-
Decision Tree
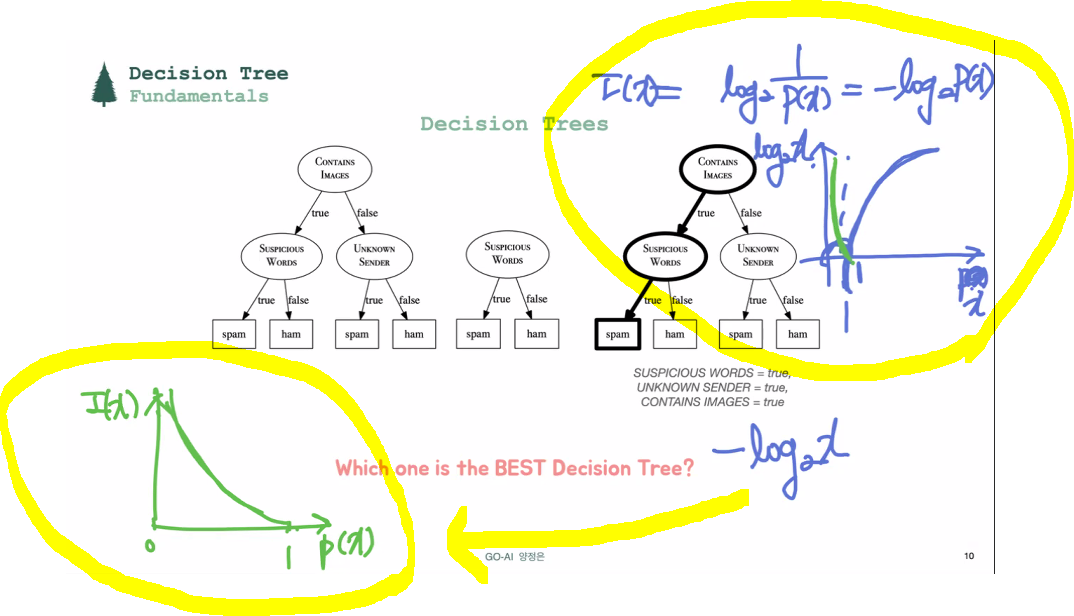
root node에서 선택되는 feature가 뭔지에 따라 깊이가 달라짐(tree 길이). 어떤 피쳐를 가장 먼저 쓰느냐가 depth를 결정하는 큰 요소.
가장 중요한것: root node에서 어떤 descriptive feature 사용하느냐. -
Entropy:

불확실성을 판단하는 척도
엔트로피가 클수록 불확실성이 높은것.
*정보량이 크다: 일어나는 빈도수가 작은 정보
of surprise??
I(x) = log21/p(x) = -log2p(x)
- Impurity Metrics
impurity, heterogineity의 측정
decision tree의 분기는 impurity가 작은 방향으로 진행된다.

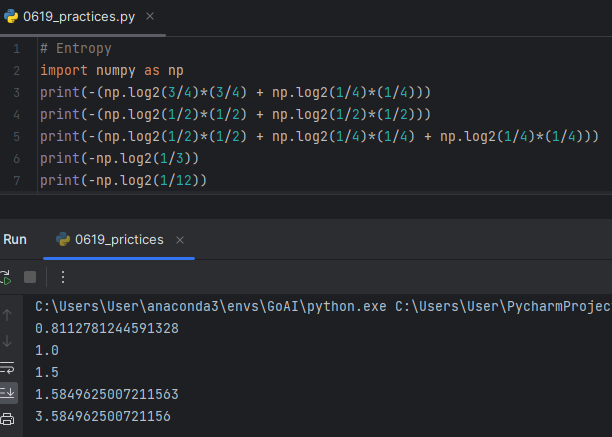
가지치고 나간 데이터셋에 가중치(weighting) 부여
- information gain
클수록 인포메이션 게인이 크게 작용했다는 것이니까.
