(1) 통계의 의해
- <1> 통계란?
- 분석하고자 하는 집단에 대해서 조사하거나 실험을 통해서 얻는 자료 또는 이의 요약된 형태
- <2> 표본조사란?
- 불확실한 상황에서 효과적인 의사결정을 할 수 있도록 수치자료를 수집하고, 정리하고, 표현하고, 분석하는 이론과 방법을 연구하는 학문
- <3> 통계분석이란?
- 특정집단을 대상으로 자료를 수집하여 대상집단에 대한 정보를 구하고, 적절한 통계 분석 방법을 이용하여 의사결정(통계적 추론)을 하는 과정을 말한다.
(2) 표본 조사
- <1> 표본 : 여러 통계 자료를 포함하는 집단 속에서 그 일부를 끄집어내어 조사한 결과로 원래의 집단의 성질을 추측할 수 있는 통계 자료. 샘플
- <2> 표본 집단 : 표본 조사에서 선정된, 어떠한 특성을 공유한 집단
- 모집단을 조사하기에는 비용 및 시간적 한계가 있어 모집단 일부분을 조사하여 모집단의 특성을 파악하고자 하는 것
- 모집단을 특정할 수 없는 경우 표본조사 수행
- 표본의 크기가 클수록 모수의 구간추정에 있어서 신뢰구간 범위 좁힐 수 있음.
(3) 표본 추출 방법
-
<1> 단순 랜덤 추출법
- 표본 추출 방법 중 가장 쉽고 단순한 방법
- N개의 모집단에서 n개의 데이터를 무작위로 추출하는 방법
- 사다리 타기, 제비뽑기와 같은 방법
-
<2> 계통 추출법
- 모집단의 원소에 차례대로 번호를 부여한 뒤 일정한 간격을 두고 데이터를 추출하는 방법
- (1) N개의 모집단에서 k개씩 n개의 구간으로 나눔
- (2) 첫 구간에서 하나를 임의로 선택하고 동일한 가격으로 k개식 띄어서 표본을 추출
-
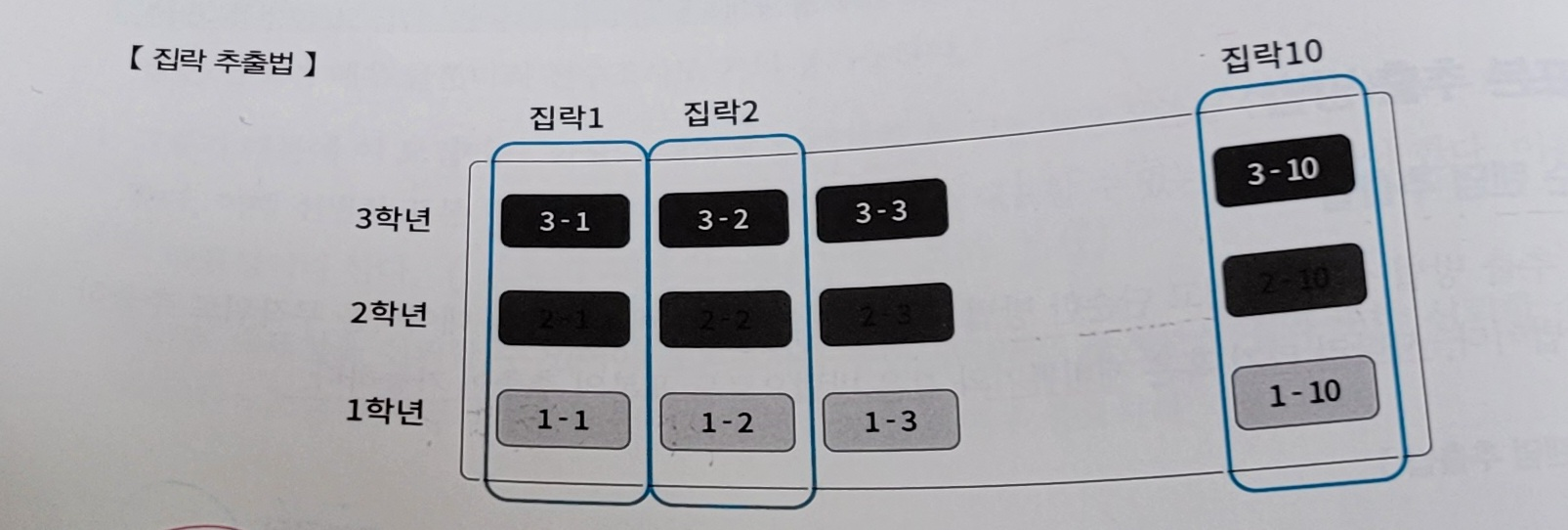
<3> 집락(Cluster, 군집) 추출법
- 데이터를 여러 집락으로 구분한 뒤, 단순 랜덤 추출법에 의하여 선택된 집락의 데이터를 표본으로 사용하는 방법.
