경로 Path
: 프로그램에서 사용할 자원의 위치
: 파일 시스템에서는 파일이나 디렉토리가 있는 위치의 경로를 뜻함
절대경로
- 자원의 전체 경로를 표현하는 방식
- 시작 경로부터 자원(파일, 디렉토리)이 있는 위치까지 표현
⇒ 시작 경로: Root Path
- windows:
c:,d:- Unix, Linux:
/
상대경로
- 현재 작업 경로(위치)에서 부터 자원이 있는 위치까지 표현
⇒ 시작 경로: 현재 작업경로구문
.: 현재 디렉토리..: 상위 디렉토리/: 경로 구분자, 상위경로/하위경로
- 운영체제(O/S)별 경로구분자
- 윈도우즈:
\(역슬래쉬) - 리눅스/유닉스:
/(슬래쉬)
- 윈도우즈:
ex)
file_path1 = "c:\classes\01_python\calculater.py" #절대 경로
file_path2 = r"c:\\classes\01_python\calculater.py" # r-string: escape 문자 처리를 안함
file_path3 = "/src/python/a.py" #/로 시작했으니 절대경로
file_path4 = "./python/a.py" #현재 directory 내에서 드러가니까 상대 경로
file_path5 = "python/a.py" #상대경로. 시작의 './' 는 생략 가능
file_path6 = "calculater.py" #산대경로 './calculater.py'에서 './'를 생략⇒ 시작점 없으면 무조건 상대경로로 본다
(시작을 절대경로로 하지 않으면 다 상대경로)
현재 경로 → working directory ⇒ 현재 실행중인 프로그램의 위치
- jupyter notebook → 노트북 파일의 위치
- script 파일 실행 → script 파일의 위치
- 나의 jupyter notebook의 위치 확인
# 현재 working directory 조회
import os
cwd = os.getcwd()
print(type(cwd), cwd)입출력 (IO)
: 프로그램이 사용하려는 외부 자원을 연결하여 데이터를 입력 받거나 출력하는 작업
- 외부자원
: 파일, 원격지 컴퓨터(Network으로 연결된 컴퓨터의 자원), 데이터베이스 등
Stream
- 입출력 시 데이터의 흐름을 stream 이라고 한다.
InputStream
- Program이 외부로 부터 데이터를 읽어 들이는 흐름.
OutputStream
- Program이 외부로 데이터를 써주는 흐름.
IO 코딩 순서
파일 열기 → 데이터를 파일에 쓰기/읽기 → 파일 닫기(연결 끊기)
파일 열기(연결)
- open() 함수 사용
→ 연결된 파일과 입출력 메소드를 제공하는 객체(Stream)를 리턴
구문
open(file, mode='r', encoding=None)
함수 주요 매개변수
file
: 연결할 파일 경로
mode
: 열기 모드mode는 목적, 데이터종류를 조합한 문자열을 사용
encoding
: 텍스트 파일일 경우 인코딩 방식
: None 또는 생략하면 os 기본 encoding방식을 따름
→ Windows: cp949/euckr
→ Linux, Unix: utf-8
| mode타입 | mode문자 | 설명 |
|---|---|---|
| 목적 | r | 읽기 모드-목적의 기본 모드 |
| w | 새로 쓰기 모드 | |
| a | 이어 쓰기 모드 | |
| x | 새로 쓰기모드-연결하려는 파일이 있으면 Exception발생 | |
| 데이터 종류 | b | binary 모드 |
| t | Text모드-text데이터 입출력 시 사용 |
출력 method
- write(출력할 Data)
- 연결된 파일에
출력할 Data출력한다.
- 연결된 파일에
- writelines(문자열을 가진 컬렉션)
- 리스트, 튜플, 집합이 원소로 가진 문자열들을 한번에 출력한다.
- text 출력일 경우에만 사용가능.