탑다운으로 적용이 됨
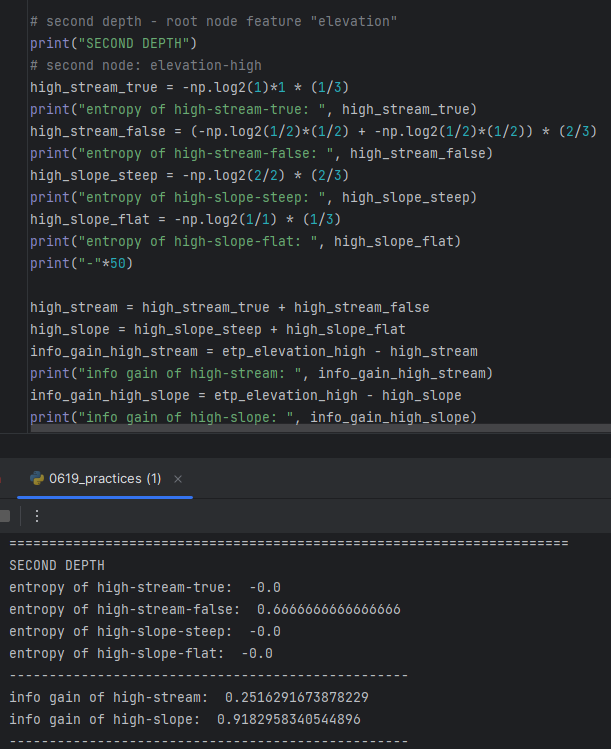
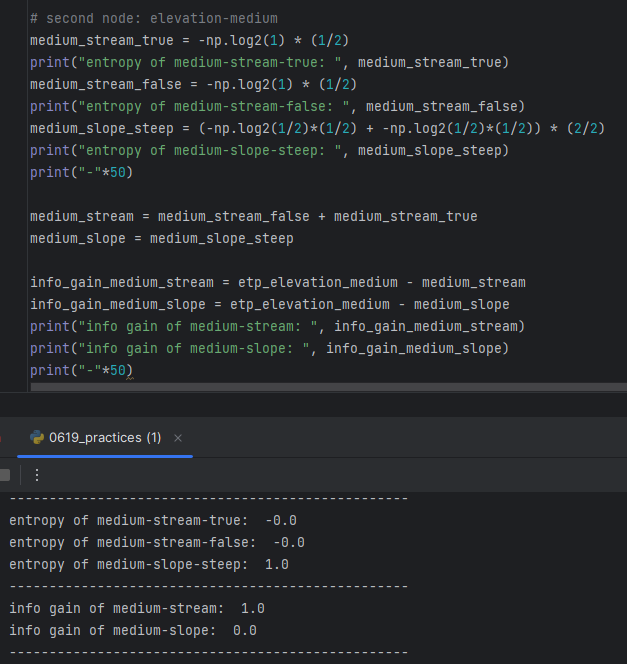
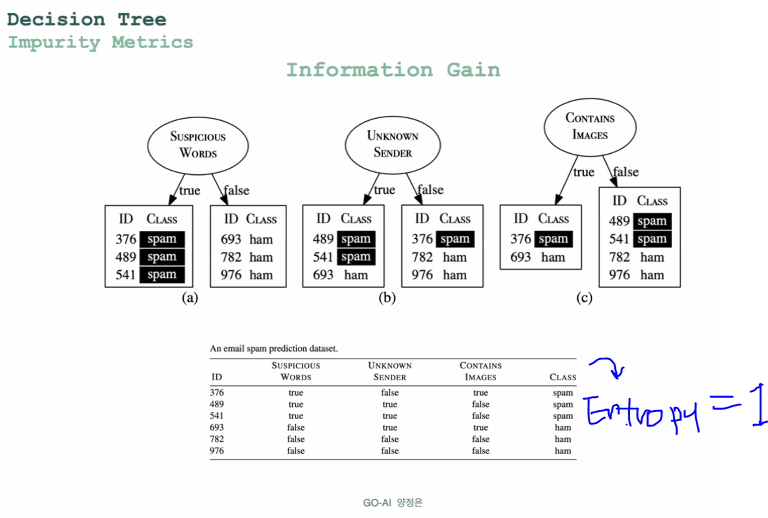 -> Entropy of Original dataset is 1.
-> Entropy of Original dataset is 1.