- 각 전체 집락은 서로 동질적이며, 집락 내 데이터는 서로 이질적이다.
-
<4> 층화 추출법
-
집락 추출법과 유사하나 반대의 성격 지님
-
데이터를 여러 집락으로 구분하지만 각 집락은 서로 이질적이며, 군집 내 데이터들은 서로 동질적

-
비례 층화 추출법
- 전체 데이터의 분포를 반영하여 각 군집별 데이터를 추출하는 방법.
- 각 군집별로 추출되는 데이터의 개수는 전체 데이터의 분포의 비율과 동일하게 유지해서 표본을 추출하는 방법
-
불비례 층화 추출법 : 전체 데이터의 분포를 반영하지 않고 각 군집에서 원하는 개수의 대이터를 추출하는 방법, 원하는 군집에서 원하는 표본의 개수를 추출하는 것.
-
(4) 측정과 척도
- 측정 : 표본조사를 실시하는 경우 추출된 원소들이나 실험 단위로부터 주어진 목적에 적합하게 관측해 자료를 얻는 것
- 척도 : 관측 대상의 속성을 측정하여 그 값이 숫자로 나타나도록 일정한 규칙을 정하여 바꾸는 도구
- 질적 척도
- 명목척도 - 측정 대상이 어느 집단에 속하는지 나타내는 자료 (속성 분류)
- ex) 성별, 지역 등
- 순서척도 (서열척도)
- 측정대상이 명목척도이면서 서열 관계를 갖는 자료 (순서 관계를 밝혔다)
- ex) 선호도, 신용도, 학년 등
- 명목척도 - 측정 대상이 어느 집단에 속하는지 나타내는 자료 (속성 분류)
- 양적 척도
- 구간척도 (등간척도) - 측정 대상이 가지고 있는 속성의 양 측정 가능, 두 구간사이에 의미가 있는 자료, 계산가능하지만 0점이 존재 x, 간격이 존재
- ex) 온도, 지수 등
- 비율척도
- 측정 대상이 구간척도 이면서 절대적 기준 0이 존재하여 사칙연산이 가능한 자료
- ex) 신장, 무게, 점수, 간격 등
- 구간척도 (등간척도) - 측정 대상이 가지고 있는 속성의 양 측정 가능, 두 구간사이에 의미가 있는 자료, 계산가능하지만 0점이 존재 x, 간격이 존재
- 질적 척도
(5) 추리통계 (추론통계)
- 수집한 데이터를 바탕으로 '추론 및 예측'하는 통계 기법
- 표본에서 얻은 통계치를 바탕으로 오차를 고려하면서 모수를 확률적으로 추정하는 통계 기법
- 표본에서 얻은 통계치를 가지고 모집단의 특성을 추정하는 데 초점을 두고 가설을 검증하거나 확률적인 가능성을 파악한다.
