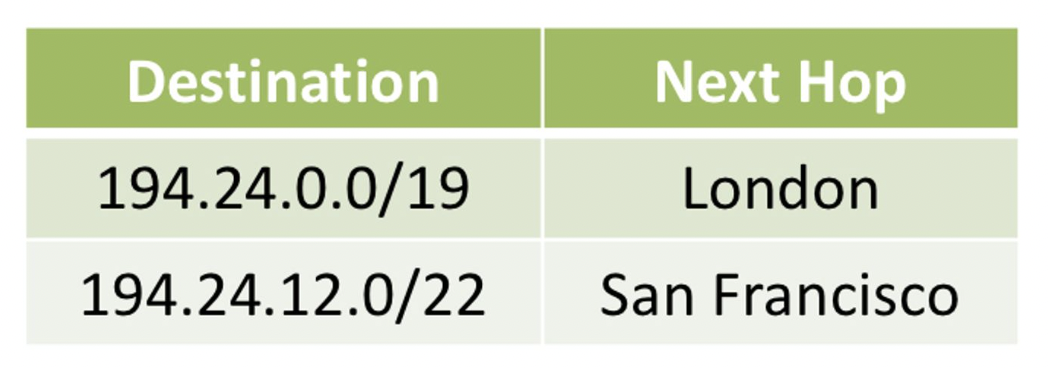
- 두 경로 모두 일치하지만,
194.24.12.0/**22**의접두사 길이가 더 길기때문에샌프란시스코가 다음 홉으로 선택됩니다. 가장 긴 접두사: 더 구체적인 경로
Route aggregation(경로 집계)
- 라우팅 테이블의 크기를 줄이기 위해
여러 작은 경로 항목을 하나의 큰 항목으로 결합하는 기술입니다. - 서강대학교의 라우터에서는 케임브리지, 에딘버러, 옥스포드로 가는 경로가 모두
동일한 Next Hop을 가지고 있는 경우입니다. 이러한 세 개의 경로 항목을 집계할 수 있습니다(Route aggregation 경로 집계) - 개별 경로를 살펴보겠습니다:
- 케임브리지: 194.24.0.0/21
- 에딘버러: 194.24.8.0/22
- 옥스포드: 194.24.16.0/20
- 이러한 경로를 집계하기 위해,
공통된 접두사 "194.24."를 찾고, 개별 경로를 모두 포함하는가장 긴 접두사 길이를 결정할 수 있습니다. 이 경우,가장 긴 접두사 길이는 19비트입니다. → 케임브리지, 에딘버러, 옥스포드의 194.24 이후의 비트에서 동일한 비트가 17~19비트까지라는 것!! 그 다음부터는 다르다는 것!!
- 따라서 이러한 경로를 하나의 항목으로 집계할 수 있습니다
aggregated : 194.24.0.0/19- 경로 집계는 여러 개의 경로 엔트리를 더 간결하고 효율적인 하나의 경로로 대체하는 것을 의미합니다. 집계된 경로는 원래의 경로 엔트리들을 대체하면서도 동일한 네트워크 범위를 표현합니다. 이를 통해
라우팅 테이블의 크기를 줄이고 라우터의 처리 성능을 향상시킬 수 있습니다.
