
개요
운영중인 서비스에서 매칭 시 DB 쿼리로 매칭조건을 검색하기에 이력서 데이터가 많을수록 쿼리 시간이 오래걸리는 이슈가 있었다.
이에 따라 elasticsearch에 이력서 데이터를 적재하고 조회했을때 얼마나 성능이 올라갈지에 대해 조사하게 되었다.
현재 구조는 매칭을 위한 이력서 관련 데이터를 RDB에 직접 접근하여 저장하고 있다.
처음에 생각한 구조는 elasticsearch에 직접 데이터를 전달해도 되지만
장애시 데이터 유실 등의 이슈로 Kafka와 같은 이벤트 브로커를 앞단에 두고 데이터를 받는 구조로 테스트해 보았다.
아키텍처
https://github.com/chansKim/docker-elk
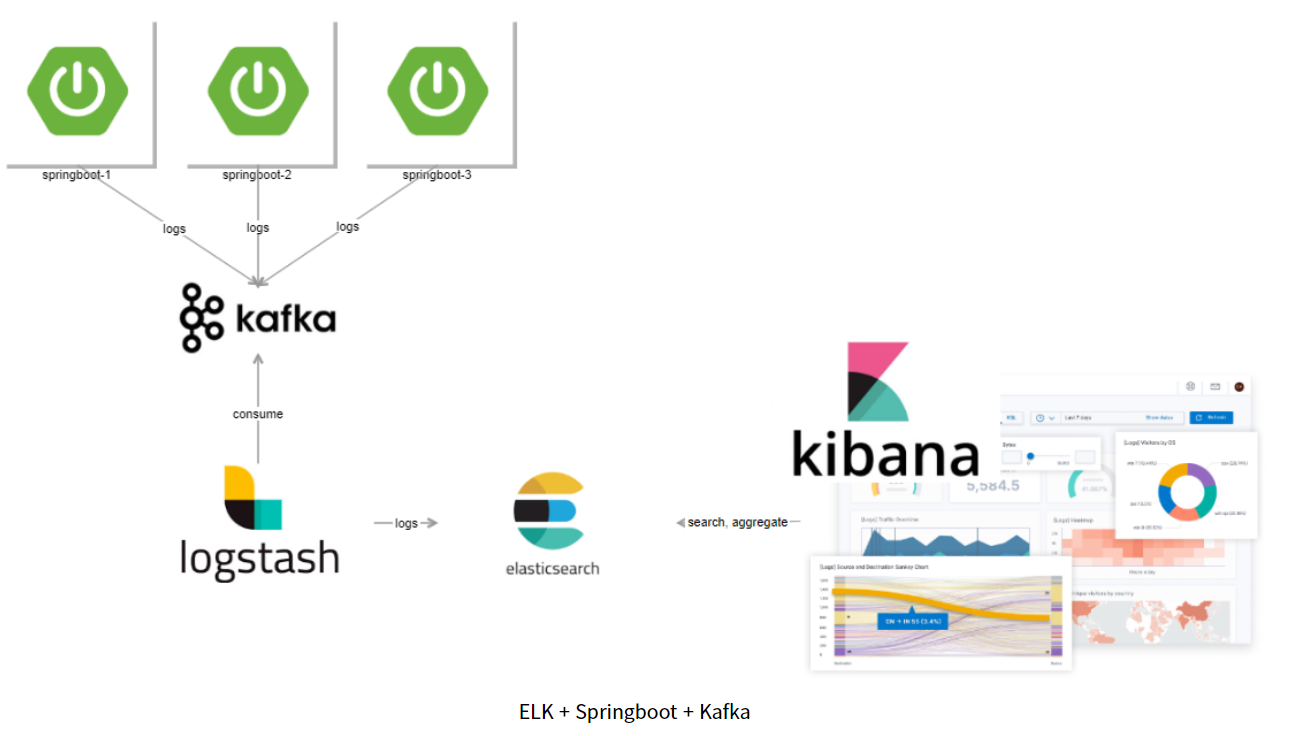
Spring WAS 1,2,3 → kafka → logstash → elasticsearch → kibana로 흘러가는 구조로
logstash의 pipeline은 아래처럼 kafka의 test-topic에서 string message만 필터링하여 elasticsearch의 날짜별로 indexing하도록 구성.
input {
kafka {
bootstrap_servers => "kafka:29092"
topics => "test-topic"
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
index => "kafka-elk-test-log-%{+YYYY.MM.dd}"
user => "elastic"
password => "$password"
}
}매칭 조건
실제 매칭 쿼리의 조건을 보면 여러가지가 있지만 크게
1. 성별
2. 최종 학력
3. 근무기간
4. 좌표범위
이 조건에 따라 elasticsearch의 검색 조건은 아래처럼 만들어 보았다.