- 향후 발생할 수 있는 사건을 예측 가능
(6) 분산과 표준편차
- 편차 (difference) : 평균과의 차이
- 분산 (variance)
- 평균으로부터 얼마만큼 떨어져 있는지 그 분포를 나타내는 숫자
- 편차 제곱 합의 평균
- 표준편차 (Standard Deviation)
- 분산이 편차 제곱합의 제곱이기 때문에 단위를 일치시키기위해 분산에 루트를 씌움
(7) 확률과 확률 분포
- <1> 확률
- 발생 가능한 모든 사건들의 집합 표본공간에서 표본공간의 부분집한인 특정 사건 A가 발생할 수 있는 비율을 나타내는 값
- 0과 1 사이의 값
- 가능한 모든 사건의 확률의 합
- <2> 조건부 확률
- 특정 사건 A가 발생했다는 것이 사실이라는 전제하에 또 다른 사건 B가 발생할 확률을 나타낸 값
- 0과 1사이의 값
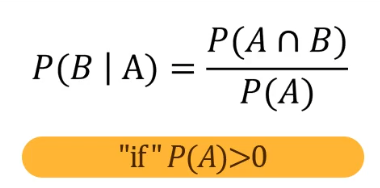
(8) 독립사건과 배반사건
- 독립사건 : 서로에게 영향을 주지 않는 두 개의 사건
- P(B|A) = P(B)
- P(AnB) = P(A)P(B)
- 배반사건
- 두 사건 A와 B에 대하여 교집합, 즉 공통된 부분이 없는 경우
- AnB = ∅
(9) 확률 변수와 확률 분포 그리고 확률 함수
- 확률변수 : 무작위 실험을 했을 때 특정 확률로 발생하는 각각의 결과를 수치적 값으로 표현하는 변수
- <1> 이산확률 변수
- 베르누이 분포
- 확률변수 X가 취할 수 있는 값이 두 개 인 경우
- 이항 분포
- 성공과 실패 단 두가지 사건만 발생 n 번의 베르누이 시행에서 k번 성공할 확률의 분포 의미
- 기하 분포
- 성공 확률이 p인 베르누이 시행에서 처음으로 성공이 나올 때까지 k번 실패할 확률의 분포
- 다항 분포
- 이항 분포 확장, n 번의 시행에서 각 시행이 3개 이상의 결과를 가질 수 있는 분포
- 포아송 분포
- 단위 시간 또는 단위 공간 내에서 발생할 수 있는 사건의 발생 횟수에 따른 확률 분포
- 이산확률변수
- 확률 변수가 취할 수 있는 실수 값의 수를 셀수 있는 변수
- 서로 배반인 사건들의 합집합의 확률은 각 사건의 확률의 합
- 베르누이 분포
- <2> 연속확률 분포
- 균일 분포
- 연속형 확률변수인 X가 취할 수 있는 모든 값에 대하여 같은 확률을 갖고 있는 분포
*면적의 넓이는 확률이 총합인 1
- 연속형 확률변수인 X가 취할 수 있는 모든 값에 대하여 같은 확률을 갖고 있는 분포
- 정규 분포
- 평균이 M이고 표준 편차가 세타인 분포
- t-분포
- 자유도 n, 평균 0
- 모평균 검정 또는 두 집단 평균이 동일한지 계산하기 위한 검정통계량
- 자유도가 커질 수록 t분포는 표준정규분포에 가까워짐
- 카이제곱 분포
- 제곱의 합 X는 자유도가 n인 카이제곱 분포를 따름
- 모평균과 모분산을 모르는 두 개 이상의 집단 간 동질성 검정 (내부구성비) 또는 모분산 검정을 위해 활용
- F 분포
- 등분산 검정 및 분산 분석을 위해 활용
- 연속확률변수
- 확률 변수가 취할 수 있는 실수 값이 어떤 특정 구간 전체에 해당하여 그 수를 셀 수 없는 변수
- 신생아 몸무게 등
- 균일 분포
- <1> 이산확률 변수
(10) 필수 통계 개념