- 원소에 문자열 이외의 타입의 값이 있을 경우 TypeError 발생
ex)
os.chdir() # 해당 파일의 경로 기입
print(os.getcwd())
#출력할 파일들을 저장할 dierectory를 생성
os.makedirs("files", exist_ok = True)
# 출력한 파일과 연결
fw = open("files/test.txt", #연결할 파일의 경로
mode = "wt", # w: 출력(파일이 없으면 만들어서 연결, 있으면 연결 후 파일 내용을 삭제(새로 쓰기)), t: text-> 생략 가능
encoding = "utf-8" # 문자열 인코딩 방식. 생략: os의 기본 인코딩 방식 (win: cp949, max: )
)
print(type(fw))
#2. 출력(Output) 작업
fw.write("hello") # write method 사용함/ print가 아니라 연경된 file에 들어있음
fw.write("nice to meet you")
fw.write("hello world")
#enter 없으니까 한줄에다가 옆으로 쭉 나옴
# 여러줄을 원하면 뒤에 \n 붙이기
# 3. 파일과 연결 닫기
fw.close()입력 method
- read()
: 문자열(text mode), bytes(binary mode)
- 연결된 파일의 내용을 한번에 모두 읽어 들인다.
- readline() → line 단위로 처리 할 떄 주로 사용
: 문자열(text mode), bytes(binary mode)
- 한 줄만 읽는다.
- text 입력일 경우만 사용가능
- 읽은 라인이 없으면 빈문자열을 리턴한다.
- readlines()
: 리스트
- 한번에 다 읽은 뒤 각각의 라인을 리스트에 원소로 담아 반환한다.
- Input Stream (TextIOWrapper, BufferedReader)는 Iterable 타입
- for문을 이용한 라인 단위 순차 조회할 수 있다.
ex)
## 1. 연결
fr = open("files/test/txt", mode= "rt",
encoding = 'utf-8') # r: 기본, t: 기본(rt일 경우엔 생략 가능)
##2. 읽기
read_txt = fr.read() #전체를 한번에 읽어온다
print(read_txt)
##3. 연결 닫기
fr.close()- 앞의 2줄만 읽겠다면
#앞의 몇 줄만 읽을 대에는 readline을 사용 할 수 있다
fr = open("files/test.txt", mopde = "rt", encoding = "utf-8")
for _ in range(2):
print(fr.readline())
fr.close()with block 사용
파일과 입출력 작업이 다 끝나면 반드시 연결을 닫아야 함
→ 매번 연결을 닫는 작업을 하는 것이 번거롭고 실수로 안 닫을 경우 문제 발생 가능
with block
: block을 벗어나면 자동으로 연결을 닫아줌 (연결 닫는 코드 생략 가능)
- 구문
with open()as 변수: #`변수`는 open()이 반환하는 Stream객체를 참조
#입출력 작업
# 변수를 이용해 입출력 작업을 처리
# with block을 빠져 나오면 close()가 자동으로 실행CSV (Comma Separated Value) 파일
- 데이터들을 정형화(표)된 형태로 텍스트파일에 저장하는 방식
- 하나의 데이터는 한줄에 표시 (데이터 구분자는 엔터)
- 하나의 데이터를 구성하는 값들(속성)들은 , 로 구분
- tab으로 구분하는 경우 TSV
- 각 속성값들은 " " 로 감싸기도 함
- 텍스트기반
- 파일 확장자는
.csv,.tsv사용
ex) csv 파일 열어서 보기
- member.csv 파일을 읽어서 각 열의 값을 배열에 담기
- 이름,나이,주소 형태의 csv를 읽어 배열에 넣기
names= []
ages=[]
addresses=[]이름, 나이, 주소
유재석, 30, 서울
박명수, 35, 인천
정준하, 40, 부산
노홍철, 55, 과주
정형돈, 60, 대구
하하, 65, 울산
→ 라는 member라는 파일을 읽어보자
# 각 값을 저장할 list
name = [] #list()
afes = []
addresses = []
# 란줄 씩 읽어서 각각의 속성값들을 각 리스트에 추가
##1. 파일 연결
with open("data/member.csv", "rt") as fr:
fr.read()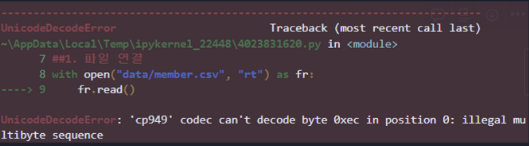