{
"size":1000,
"query": {
"bool":{
"must": [
{
"match": {
"gender": 0 -- 성별
}
},
{"match": { "wishJobTypeCodes" : "2010" } } -- 업직종
],
"filter": [{
"bool":{
"should":[
{ "range": { "wishWorkPeriod": {"gte": "10", "lte": "40"}}}, -- 근무기간
{ "terms" : {"wishWorkPeriod": ["0"] }}
]
}
},
{ "range": { "lastEducationLevel": {"gte": "30"}}}, -- 최종 학력
{ "range": { "birthday": {"gte": "1983-05-01", "lte": "2000-05-04"}}}, -- 나이
{ "range": { "locations.katechX": {"gte": "306469", "lte": "326469"}}}, -- 좌표범위
{ "range": { "locations.katechY": {"gte": "533374", "lte": "553374"}}} -- 좌표범위
]
}
}
}마지막 로그인 3개월은 index lifecycle을 3개월로 유지하면 될거로 판단된다.
성능 검증
테스트 케이스로 아래와 같은 케이스를 생각해 보았다.
- 이력서 10만개일떄 검색 시간
- 이력서 100만개일때 검색 시간
- 이력서 500만개일때 검색 시간
- 전체 카운트 10만개
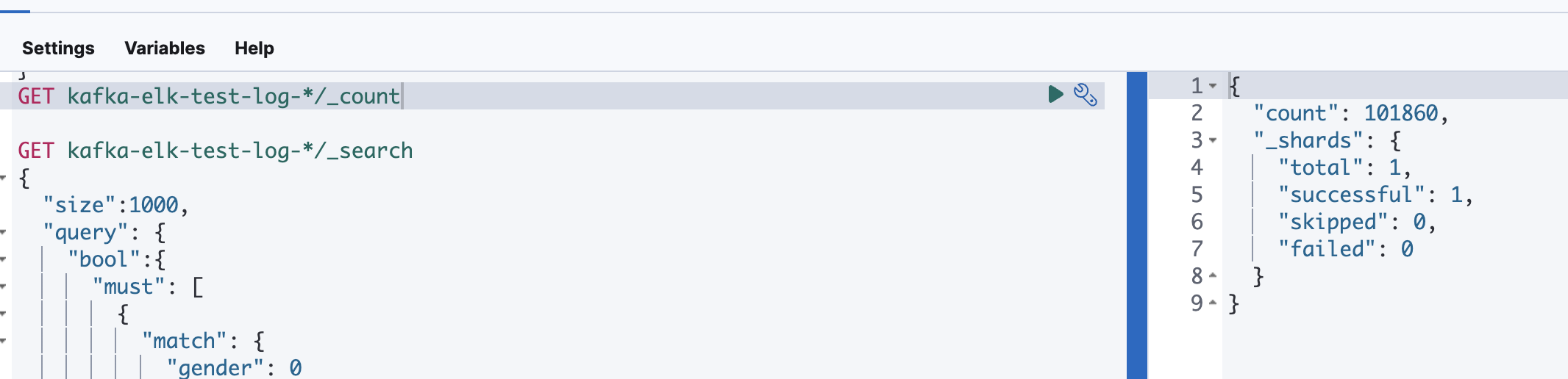
- 10만개 조건 검색
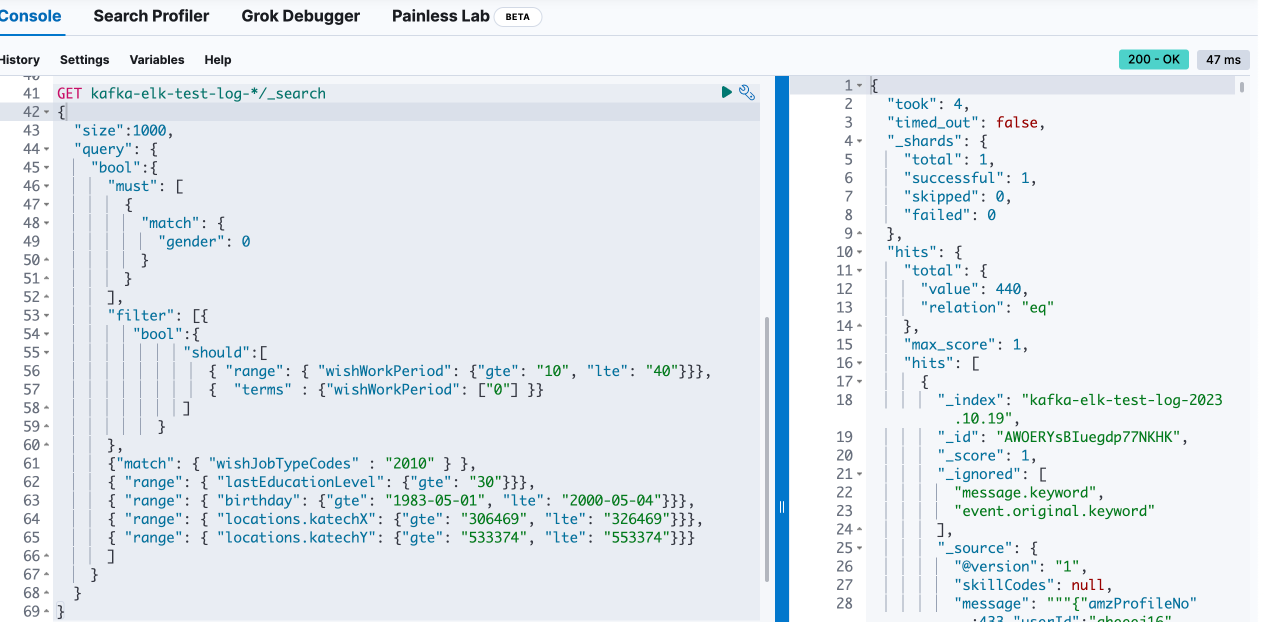 10만개여서 그런지 0.047초가 나왔다.
10만개여서 그런지 0.047초가 나왔다.
혹시 kibana의 devtool로 검색을 날려서 빠른건지 의문이 들어 postman으로 날려보았다.
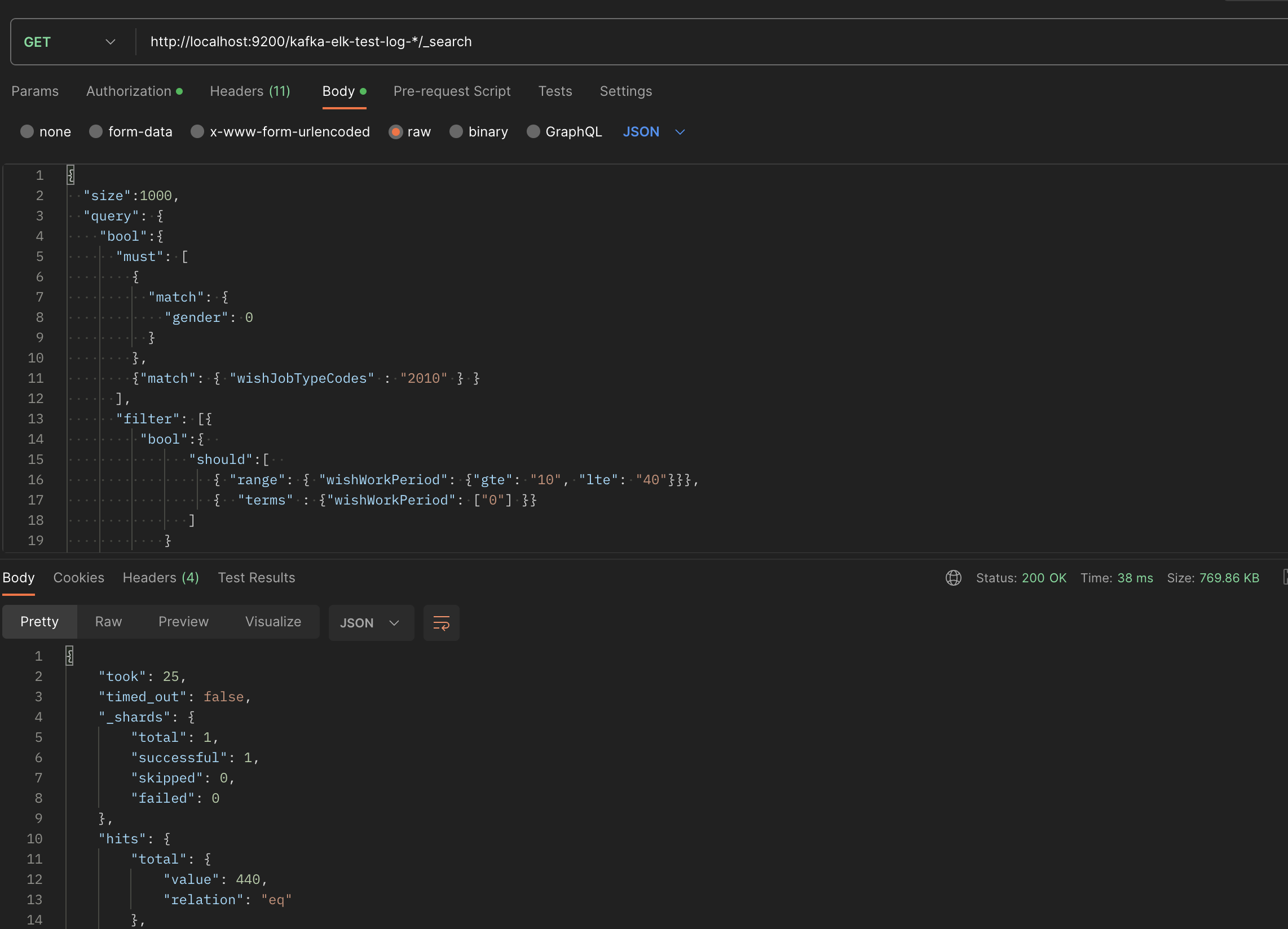 0.038초로 더 빨리 검색이 되었다..
0.038초로 더 빨리 검색이 되었다..
-
100만건 검색

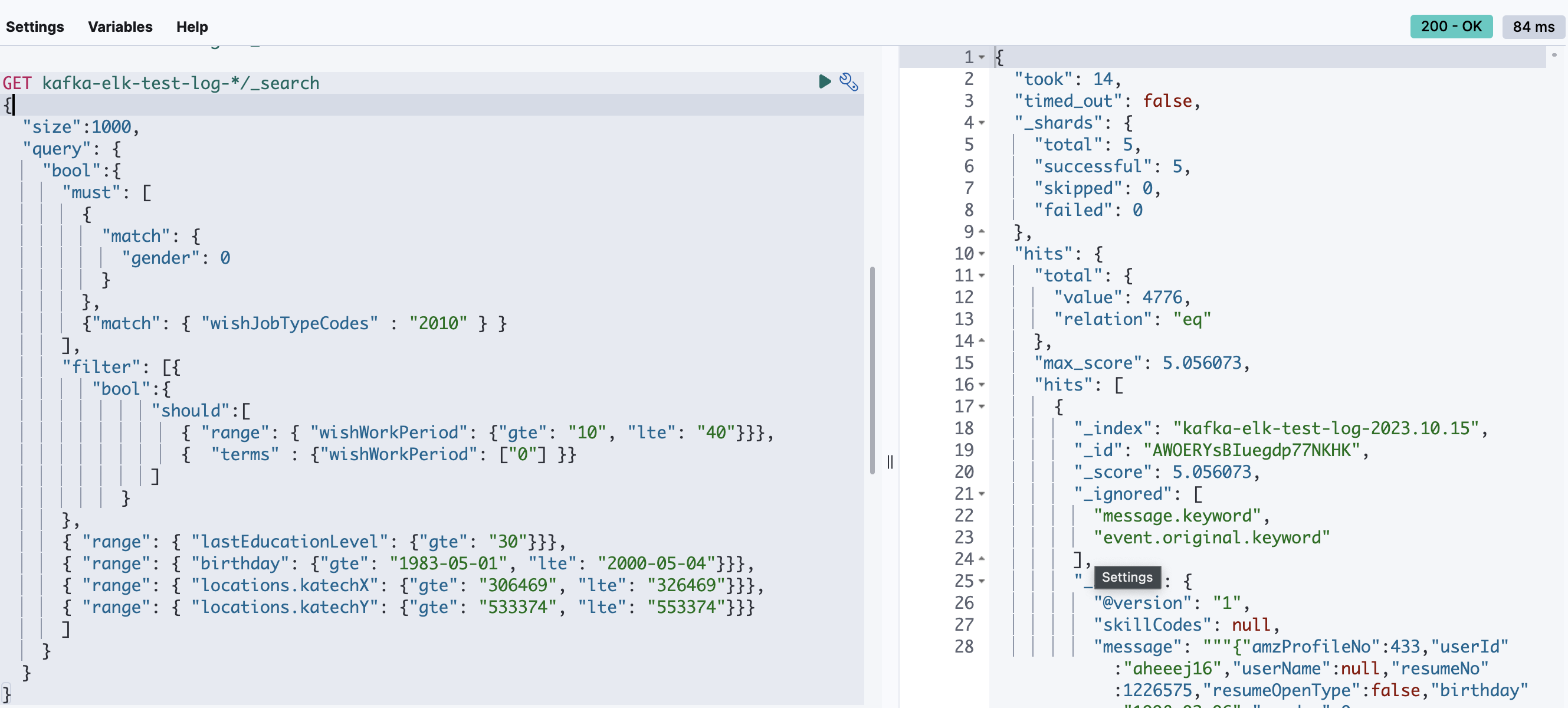
0.084초가 걸렸다.