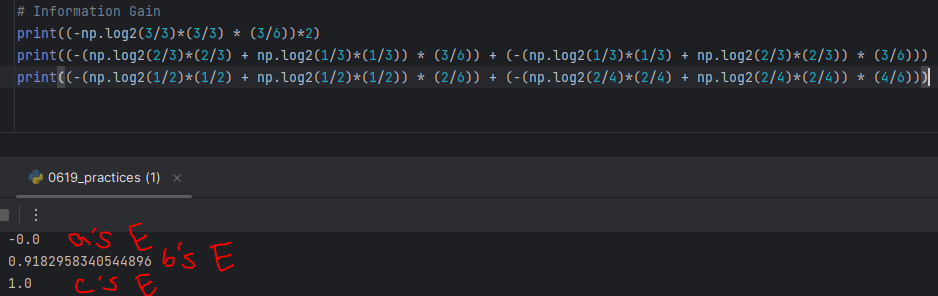 -> a's E = Entropy after dataset classified with "Suspicious Words" as Root Node = -0.0
-> a's E = Entropy after dataset classified with "Suspicious Words" as Root Node = -0.0
b's E = Entropy after dataset classified with "Unknown Sender" as Root Node = 0.9182958340544896
c's E = Entropy after dataset classified with "Contains Images" as Root Node = 1.0
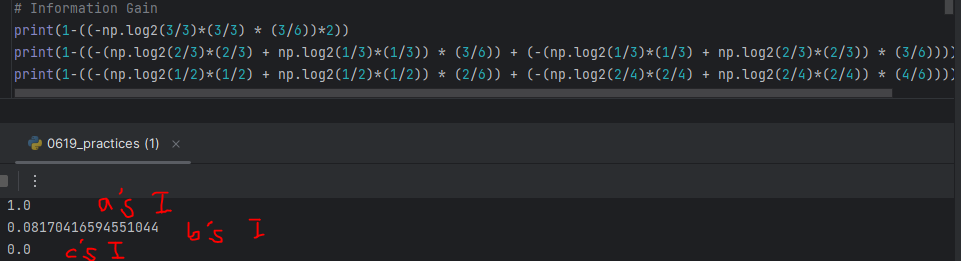 -> a's I = Entropy of Original Dataset - a's E
-> a's I = Entropy of Original Dataset - a's E
b's I = Entropy of Original Dataset - b's E
c's I = Entropy of Original Dataset - c's E
