0. Intro
현재 다니고 있는 회사(는 뉴럴웍스랩)에서는 여러 머신러닝 기법들을 제공하고 있다.
모두가 사용할 수 있는 데이터분석 툴을 서비스하는 것을 목표로 해서 솔루션을 제작하고 있는데, 회귀 분석에서 Coefficient, Standard Error, T-Value, P-Value 등이 통계적인 의미로 굉장히 중요하다는 것을 알게 되었다.
위의 표를 웹페이지에 보여주는 것이 목표였는데(이미 제작된 것임), 그러기 위해서는 맨 아래쪽 단에서 해당 수치들을 도출해야 했다.
이번에는 간단하게 Scikit-learn의 Linear Regression 모델을 사용하여 해당 statistics 수치들을 도출하고, statsmodels 패키지의 OLS 모델을 사용하여 도출한 수치들이 신빙성 있는 수치인지 검증해보려고 한다.
💡 해당 포스팅에서 사용한 코드는 https://github.com/bolero2/Regression-statistics 에 업로드 되어 있습니다.
1. Scikit-learn의 Linear Regression
우선, Scikit learn의 Linear Regression 모델을 사용해서 statistics 정보를 구해보아야 한다.
Scikit-learn은 기본적으로 Coefficient 값은 프로퍼티로 들어가 있지만( model.coef_), t-value 라던가 p-value 같은 것은 들어가 있지 않다.
그래서 열심히 구글링을 하여, 좋은 예제 코드를 발견하였다.
stack overflow : Find p-value (significance) in scikit-learn LinearRegression
아래쪽 답변에 좋은 예제가 있는데, 해당 코드로 테스트를 해보면 (뭐 기대하진 않았다...) 당연히 안돌아간다.
해당 코드를 바꿔서 돌려봐야 한다.
(target dataset은 Boston Housing Dataset을 사용하였다.
출처 : https://www.kaggle.com/code/prasadperera/the-boston-housing-dataset/notebook)
전처리는 2개를 수행하였다.
- 결측치 제거
- standard scaling
(위의 전처리는 필자 회사의 데이터셋 부분에서 웹 상으로 처리가 가능하다. 고로 견본 코드는 없음.)
1-1. Linear Regression model 불러오기
모델을 불러와야 한다.
모델은 다음 코드로 객체 생성이 가능하다.
- 모델 준비 코드
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)1-2. 데이터셋 준비
해당 모델 객체를 만들었으면, 데이터셋을 준비해야 한다.
pandas 패키지를 사용하여 위의 boston housing dataset csv 파일을 읽어서, DataFrame 객체로 만들어주자. (우선, 단변량을 대상으로 한다.)
- 데이터셋 준비 코드
import pandas as pd
X_name = ["CRIM"]
Y_name = "MEDV"
df = pd.read_csv("BostonHousing_noNaN_forRegressor.csv")
print(df)
df_x = df[X_name]
df_y = df[Y_name]
df_x.columns = [X_name]- 결과
(base) bolero is in now ~/dc/ml/Regression $ python linear_test.py
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT MEDV
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94 33.4
4 0.02985 0.0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21 28.7
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ...
389 0.17783 0.0 9.69 0 0.585 5.569 73.5 2.3999 6 391 19.2 395.77 15.10 17.5
390 0.22438 0.0 9.69 0 0.585 6.027 79.7 2.4982 6 391 19.2 396.90 14.33 16.8
391 0.04527 0.0 11.93 0 0.573 6.120 76.7 2.2875 1 273 21.0 396.90 9.08 20.6
392 0.06076 0.0 11.93 0 0.573 6.976 91.0 2.1675 1 273 21.0 396.90 5.64 23.9
393 0.10959 0.0 11.93 0 0.573 6.794 89.3 2.3889 1 273 21.0 393.45 6.48 22.01-3. 모델 학습
모델 객체와 DataFrame 객체를 준비해둔 상태로, 모델을 학습시켜주자.
model.fit(df_x.values.reshape(-1,1), df_y.values)여기서 핵심은,
우리는 우선 단변량 으로 학습시킬 것이기 때문에, df_x.values.reshape(-1, 1)을 해줘야 한다는 점이다.
