워드 임베딩(word embedding)
: 단어 간의 관계를 학습해 vector에 저장하는 모델
unsupervised learning
맞춰야하는 타겟(label)이 없는 것
아무런 label 없이 이들의 특성을 종합적으로 파악해서 묶는 것
데이터를 가공할 필요없이 구글링한 텍스트만 가지고도 유용한 모델 만들기 가능
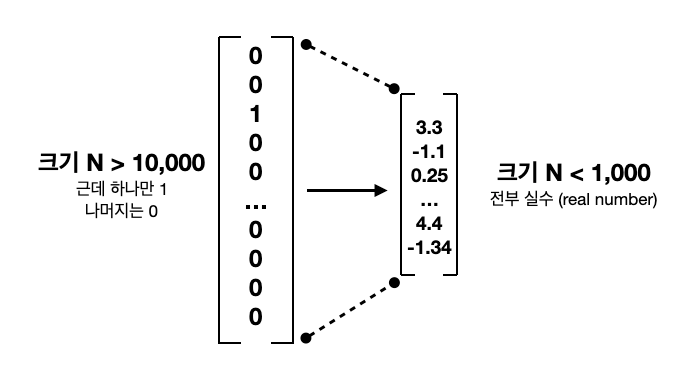
하나의 단어에 대해 차원을 최대한 낮추고, 더 적은 숫자들로 하나의 단어에 정보를 담는 것이 목표!
따라서 원-핫 벡터와 달리 row에 0이 아닌 실수로 채워져 있다.
GloVe
: 같은 문장에 한 단어가 근처 단어들과 몇 번 같이 나오는지 세어보는 것?(co-occurrence matrix)
기술
- dimensionality reduction
: 차원을 줄여주는 알고리즘
-
Singular Value Decomposition(SVD)
: 특이값 분해 알고리즘= Principle Component Analysis(PCA);주성분 분석 도 유사하니 참고로 공부해보기.
SVD : M X N 행렬만으로 이루어진 것에 사용
PCA : N X N 행렬만으로 이루어진 것에 사용 -> GloVe에서는 사용X, 이루고자 하는 큰 목표는 같다.
Singular Value Decomposition(SVD) : 특이값 분해
-
m x n 행렬에 대해 적용 가능함(정방행렬이 아니어도 적용가능)
-
모든 특이 벡터(U와 V에 속한 벡터)는 서로 직교하는 성질을 가진다.
-
∑는 대각행렬이다.
행렬의 대각에 위치한 값 + 나머지 위치의 값 모두 0이다. -
∑의 대각 원소 값이 행렬 A의 특이값(Singular Value)이다.
A의 특이값은 AAt 혹은 AtA의 고유값의 Root 값과 같다.
?? AAt의 고유값과 AtA의 고유값이 왜 같은지 증명
https://darkpgmr.tistory.com/106?category=460967
word2vec
-
neural network로 구현
-
stochastic gradient descent(SGD)로 학습 가능
-
CBOW(continuous bag-of-words) 와 skipgram 알고리즘을 통해 학습 가능
CBOW
: 주변 단어들을 모두 합쳐서 본 후 타깃 단어 맞추기
["the", "quick", "brown", "jumps", "over"]을 가지고 "fox"을 예측
skipgram
: 타깃 단어를 보고 주변 단어를 맞추기
"fox"을 가지고 "the", "quick", "brown", "jumps", "over"를 각각 예측
input-N x 1 word embedding으로 들어가 무작위 숫자고 embedding 초기화.
학습이 진행될수록 word embedding은 주변 단어들과의 관계에 대한 정보가 encoding 됨
word2vec 논문
https://proceedings.neurips.cc/paper_files/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf
이 word embedding을 통해 단어들 간의 덧셈, 뺄셈을 할 수 있다.
그리고 이 결과값을 통해 단어들의 의미적 관계(semantics)와 문법적 관계(syntactic)를 알아낼 수 있다.