-
500만건 검색
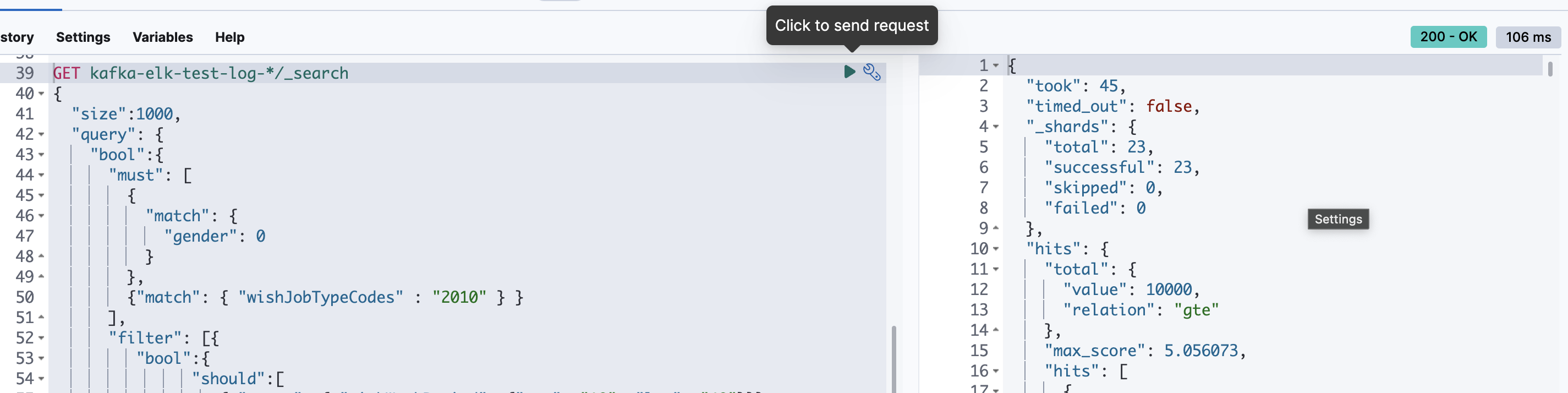
0.106초가 걸렸다.
결론
검색 조건에 따라 검색 속도가 달라질 수 있겠지만 500만건의 데이터가 0.1초걸렸다는거는 기존 DB의 수초에 비하면 엄청난 성능향상으로 판단 된다.
고려해야될 점
실제 운영에서 사용하기 위해서는 인프라 등 많은 것들이고려되야겠지만 가장 우선적으로 데이터 동기화가 중요하다고 판단된다.
elasticsearch에서 데이터 적재는 비용이 적지만 수정과 삭제와 같은 api요청은 리소스가 크다고 한다.
수정과 삭제 요청이 매우 큰 비용?이 든다면
특정 동기화 시점에 모든 이력서 정보를 조회하여 인덱싱을 하거나 변경 시점의 데이터만 업데이트 하는 방법이 있을것 같다.
logstash는 다양한 플러그인을 제공하는데 jdbc input plugin을 사용하면
logstash가 설정한 주기마다 DB로부터 데이터를 조회하여 elasticsearch에 자동으로 동기화가 가능하다고 한다.
운영에 적용이 필요하다고 판단된다면 위와같은 데이터 동기화 이슈의 검증이 필요하다.