1-4. Statistics 정보 도출
위의 stack overflow 사이트에서 가져온 코드를 사용하여 statistics를 도출할 수 있다.
- statistics 도출 코드
def get_statistics(model, intercept=0, coef=[], train_df=None, target_df=None):
print("Coefficient :", coef)
print("Intercept :", intercept)
params = np.append(intercept, coef)
print("Params:", params)
prediction = model.predict(train_df.values.reshape(-1, 1)) # 단변량
# prediction = model.predict(train_df.values) # 다변량
if len(prediction.shape) == 1:
prediction = np.expand_dims(prediction, axis=1)
print(train_df.columns)
new_trainset = pd.DataFrame({"Constant": np.ones(len(train_df.values))}).join(pd.DataFrame(train_df.values))
print(new_trainset)
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error(prediction, target_df.values)
print("MSE :", MSE)
variance = MSE * (np.linalg.inv(np.dot(new_trainset.T, new_trainset)).diagonal()) # MSE = (1, ) & else = (n, ) 가 나와야 함.
std_error = np.sqrt(variance)
t_values = params / std_error
p_values = [2 * (1 - stats.t.cdf(np.abs(i), (len(new_trainset) - len(new_trainset.columns) - 1))) for i in t_values]
std_error = np.round(std_error, 3)
t_values = np.round(t_values, 3)
p_values = np.round(p_values, 3)
params = np.round(params, 4)
statistics = pd.DataFrame()
statistics["Coefficients"], statistics["Standard Errors"], statistics["t -values"], statistics["p-values"] = [params, std_error, t_values, p_values]
return statistics- 결과
Coefficient : [-0.3946641311768648]
Intercept : [23.81600905]
Params: [23.81600905 -0.39466413]
MultiIndex([('CRIM',)],
)
Constant 0
0 1.0 0.00632
1 1.0 0.02731
2 1.0 0.02729
3 1.0 0.03237
4 1.0 0.02985
.. ... ...
389 1.0 0.17783
390 1.0 0.22438
391 1.0 0.04527
392 1.0 0.06076
393 1.0 0.10959
[394 rows x 2 columns]
MSE : 70.2249262115713
Coefficients Standard Errors t -values p-values
0 23.8160 0.455 52.350 0.0
1 -0.3947 0.046 -8.592 0.0
Coefficients Standard Errors t -values p-values
Variables
intercept 23.8160 0.455 52.350 0.0
CRIM -0.3947 0.046 -8.592 0.0핵심은,
- 학습된 모델에
train dataset을 넣고 추론을 한다. - 새로운 dataset을 생성한다 : 1.0 상수 값과
train dataset을 horizontal concatenation 시킨 것 test dataset과 MSE(Mean Squared Error)를 구한다.- 분산(variance)을 구한다 :
1) 새로운 데이터셋 matrix와 새로운 데이터셋의 transpose matrix(전치 행렬)를 dot product(=
np.dot)
2) 위에서 구한 matrix의 역행렬(=np.linalg.inv)
3) 위에서 구한 matrix의 대각선 값(numpy.Ndarray.diagonal())
4) MSE 값과 위에서 구한 matrix의 스칼라 곱 - 각종 statistics 정보를 도출한다.
- Standard Error(std. error) : variance의 제곱근(=
np.sqrt) - t-value : 각 값들(독립변수(=columns)의 coefficient, intercept)을 각각에 대응되는 std. error로 나눈 값
- p-value : 각각의 t-value 값 들에 대해 {abs(t-value)} 과 {train dataset의 행의 개수 - train dataset의 열의 개수 - 1} 의 누적 분포 행렬(cumulative distribution function) 을 구한 후, 이 값을 1에서 뺀 후 2를 곱한 값
- Standard Error(std. error) : variance의 제곱근(=
으로 해석이 가능하다.
