
인공지능 (AI - Artificial Intelligence)
- 지능: 어떤 문제를 해결하기 위한 지적 활동 능력
- 인공지능
- 기계가 사람의 지능을 모방하게 하는 기술
- 규칙기반, 데이터 학습 기반
Strong AI (강 인공지능) vs Weak AI (약 인공지능)
- Artificial General Intelligence (AGI)
- 인간이 할 수 있는 모든 지적인 업무를 해낼 수 있는 (가상적인) 기계의 지능을 말한다. 인공지능 연구의 주요 목표.
- Strong AI (강 인공지능)
- AGI 성능을 가지는 인공지능
- 인공지능 연구가 목표하는 방향.
- Weak AI (약 인공지능)
- 기존에 인간은 쉽게 해결할 수 있었지만 컴퓨터로 처리하기 어려웠던 일을 컴퓨터가 수행할 수 있도록 하는 것이 목적.
- 지각(知覺)을 가지고 있지 않으며 특정한 업무를 처리하는데 집중한다.
인공지능의 발전을 가능하게 만든 세가지 요소
- 데이터의 급격한 증가
- 디지털사진, 동영상, IoT 기기, SNS 컨텐츠 등으로 인해 데이터가 폭발적으로 증가
- 전 세계 디지털데이터의 90%가 최근 2년 동안 생성
- 알고리즘의 발전
- 급증한 데이터를 이용한 기존 알고리즘 개선 및 새로운 알고리즘들이 개발됨.
- 컴퓨터 하드웨어의 발전
- CPU와 GPU의 발전.
- 특히 GPU의 발전은 딥러닝의 발전으로 이어짐.
- TPU(Tensor Processing Unit)
머신러닝과 딥러닝
머신러닝(Machine Learning)
- 데이터 학습 기반의 인공 지능 분야
- 기계에게 어떻게 동작할지 일일이 코드로 명시하지 않고 데이터를 이용해 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 인공지능의 한분야
딥러닝 (Deep Learning)
- 인공신경망 알고리즘을 기반으로 하는 머신러닝의 한 분야. 비정형데이터(영상, 음성, 텍스트)에서 뛰어난 성능을 나타낸다. 단 학습 데이터의 양이 많아야 한다.
- 비정형 데이터
- 정해진 규칙 없이 저장되어 값의 의미나 특성을 쉽게 파악할 수 없는 데이터
- 텍스트, 영상, 음성 데이터가 대표적인 예이다.
- 정형 데이터
- 표(table)형태의 미리 정해 놓은 형식과 구조에 따라 저장되도록 구성된 데이터로 그 의미나 특성파악이 용이하다.
- 대표적이 예로 관계형 데이터베이스가 있다.
기존 프로그래밍 방식과 머신러닝 방식의 차이
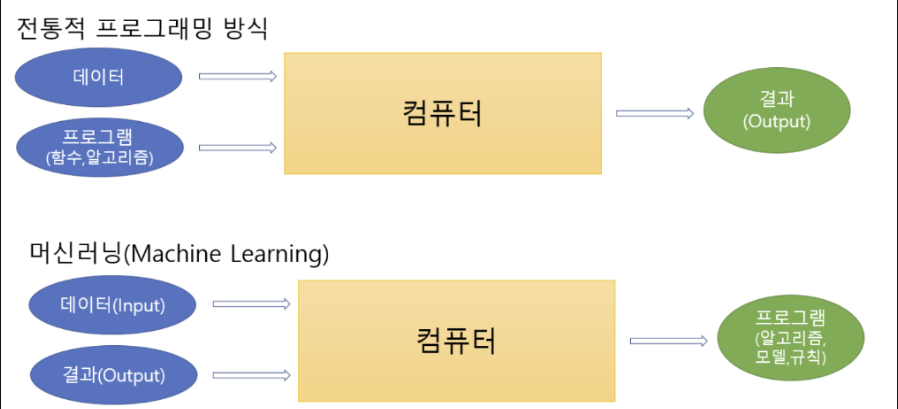
머신러닝 모델(알고리즘, 모형)
- 모델이란 데이터의 패턴을 수식화 한 함수를 말한다.
- 함수(Function)
- 머신러닝은 입력데이터와 출력데이터를 이용해 그 둘의 관계 mapping에 근사한 함수를 찾는다.
- 그러나 처음에는 방대한 데이터에 대한 정확한 패턴을 알 수 없기 때문에 "이 데이터는 이런 패턴을 가졌을 것"이라고 가정한 함수(가설)를 정한 뒤 데이터를 학습시켜 데이터 패턴을 잘 표현하는(근사한) 함수를 만든다.
데이터 관련 용어
Feature
- 추론하기 위한 근거가 되는 값들을 표현하는 용어.
- 예측 하거나 분류해야 하는 데이터의 특성, 속성 값을 말한다.
- 입력 변수(Input), 독립변수라고도 한다.
- 일반적으로 X로 표현한다.
Label
- 예측하거나 분류해야 하는 값들을 표현하는 용어
- 출력 변수(Output), 종속변수, Target 이라고도 한다.
- 일반적으로 y로 표현한다.
데이터 포인트
딥러닝의 특징
- 기존 머신러닝과 딥러닝 알고리즘은 데이터를 학습시켜 알고리즘을 찾아낸다는 점에서는 동일하다.
- 학습을 통해 좋은 알고리즘을 찾기 위해서는 데이터로 부터 우리 목적에 맞는 특성들을 추출해 학습데이터를 잘 만들어야 한다.
- 원본 데이터(Raw) 에는 패턴을 찾는데 필요 없거나 방해되는 요소(Noise)들도 포함되 있다.
- 그래서 데이터 전처리를 통해 noise들을 제거하고 중요한 특성들만 찾아야 한다. 이런 작업을 데이터 전처리, Feature extraction 이라고 한다.
- 기존 머신러닝은 Feature 추출을 사람이 작업한다. 그리고 그 추출된 Feature vector로 부터 알고리즘을 찾아내는 것을 학습을 통해 자동으로 처리한다.
- 딥러닝은 feature 추출을 모델에 넣어 학습시 feature 추출과 알고리즘 찾는 작업을 동시에 한다.
- 그래서 딥러닝은 feature를 찾기 힘든 비정형데이터에서 좋은 성능을 나타낸다. Feature 추출이 용이한 정형데이터의 경우 기존 머신러닝 알고리즘이 좋은 성능을 보인다.