- ID3 Algorithm
*Iterative Dichotomizer3
CART
Entropy based I.
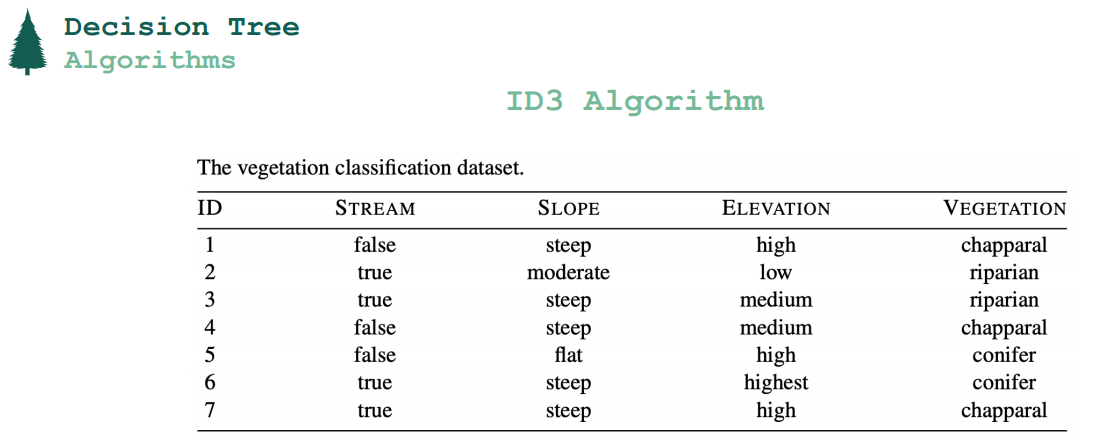
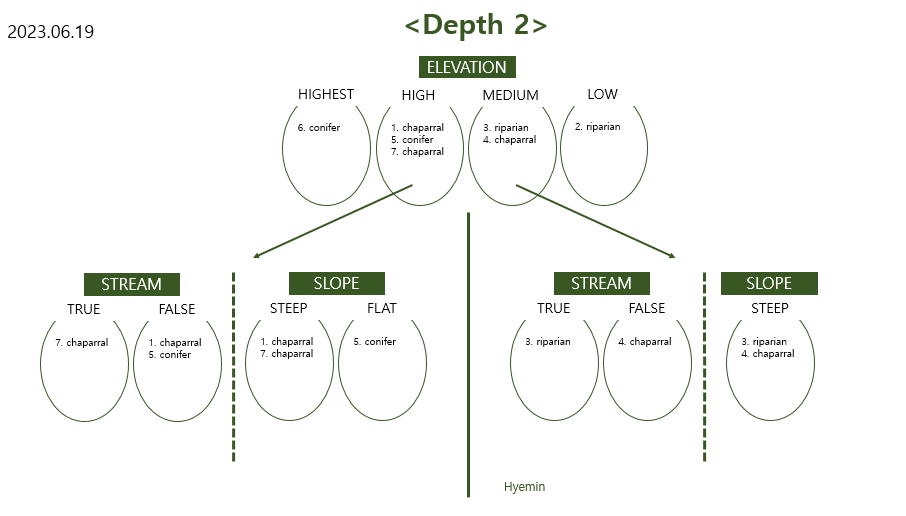
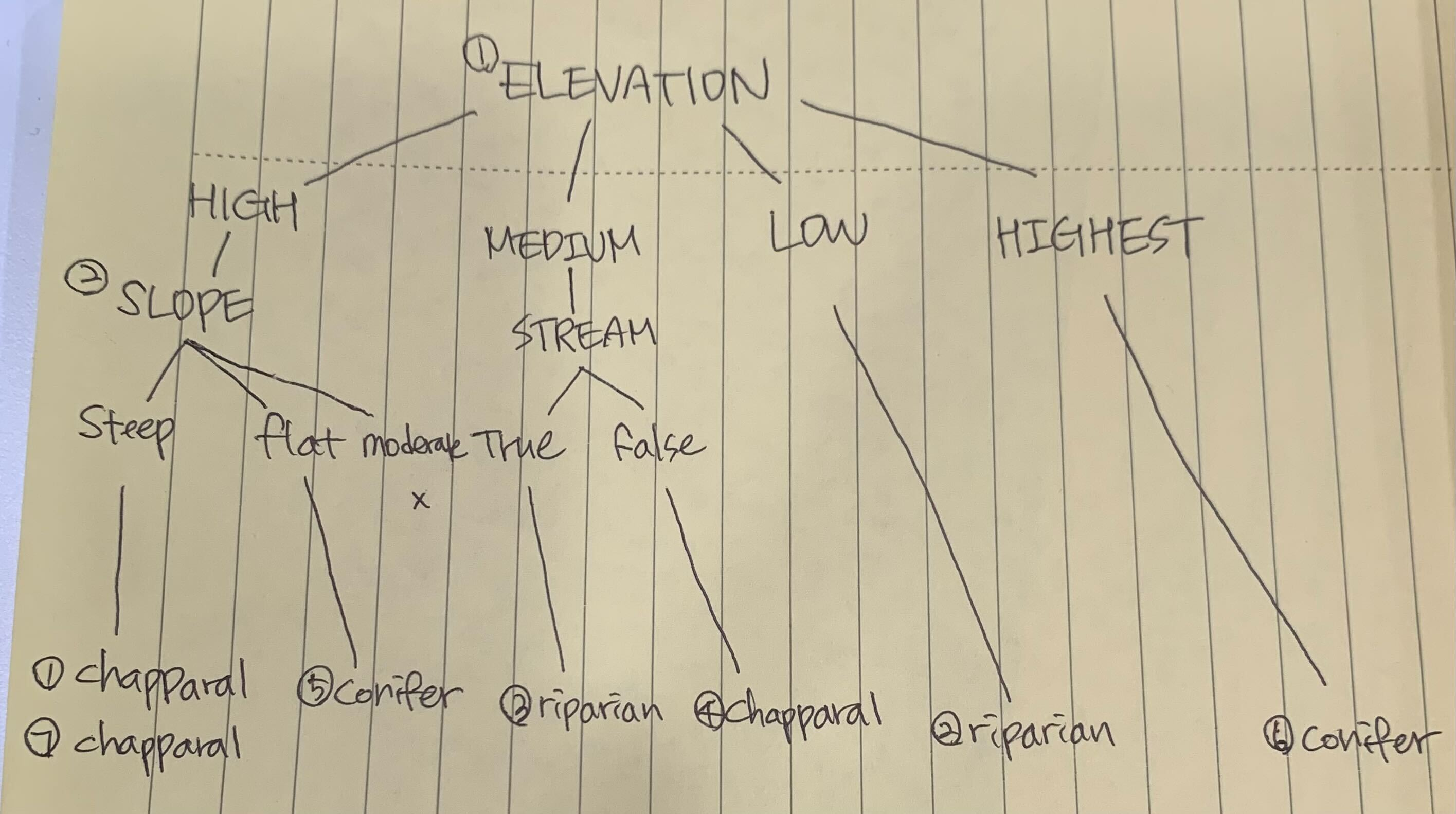
<Deciding which desriptive feature should be used as the Root Node>
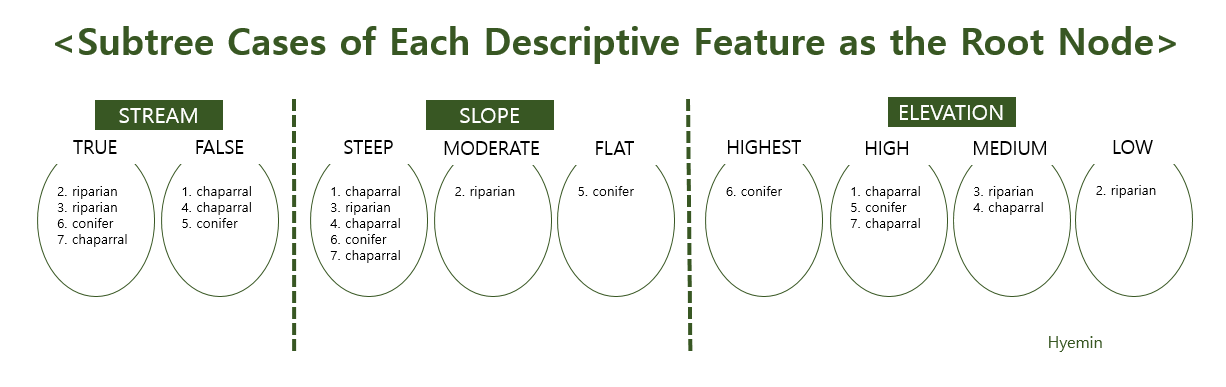