- 참고 1 - distribution 관련 글 : https://integratedmlai.com/normal-distribution-an-introductory-guide-to-pdf-and-cdf/
- 참고 2 - p-value 관련 글 : https://matthew-brett.github.io/teaching/on_cdfs.html
어쨋든, 위의 방식으로 statistics를 구하면
Coefficients Standard Errors t -values p-values
Variables
intercept 23.8160 0.455 52.350 0.0
CRIM -0.3947 0.046 -8.592 0.0의 정보를 얻을 수 있다.
2. statsmodels의 OLS Model
OLS 모델을 사용해서 위의 statistics를 구해보자.
- OLS 코드
import statsmodels.api as sm
import pandas as pd
X_name = ["CRIM"]
# X_name = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT"]
Y_name = "MEDV"
df = pd.read_csv("BostonHousing_noNaN_forRegressor.csv")
df_x = df[X_name]
df_y = df[Y_name]
new_df = pd.concat([df_x, df_y], axis=1)
print(new_df.head(10))
X = df_x.values
Y = df_y.values.reshape(-1, 1)
results = sm.OLS(Y, sm.add_constant(X)).fit()
print(results.summary())- 결과
(base) bolero is in now ~/dc/ml/Regression $ python ols_test.py
CRIM MEDV
0 0.00632 24.0
1 0.02731 21.6
2 0.02729 34.7
3 0.03237 33.4
4 0.02985 28.7
5 0.14455 27.1
6 0.21124 16.5
7 0.22489 15.0
8 0.11747 18.9
9 0.09378 21.7
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.158
Model: OLS Adj. R-squared: 0.156
Method: Least Squares F-statistic: 73.44
Date: Tue, 28 Jun 2022 Prob (F-statistic): 2.41e-16
Time: 00:05:46 Log-Likelihood: -1396.6
No. Observations: 394 AIC: 2797.
Df Residuals: 392 BIC: 2805.
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 23.8160 0.456 52.217 0.000 22.919 24.713
x1 -0.3947 0.046 -8.570 0.000 -0.485 -0.304
==============================================================================
Omnibus: 108.512 Durbin-Watson: 0.802
Prob(Omnibus): 0.000 Jarque-Bera (JB): 223.979
Skew: 1.461 Prob(JB): 2.31e-49
Kurtosis: 5.260 Cond. No. 10.7
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.모델 관련 코드는 매우 단순하다.
- 데이터셋 준비
sm.OLS({target value}, sm.add_constant({train value})).fit()으로 학습summary()메소드로 결과표 출력
결과는 OLS 쪽이 더 자세하게 보여주긴 한다.
여러 값들을 자동으로 구해주는데, 일단 coefficient, std. error, t-value, p-value를 우선적으로 살펴보자.
3. 비교
statistics 정보만 따로 보도록 하자.
- Scikit learn의 statistics
Coefficients Standard Errors t -values p-values
Variables
intercept 23.8160 0.455 52.350 0.0
CRIM -0.3947 0.046 -8.592 0.0- OLS의 statistics
========================================================
coef std err t P>|t|
--------------------------------------------------------
const 23.8160 0.456 52.217 0.000
x1 -0.3947 0.046 -8.570 0.000
========================================================t-value에서 어느 정도의 차이는 있는 것 같지만, 뭐...비슷한 수준인 것 같다.
단변량이라서 p-value에 대한 검증이 조금 어려운 것 같은데, 이번엔 다변량으로 넘어가보자.
4. 다변량
Scikit learn부터 살펴보자.
이전의 단변량과 비교해서, 다변량일 때는 reshape(-1, 1) 의 코드가 사라진다는 점이다.