→ 인코딩 방식의 오류가 난것 ( 'cp949' codec로 읽으면 안됨)
→ 웬만하면 요즘은 utf-8로 사용한
⇒ 따라서 encoding = "utf-8” 추가
- 결과
# 각 값을 저장할 list
name = [] #list()
afes = []
addresses = []
# 란줄 씩 읽어서 각각의 속성값들을 각 리스트에 추가
##1. 파일 연결
with open("data/member.csv", "rt", encoding = "utf-8") as fr:
for line_txt in fr:
print(line_txt)→output:
이름, 나이, 주소
유재석, 30, 서울
박명수, 35, 인천
정준하, 40, 부산
노홍철, 55, 과주
정형돈, 60, 대구
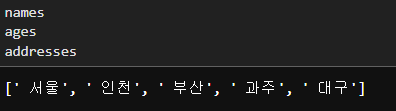
names = [] #list()
ages = []
addresses = []
# 란줄 씩 읽어서 각각의 속성값들을 각 리스트에 추가
##1. 파일 연결
with open("data/member.csv", "rt", encoding = "utf-8") as fr:
for line_no, line_txt in enumerate(fr):
if line_no == 0: # 0번 라인 -> header부분을 제거
continue #다음 반복 시행
print(line_txt.strip().split(",") ) #strip-> 공백 제거
# ',' 기준으로 나눔→output:
['유재석', ' 30', ' 서울']['박명수', ' 35', ' 인천']
['정준하', ' 40', ' 부산']['노홍철', ' 55', ' 과주']
['정형돈', ' 60', ' 대구'
with open("data/member.csv", "rt", encoding = "utf-8") as fr:
for line_no, line_txt in enumerate(fr):
if line_no == 0: # 0번 라인 -> header부분을 제거
continue #다음 반복 시행
name, age, address = line_txt.strip().split(",") #strip-> 공백 제거 # ',' 기준으로 나눔
names.append(name)
ages.append(age)
addresses.append(address→output:
for name, age, address in zip(names, ages, addresses):
print(f"이름: {name}, 나이: {age}, 주소: {address}")→output:
이름: 유재석, 나이: 30, 주소: 서울
이름: 유재석, 나이: 35, 주소: 인천
이름: 박명수, 나이: 40, 주소: 부산
이름: 정준하, 나이: 55, 주소: 과주
이름: 노홍철, 나이: 60, 주소: 대구
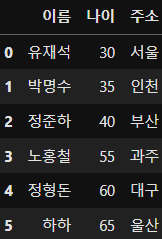
그리고 pandas를 사용하여 csv파일 불러오기
# pip install pandas
import pandas as pd
df = pd.read_csv("data\member.csv")
df⇒ 최종 도출 결과(output)
binary 데이터 입출력
: 텍스트 인코딩을 하지 않고 입출력하는 데이터
출력(binary) 할 떄 'bytes' 타입으로 변환해서 출력
- 8 bit = 1 byte
- 5 byte = 1 bytetype
binary data 를 입력 받으면 'bytes' 타입으로 반환
각 타입 -> bytes : 출력 bytes -. 각 타입 : 입력
pickle 모듈을 이용한 객체 직렬화 Object Serialization
- 객체 직렬화(Object Serialization) : 객체의 속성값들을 bytes로 변환해 출력하는 것
- 객체 역직렬화(Object Deserialization) : bytes로 출력된 데이터를 읽어 객체화 하는 것
pickle
- 객체 파일 입출력을 위한 파이썬 모듈
- open() 시 binary mode로 설정
- 저장시 파일 확장자는 보통
pkl이나pickle사용
fw = open("data.pkl", "wb") # 객체를 pickle에 저장하기 위한 output stream 생성
fr = open("data.pkl", "rb") # 파일에 저장된 객체를 읽어오기 위한 input stream 생성- method
- dump(저장할 객체, fw) : 출력
- load(fr): 입력 - 읽은 객체를 반환