-
첨도 : 뾰족한 정도
- 값이 3에 가까울 수록 정규분포 모양 가짐
- 정규분포의 첨도를 0으로 나타내기 위해 첨도값에서 3을 빼서 사용하기도 함
-
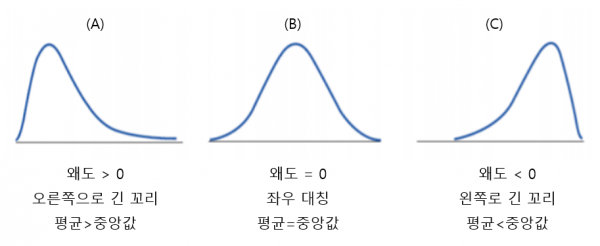
왜도 : 확률 분포의 비대칭 정도
-
왜도 값이 0인 경우 : 평균 = 중앙값 = 최빈값 (정규분포와 유사)
-
왜도 양수 (오른쪽으로 꼬리가 긺) : 최빈값 < 중앙값 < 평균
-
왜도 음수 (왼쪽으로 꼬리가 긺) : 최빈값 > 중앙값 > 평균
-
공분산 : 두 확률변수 X, Y의 상관 정도를 나타내는 값
- 공분산이 음수면 X가 증가할 때 Y는 감소
-
상관계수 : 공분산의 문제를 해결한 값, -1과 1사이
-
(11) 가설 검증
- 모집단의 특성에 대한 주장 또는 가설을 세우고 표본에서 얻은 정보를 이용해 가설이 옳은지를 판정하는 과정
- 귀무가설
- 모집단이 어떠한 특징을 지닐 것으로 여겨지는 가설 (일반적으로 사실일 것으로 여겨지는 가설)
- '차이가 없다' '같다' 기호를 사용하여 나타낼 수 있는 가설
- 연구를 통해 기각하고자 하는 가설, 흔히 H0
- 대립가설
- 귀무가설에 반대, 귀무가설이 틀렸다고 판단되는 경우 채택
- 실험, 연구를 통해 증명하고자 하는 새로운 아이디어 혹은 가설, H1
- 제 1종 오류 : 귀무가설(H0)이 사실인데 귀무가설(H0)이 틀렸다고 결정하는 오류
- 제 2종 오류 : 귀무가설(H0)이 사실이 아님에도 불구하고 귀무가설(H0)이 옳다고 결정하는 오류
- 검정통계량 : 귀무가설의 채택 여부를 판단하기 위해 표본조사를 실시하였을 때 특정 수식에 의하여 표본들로부터 얻을 수 있는 값
- 귀무 가설의 옳고 그름 판단 할 수 있는 값
- 기각역 : 귀무가설을 기각하게 될 검정통계량의 영역, 기각역의 경계값 :임계값
- 유의수준 : 귀무가설이 참인데도 이를 잘못하는 오류를 범할 확률의 최대 허용한계 1%, 5% 주로 사용
- 주로 1종 오류만 통제
- 유의 확률 p-value 귀무가설을 지지하는 정도를 나타냄
- p-value가 a보다 작은 경우, 귀무가설을 기각 대립 가설 채택
(12) 비모수 검정
- 모수 검정
- 표본이 정규성을 갖는다는 모수적특성을 이용하는 통계방법
- 표본 정규성 반드시 확보되어야 함.
- 등간척도, 비율 척도
- 평균
- 피어슨 상관계수
- one sample t-test, two sample t-test, paired t-test, one way anova
- 비모수 검정
- 정규성 검정에서 정규분포를 따르지 않는다고 증명되거나 표본 군집당 10명 미만의 소규모 실험에서와 같이 정규분포임을 가정할 수 없는 경우에 사용
- 순위합검정 적용 가능 -> 자료를 크기 순으로 배열하여 순위를 매긴 다음 순위의 합을 통해 차이를 비교
- 모수의 분포에 대해 어떠한 가정(정규분포)도 하지 않는 경우
- 이상치로 인해 평균보다 중앙값이 더 바람직한 경우, 표본 크기가 작은 경우, 순위가 같은 서수 데이터인 경우에 사용
- 명목척도, 서열척도
- 중앙값
- 스피어만 상관계수
- 부호검정, Wilcoxon 부호순위 검정, Mann-whitney 검정, Kruskal Wallis 검정