- Scikit learn Linear Regression(전체)
from scipy import stats
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
def get_statistics(model, intercept=0, coef=[], train_df=None, target_df=None):
print("Coefficient :", coef)
print("Intercept :", intercept)
params = np.append(intercept, coef)
print("Params:", params)
# prediction = model.predict(train_df.values.reshape(-1, 1)) # 단변량
prediction = model.predict(train_df.values) # 다변량
if len(prediction.shape) == 1:
prediction = np.expand_dims(prediction, axis=1)
print(train_df.columns)
new_trainset = pd.DataFrame({"Constant": np.ones(len(train_df.values))}).join(pd.DataFrame(train_df.values))
print(new_trainset)
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error(prediction, target_df.values)
print("MSE :", MSE)
variance = MSE * (np.linalg.inv(np.dot(new_trainset.T, new_trainset)).diagonal()) # MSE = (1, ) & else = (n, ) 가 나와야 함.
std_error = np.sqrt(variance)
t_values = params / std_error
p_values = [2 * (1 - stats.t.cdf(np.abs(i), (len(new_trainset) - len(new_trainset.columns) - 1))) for i in t_values]
std_error = np.round(std_error, 3)
t_values = np.round(t_values, 3)
p_values = np.round(p_values, 3)
params = np.round(params, 4)
statistics = pd.DataFrame()
statistics["Coefficients"], statistics["Standard Errors"], statistics["t -values"], statistics["p-values"] = [params, std_error, t_values, p_values]
return statistics
if __name__ == "__main__":
# X_name = ["CRIM"]
X_name = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT"]
Y_name = ["MEDV"]
model = LinearRegression(fit_intercept=True)
df = pd.read_csv("BostonHousing_noNaN_forRegressor.csv")
print("Dataset - Total CSV Dataframe")
print(df)
df_x = df[X_name]
df_y = df[Y_name]
df_x.columns = [X_name]
df_y.columns = [Y_name]
print("Dataset - CSV X value")
print(df_x)
print("Dataset - CSV Y value")
print(df_y, "\n\n")
# model.fit(df_x.values.reshape(-1,1), df_y.values) # 단변량
model.fit(df_x.values, df_y.values) # 다변량
_coef = model.coef_
if len(_coef.shape) == 1:
_coef = np.expand_dims(_coef, axis=-1)
coef_list = []
for index in range(0, _coef.shape[0]):
for elem in range(0, _coef.shape[1]):
coef_list.append(float(_coef[index][elem]))
_intercept = model.intercept_
statistics_df = get_statistics(model=model, intercept=_intercept, coef=coef_list, train_df=df_x, target_df=df_y)
print(statistics_df)
variables = ['intercept', *X_name]
variables_df = pd.DataFrame(variables, columns=['Variables'])
total_df = pd.concat([variables_df, statistics_df], axis=1)
total_df = total_df.set_index("Variables")
print(total_df)# 단변량 주석과 # 다변량 주석을 달아 두었다.
- Scikit learn Linear Regression Result(전체)
(base) bolero is in now ~/dc/ml/Regression $ python linear_test.py
Dataset - Total CSV Dataframe
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT MEDV
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94 33.4
4 0.02985 0.0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21 28.7
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ...
389 0.17783 0.0 9.69 0 0.585 5.569 73.5 2.3999 6 391 19.2 395.77 15.10 17.5
390 0.22438 0.0 9.69 0 0.585 6.027 79.7 2.4982 6 391 19.2 396.90 14.33 16.8
391 0.04527 0.0 11.93 0 0.573 6.120 76.7 2.2875 1 273 21.0 396.90 9.08 20.6
392 0.06076 0.0 11.93 0 0.573 6.976 91.0 2.1675 1 273 21.0 396.90 5.64 23.9
393 0.10959 0.0 11.93 0 0.573 6.794 89.3 2.3889 1 273 21.0 393.45 6.48 22.0
[394 rows x 14 columns]
Dataset - CSV X value
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94
4 0.02985 0.0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21
.. ... ... ... ... ... ... ... ... .. ... ... ... ...
389 0.17783 0.0 9.69 0 0.585 5.569 73.5 2.3999 6 391 19.2 395.77 15.10
390 0.22438 0.0 9.69 0 0.585 6.027 79.7 2.4982 6 391 19.2 396.90 14.33
391 0.04527 0.0 11.93 0 0.573 6.120 76.7 2.2875 1 273 21.0 396.90 9.08
392 0.06076 0.0 11.93 0 0.573 6.976 91.0 2.1675 1 273 21.0 396.90 5.64
393 0.10959 0.0 11.93 0 0.573 6.794 89.3 2.3889 1 273 21.0 393.45 6.48
[394 rows x 13 columns]
Dataset - CSV Y value
MEDV
0 24.0
1 21.6
2 34.7
3 33.4
4 28.7
.. ...
