Naver API
- 네이버, 페이스북, 구글 등 IT의 거대 기업들부터 많은 S/W관련 회사들이 자사 제품을 사용하는 것에 대해 API를 제공한다
- 특히 요즘처럼 웹크롤링에 대한 방어가 점점 심해지는 이때 해당 회사의 + API를 사용하는 것이 오히려 더 바람직할 수 있다
- 사용하는 서비스마다 에러코드가 조금씩 다르므로 잘 확인하자
- 정보를 어떻게 얻을 것인가는 크게 xml과 json, 2가지로 나뉜다
Naver API 등록
- 네이버 API: https://developers.naver.com/main/
- Open API 신청
- 발급된 Client ID, Secret으로 API 연동시키기
Naver API 사용하기
-
개발자 가이드
https://developers.naver.com/docs/serviceapi/search/blog/blog.md#%EB%B8%94%EB%A1%9C%EA%B7%B8 -
네이버 검색
- urllib : http 프로토콜에 따라 서버 요청/응답 처리를 위한 모듈
- urllib.request : 클라이언트의 요청을 처리하는 모듈
- urllib.parse : url주소에 대한 분석
- url : https://openapi.naver.com/v1/search/옵션 으로 연결
- node : blog, book, movie, cafearticle, shop, encyc 등
- type : .json, .xml
- ?query : 검색할 문자(열)
- &start : 데이터를 추출한 시작 번호
- &display : 데이터 결과 출력 건수
# 네이버 검색 Open API 예제 - 책 검색
import os
import sys
import urllib
import urllib.request
client_id = "개인id"
client_secret = "개인secret"
# url 처리
encText = urllib.parse.quote("파이썬")
# 책
url = "https://openapi.naver.com/v1/search/book?query=" + encText # json 결과
# 이 주소가 네이버 블로그 검색 결과를 가져오는 주소이다
# url = "https://openapi.naver.com/v1/search/book.xml?query=" + encText # xml 결과
# request 요청 처리
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
# 응답 결과 respose에 저장
response = urllib.request.urlopen(request)
# getcode() : 상태 코드 확인
# 에러는 에러코드 페이지가 있다.
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)# response, 상태코드
response, response.getcode(), response.code, response.status
# 글자로 읽을 경우, decode utf-8 설정
response_body.decode('utf-8')[:500]- 결과 확인 : 결과 확인을 위해 decode를 해줘야함
Naver API에서 모은 '몰스킨' 데이터 정리 및 시각화
- 순서
gen_search_url(generate url) # 검색url을 만드는 함수
-> get_result_onpage(Get data on one page) # 그 결과를 저장하는 함수
-> get_fields(Convert pandas data frame) # 데이터 프레임으로 저장하는 함수