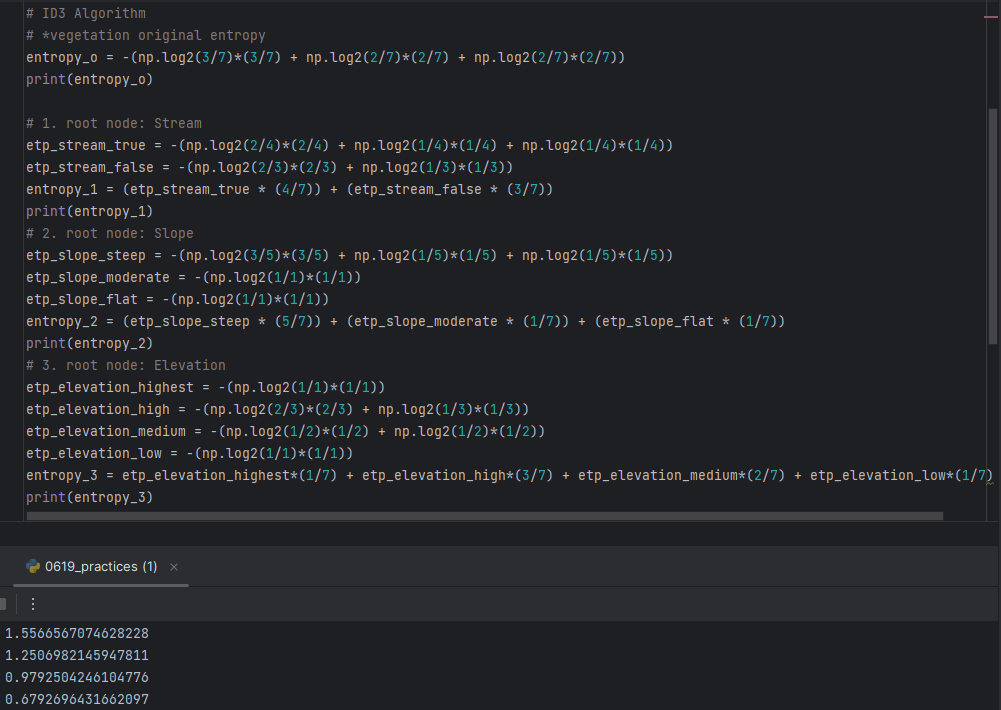
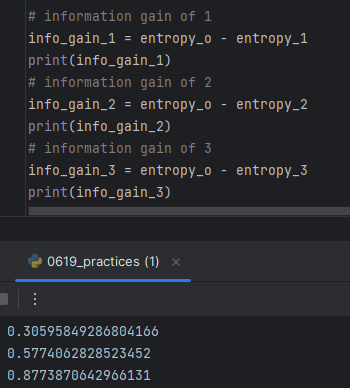
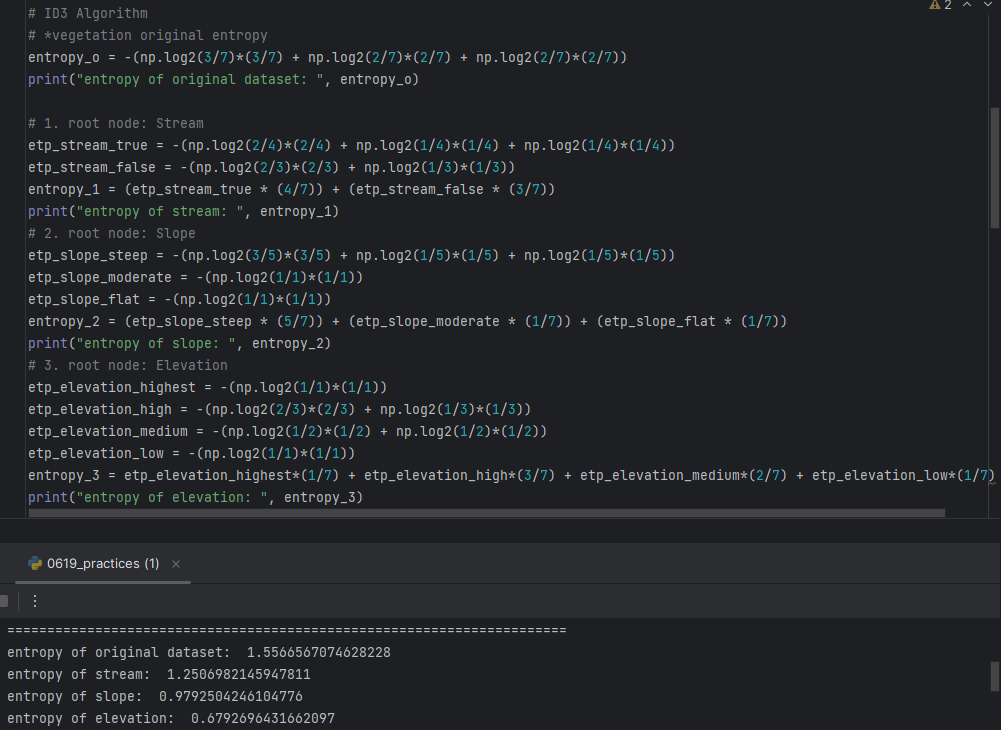
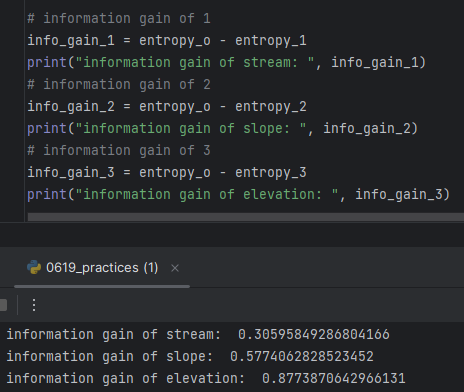
-> Choosing Elevation since it has smallest information gain
<Deciding which desriptive feature should be used as the First Interior Node>