389 17.5
390 16.8
391 20.6
392 23.9
393 22.0
[394 rows x 1 columns]
Coefficient : [-0.09759376446701587, 0.048904930612895914, 0.03037898143370697, 2.7693781109112168, -17.96902816902082, 4.283251948069779, -0.012990765807008777, -1.4585099717226637, 0.285865616987649, -0.013146415445242143, -0.9145824151981005, 0.009655741444890382, -0.4236607458756334]
Intercept : [32.68005854]
Params: [ 3.26800585e+01 -9.75937645e-02 4.89049306e-02 3.03789814e-02
2.76937811e+00 -1.79690282e+01 4.28325195e+00 -1.29907658e-02
-1.45850997e+00 2.85865617e-01 -1.31464154e-02 -9.14582415e-01
9.65574144e-03 -4.23660746e-01]
MultiIndex([( 'CRIM',),
( 'ZN',),
( 'INDUS',),
( 'CHAS',),
( 'NOX',),
( 'RM',),
( 'AGE',),
( 'DIS',),
( 'RAD',),
( 'TAX',),
('PTRATIO',),
( 'B',),
( 'LSTAT',)],
)
Constant 0 1 2 3 4 5 6 7 8 9 10 11 12
0 1.0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98
1 1.0 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14
2 1.0 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03
3 1.0 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94
4 1.0 0.02985 0.0 2.18 0.0 0.458 6.430 58.7 6.0622 3.0 222.0 18.7 394.12 5.21
.. ... ... ... ... ... ... ... ... ... ... ... ... ... ...
389 1.0 0.17783 0.0 9.69 0.0 0.585 5.569 73.5 2.3999 6.0 391.0 19.2 395.77 15.10
390 1.0 0.22438 0.0 9.69 0.0 0.585 6.027 79.7 2.4982 6.0 391.0 19.2 396.90 14.33
391 1.0 0.04527 0.0 11.93 0.0 0.573 6.120 76.7 2.2875 1.0 273.0 21.0 396.90 9.08
392 1.0 0.06076 0.0 11.93 0.0 0.573 6.976 91.0 2.1675 1.0 273.0 21.0 396.90 5.64
393 1.0 0.10959 0.0 11.93 0.0 0.573 6.794 89.3 2.3889 1.0 273.0 21.0 393.45 6.48
[394 rows x 14 columns]
MSE : 19.418397930734912
Coefficients Standard Errors t -values p-values
0 32.6801 5.579 5.857 0.000
1 -0.0976 0.032 -3.062 0.002
2 0.0489 0.014 3.459 0.001
3 0.0304 0.065 0.469 0.639
4 2.7694 0.909 3.048 0.002
5 -17.9690 4.167 -4.312 0.000
6 4.2833 0.462 9.266 0.000
7 -0.0130 0.014 -0.915 0.361
8 -1.4585 0.207 -7.038 0.000
9 0.2859 0.068 4.200 0.000
10 -0.0131 0.004 -3.384 0.001
11 -0.9146 0.138 -6.624 0.000
12 0.0097 0.003 3.311 0.001
13 -0.4237 0.054 -7.840 0.000
Coefficients Standard Errors t -values p-values
Variables
intercept 32.6801 5.579 5.857 0.000
CRIM -0.0976 0.032 -3.062 0.002
ZN 0.0489 0.014 3.459 0.001
INDUS 0.0304 0.065 0.469 0.639
CHAS 2.7694 0.909 3.048 0.002
NOX -17.9690 4.167 -4.312 0.000
RM 4.2833 0.462 9.266 0.000
AGE -0.0130 0.014 -0.915 0.361
DIS -1.4585 0.207 -7.038 0.000
RAD 0.2859 0.068 4.200 0.000
TAX -0.0131 0.004 -3.384 0.001
PTRATIO -0.9146 0.138 -6.624 0.000
B 0.0097 0.003 3.311 0.001
LSTAT -0.4237 0.054 -7.840 0.000이번엔 OLS Model의 코드이다.