-> actMain(All Data Gathering) # 앞서 만들었던 함수들을 실행하면서 데이터를 수집하는 함수
-> toExcel(Export to Excel) # 최종적으로 엑셀로 저장하는 함수gen_search_url
- 검색해야할 URL 만들기
- 많은 옵션이 있는데 요청 변수들을 URL에 포함시켜야 한다
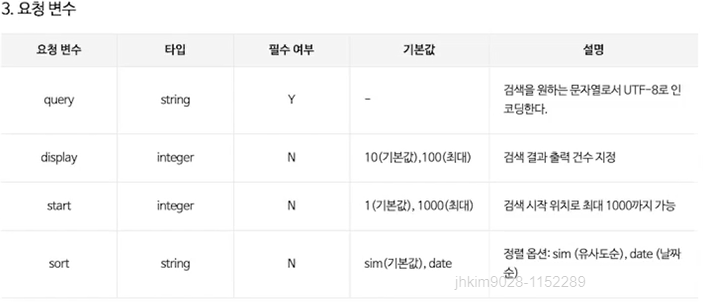
- URL 생성 함수
def gen_search_url(api_node, search_text, start_num, disp_num):
base = 'https://openapi.naver.com/v1/search'
node = '/' + api_node + '.json'
param_query = '?query=' + urllib.parse.quote(search_text)
param_start = '&start=' + str(start_num)
param_disp = '&display=' + str(disp_num)
return base + node + param_query + param_start + param_disp
gen_search_url('shop','TEST',10,3)
get_result_onpage
- 결과 출력 함수
import json
import datetime
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header('X-Naver-Client-Id',client_id)
request.add_header('X-Naver-Client-Secret',client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Success" % datetime.datetime.now())
return json.loads(response.read().decode('utf-8'))
client_id = "V3yqprhwuJO0K3T1kanM"
client_secret = "QQ959I7cLA"
url = gen_search_url('shop','몰스킨',1,5)
one_result = get_result_onpage(url)
one_result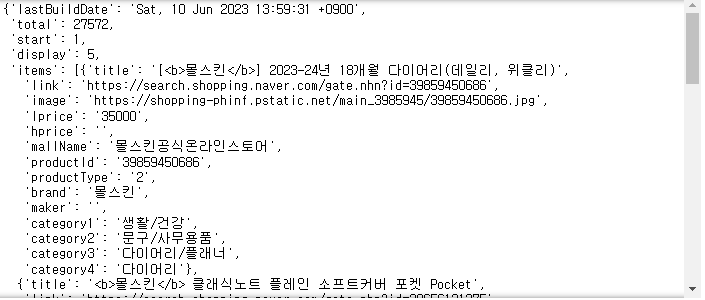
get_fields
def delete_tag(input_str):
input_str = input_str.replace('<b>','')
input_str = input_str.replace('</b>','')
return input_str- 태그 삭제 함수
그냥 하면 html 태그가 포함되기 때문
import pandas as pd
def get_fields(json_data):
title = [delete_tag(each['title']) for each in json_data['items']]
link = [each['link'] for each in json_data['items']]
lprice = [each['lprice'] for each in json_data['items']]
mall_name = [each['mallName'] for each in json_data['items']]
result_pd = pd.DataFrame({
'title':title,
'lprice':lprice,
'link': link,
'mall': mall_name
}, columns = ['title','lprice','link','mall'])