- OLS Model Code(전체)
# from statsmodels.formula.api import ols as OLS
import statsmodels.api as sm
import pandas as pd
# X_name = ["CRIM"]
X_name = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT"]
Y_name = "MEDV"
df = pd.read_csv("BostonHousing_noNaN_forRegressor.csv")
df_x = df[X_name]
df_y = df[Y_name]
new_df = pd.concat([df_x, df_y], axis=1)
print(new_df.head(10))
X = df_x.values
Y = df_y.values.reshape(-1, 1)
results = sm.OLS(Y, sm.add_constant(X)).fit()
print(results.summary())- OLS Model Result(전체)
(base) bolero is in now ~/dc/ml/Regression $ python ols_test.py
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT MEDV
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94 33.4
4 0.02985 0.0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21 28.7
5 0.14455 12.5 7.87 0 0.524 6.172 96.1 5.9505 5 311 15.2 396.90 19.15 27.1
6 0.21124 12.5 7.87 0 0.524 5.631 100.0 6.0821 5 311 15.2 386.63 29.93 16.5
7 0.22489 12.5 7.87 0 0.524 6.377 94.3 6.3467 5 311 15.2 392.52 20.45 15.0
8 0.11747 12.5 7.87 0 0.524 6.009 82.9 6.2267 5 311 15.2 396.90 13.27 18.9
9 0.09378 12.5 7.87 0 0.524 5.889 39.0 5.4509 5 311 15.2 390.50 15.71 21.7
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.767
Model: OLS Adj. R-squared: 0.759
Method: Least Squares F-statistic: 96.29
Date: Tue, 28 Jun 2022 Prob (F-statistic): 1.75e-111
Time: 00:21:55 Log-Likelihood: -1143.4
No. Observations: 394 AIC: 2315.
Df Residuals: 380 BIC: 2370.
Df Model: 13
Covariance Type: nonrobust
==============================================================================
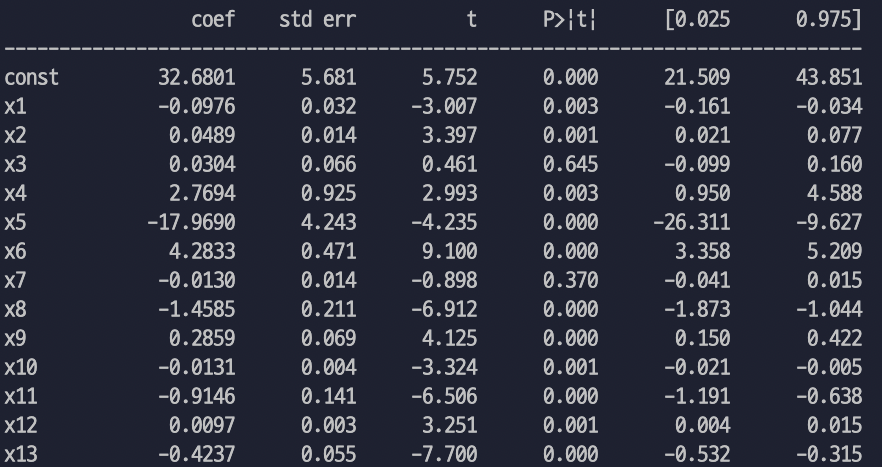
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 32.6801 5.681 5.752 0.000 21.509 43.851
x1 -0.0976 0.032 -3.007 0.003 -0.161 -0.034
x2 0.0489 0.014 3.397 0.001 0.021 0.077
x3 0.0304 0.066 0.461 0.645 -0.099 0.160
x4 2.7694 0.925 2.993 0.003 0.950 4.588
x5 -17.9690 4.243 -4.235 0.000 -26.311 -9.627
x6 4.2833 0.471 9.100 0.000 3.358 5.209
x7 -0.0130 0.014 -0.898 0.370 -0.041 0.015
x8 -1.4585 0.211 -6.912 0.000 -1.873 -1.044
x9 0.2859 0.069 4.125 0.000 0.150 0.422
x10 -0.0131 0.004 -3.324 0.001 -0.021 -0.005
x11 -0.9146 0.141 -6.506 0.000 -1.191 -0.638
x12 0.0097 0.003 3.251 0.001 0.004 0.015
x13 -0.4237 0.055 -7.700 0.000 -0.532 -0.315
==============================================================================
Omnibus: 161.243 Durbin-Watson: 1.247
Prob(Omnibus): 0.000 Jarque-Bera (JB): 904.814
Skew: 1.657 Prob(JB): 3.33e-197
Kurtosis: 9.643 Cond. No. 1.57e+04
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.57e+04. This might indicate that there are
strong multicollinearity or other numerical problems.statistics 부분만 잘라서 보자.