return result_pd
get_fields(one_result)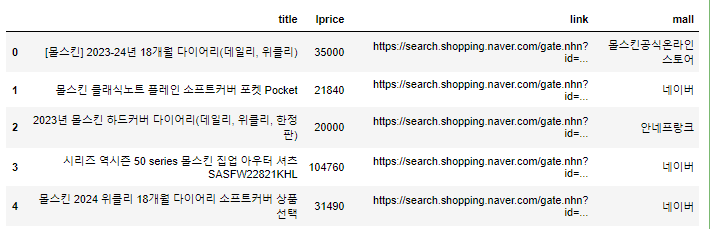
- 속성 추출 함수
- 위에서 가져온 데이터 중에 얻어오고 싶은 데이터: 가격정보, 상품 이름, 파는 곳, 링크
actMain
result_mol = []
for n in range(1,1000,100):
url = gen_search_url('shop','몰스킨',n,100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
- 반복문을 통해 데이터 추출
result_mol = pd.concat(result_mol)
result_mol.reset_index(drop=True,inplace=True)
result_mol['lprice'] = result_mol['lprice'].astype('float')
result_mol.info()- 데이터 정리
-reset index
-price 데이터 타입 변경
toExcel
- 설치
pip install xlsxwriter# 저장
writer = pd.ExcelWriter("../data/06/06. python_in_naver_shop.xlsx", engine='xlsxwriter')
result_book.to_excel(writer, sheet_name="Sheet1")
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
# 각 셀의 간격(크기) 조절
worksheet.set_column("A:A", 4) # A컬럼 4칸으로 간격(크기) 조정
worksheet.set_column("B:B", 60) # B컬럼 60칸으로 간격(크기) 조정
worksheet.set_column("C:C", 10) # C컬럼 10칸으로 간격(크기) 조정
worksheet.set_column("D:D", 10) # D컬럼 10칸으로 간격(크기) 조정
worksheet.set_column("E:E", 10) # E컬럼 50칸으로 간격(크기) 조정
worksheet.set_column("F:F", 20) # F컬럼 10칸으로 간격(크기) 조정
worksheet.set_column("G:G", 10) # F컬럼 10칸으로 간격(크기) 조정
worksheet.conditional_format("D2:D501D", {"type" : "3_color_scale"})
writer.save()엑셀에서 색상으로 가격대를 한눈에 알아볼 수 있음
- ExcelWriter : 엑셀 작업을 파이썬 코드로 작성
- set_column : 컬럼 간격(크기) 조절
- conditional_format : 조건에 따라 스타일 적용
- save : 저장
데이터 시각화
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
rc('font',family='Malgun Gothic')
%matplotlib inline
plt.figure(figsize=(15,6))
sns.countplot(
x=result_mol['mall'],
data=result_mol,
palette='RdYlGn',
order=result_mol['mall'].value_counts().index
)
plt.xticks(rotation=90)
plt.show()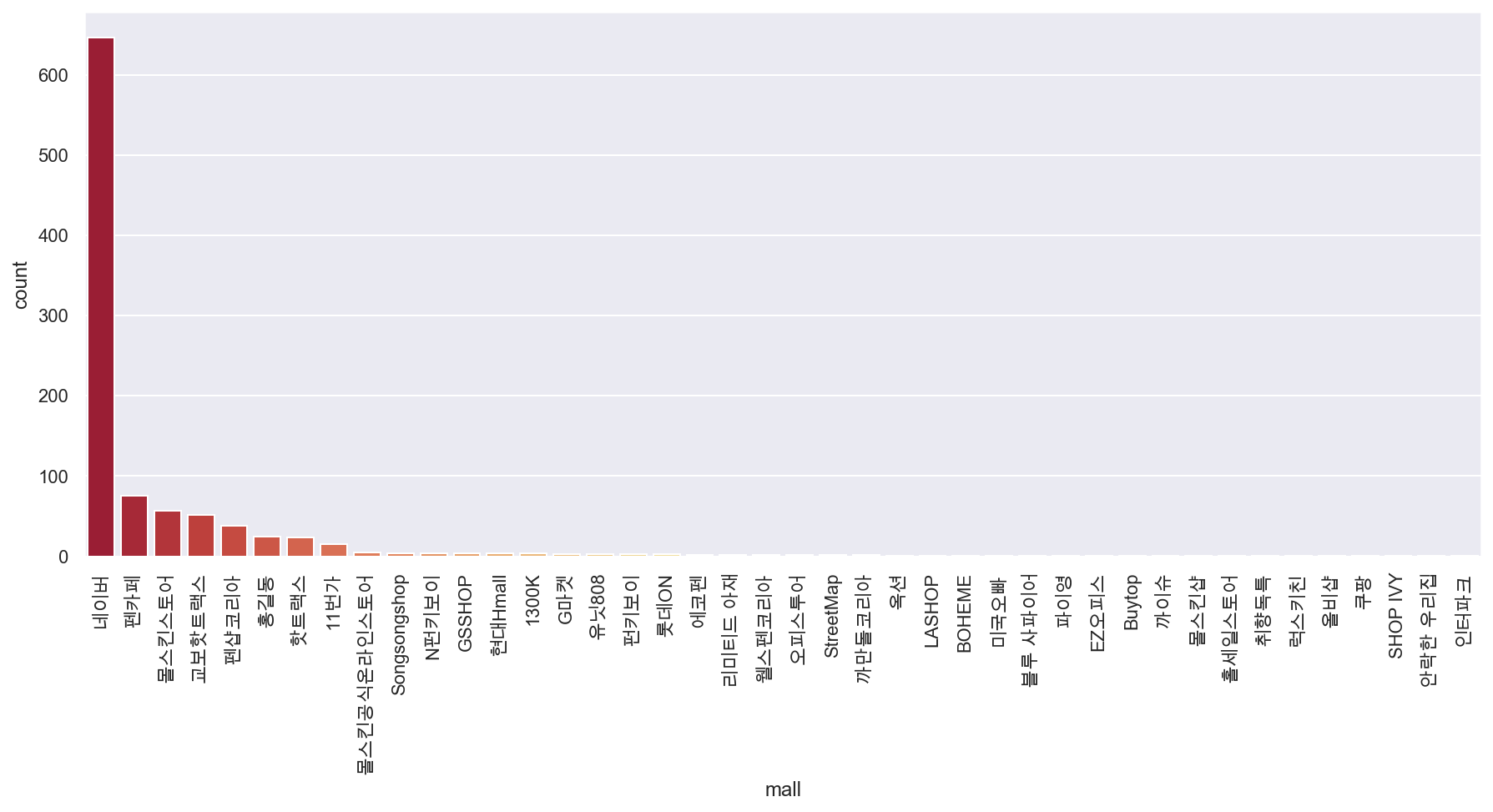
- countplot : 각 카테고리별 데이터 개수 표시

+database