1) Scikit learn
Coefficients Standard Errors t -values p-values
Variables
intercept 32.6801 5.579 5.857 0.000
CRIM -0.0976 0.032 -3.062 0.002
ZN 0.0489 0.014 3.459 0.001
INDUS 0.0304 0.065 0.469 0.639
CHAS 2.7694 0.909 3.048 0.002
NOX -17.9690 4.167 -4.312 0.000
RM 4.2833 0.462 9.266 0.000
AGE -0.0130 0.014 -0.915 0.361
DIS -1.4585 0.207 -7.038 0.000
RAD 0.2859 0.068 4.200 0.000
TAX -0.0131 0.004 -3.384 0.001
PTRATIO -0.9146 0.138 -6.624 0.000
B 0.0097 0.003 3.311 0.001
LSTAT -0.4237 0.054 -7.840 0.0002) OLS Model
=======================================================
coef std err t P>|t|
-------------------------------------------------------
const 32.6801 5.681 5.752 0.000
x1 -0.0976 0.032 -3.007 0.003
x2 0.0489 0.014 3.397 0.001
x3 0.0304 0.066 0.461 0.645
x4 2.7694 0.925 2.993 0.003
x5 -17.9690 4.243 -4.235 0.000
x6 4.2833 0.471 9.100 0.000
x7 -0.0130 0.014 -0.898 0.370
x8 -1.4585 0.211 -6.912 0.000
x9 0.2859 0.069 4.125 0.000
x10 -0.0131 0.004 -3.324 0.001
x11 -0.9146 0.141 -6.506 0.000
x12 0.0097 0.003 3.251 0.001
x13 -0.4237 0.055 -7.700 0.000
=======================================================const 는 intercept를 의미하고,
x1~x13은 학습에 사용된 변수들 (=["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX", "PTRATIO", "B", "LSTAT"]) 13개를 의미한다.
p-value만 따로 놓고 보자.
| variables | Scikit-Learn | OLS |
|---|---|---|
| const(=intercept) | 0.000 | 0.000 |
| CRIM | 0.002 | 0.003 |
| ZN | 0.001 | 0.001 |
| INDUS | 0.639 | 0.645 |
| CHAS | 0.002 | 0.003 |
| NOX | 0.000 | 0.000 |
| RM | 0.000 | 0.000 |
| AGE | 0.361 | 0.370 |
| DIS | 0.000 | 0.000 |
| RAD | 0.000 | 0.000 |
| TAX | 0.001 | 0.001 |
| PTRATIO | 0.000 | 0.000 |
| B | 0.001 | 0.001 |
| LSTAT | 0.000 | 0.000 |
어느정도 비슷한 느낌은 있는데, 아주 미세하게 조금씩 값이 다른 느낌이다...
이 부분은 추후 검색 등으로 해결할 필요가 있어 보인다.
내 추측으로는, 마지막에 np.round 함수로 소수점 3번째 자리까지 잘라버리는데, 여기서 오는 값 손실인 것 같다.
