정규표현식
→ 자연어 (사람이 사용하는 언어) 처리부분에서 많이 사용
정규 표현식
- 텍스트에서 특정한 형태나 규칙을 가지는 문자열을 찾기 위해 그 형태나 규칙을 정의하는 것.
- 파이썬 뿐만 아니라 문자열을 다루는 모든 곳에서 사용
- 정규식, Regexp이라고도 함
- 패턴
= 정규 표현식
→ 문장내에서 찾기위한 문구의 형태에 대한 표현식 - 메타문자
→ 패턴을 기술하기 위해 사용되는 특별한 의미를 가지는 문자> ex) a* : a가 0회 이상 반복을 뜻한다. a, aa, aaaa - 리터럴
→표현식이 값 자체를 의미하는 것> ex) a는 a 자체를 의미한다.
정규 표현식 메타 문자 = 패턴을 기술하기 위한 문자
문자 클래스 : [ ]
[ ]사이의 문자들과 매칭
→[abc]: a, b, c 중 하나의 문자와 매치-를 이용해 범위로 설정할 수 있다.
→[a-z]: 알파벳소문자중 하나의 문자와 매치
→[a-zA-Z0-9]: 알파벳대소문자와 숫자 중 하나의 문자와 매치
→[ㄷㄹㄴㄹ]: 한글 중 하나와 매치[^ 패턴]: ^ 으로 시작하는 경우 반대의 의미
→[^abc]: a, b, c를 제외한 나머지 문자들 중 하나와 매치.
→[^a-z]: 알파벳 소문자를 제외한 나머지 문자들 중 하나와 매치
소문자와 대문자는 따로 표기해야함
미리 정의된 문자 클래스
자주 사용되는 문자클래스를 미리 정의된 별도 표기법으로 제공한다.
\d: 숫자와 매치.[0-9]와 동일\D:\d의 반대. 숫자가 아닌 문자와 매치.[^0-9]와 동일\w: 문자와 숫자, (underscore)와 매치. [a-zA-Z가-힣0-9]와 동일 (문자는 특수문자 제외한 일반문자들(언어 상관 없는)을 말한다.\W:\w의 반대. 문자와 숫자와 가 아닌 문자와 매치.`[^a-zA-Z가-힣0-9]`와 동일\s: 공백문자와 매치. tab,줄바꿈,공백문자와 일치\S:\s와 반대. 공백을 제외한 문자열과 매치.\b: 단어 경계(word boundary) 표시. 보통 단어 경계로 빈문자열
단어경계: 공백,.,-,,등.\b가족\b=> 우리 가족 만세(O), 우리가족만세 (X)\B:\b의 반대. 단어 경계로 구분된 단어가 아닌 경우\B가족\B=> 우리 가족 만세(X), 우리가족만세 (O)
글자수와 관련된 메타문자
*: 앞의 문자(패턴)과 일치하는 문자가 0개 이상인 경우. (a*b)+: 앞의 문자(패턴)과 일치하는 문자가 1개이상인 경우. (a+b)?: 앞의 문자(패턴)과 일치하는 문자가 한개 있거나 없는 경우. (a?b){m}: 앞의 문자(패턴)가 m개.(a{3}b)
→ m개의 문자 존재{m,}: 앞의 문자(패턴)이 m개 이상.(a{3,}b)
→ 최소 개수,뒤에 공백이 들어오지 않도록 한다.{m,n}: 앞의 문자(패턴)이 m개이상 n개 이하. (a{2,5}b).,*,+,?를 리터럴로 표현할 경우\를 붙인다
→\는 앞에 붙임
문장의 시작과 끝 표현
^문자열의 시작 (^abc)- 문자 클래스([ ])의 ^와는 의미가 다르다.
$: 문자열의 끝 (abc$)
기타
.: 한개의 모든 문자(\n-줄바꿈 제외) (a.b)
→enter제외 모든 글자중 한글자가 온다
→ 자릿수는 3개로 본다.|: 둘중 하나(OR)
→ 이떄 앞에?:을 붙여준다 (하위 패턴을 위한 ( )이 아니라는 의미)
→ ex) (?:010|011|016|019)
- 010|016-111 : 010 또는 016-111 이 된다.( ): 패턴내 하위그룹을 만들때 사용
re 모듈 (Regula Express)
- 파이썬에서 정규 표현식을 지원하기 위한 모듈
- 파이썬 기본 라이브러리
코딩패턴
- 모듈 import
import re
-
객체지향형
- 패턴 객체를 생성후 메소드를 호출해 원하는 처리를 한다.
p = re.compile(r'\d+') p.search('abc123def')
- 패턴 객체를 생성후 메소드를 호출해 원하는 처리를 한다.
-
함수형
re모듈의 원하는 작업을 하는 함수를 호출한다. Argument로 패턴과 처리할 값을 전달한다.
패턴 →re.search(r'\d+', 'abc123def')'\d+'
처리할 값 →'abc123def'
r은 raw string이용한 것
raw string
- 패턴문자중
\로 시작하는 것들을 사용할 경우escape문자와의 구분을 위해\\두개씩 작성해야한다. 그래서 패턴을 지정할 때는 raw string을 사용하는 것이 편리하다.
re.compile('\b가족\b'):\b를 escape 문자 b(백스페이스)로 인식re.compile(r'\b가족\b'):\b가 일반문자가 되어 컴파일시 정규식 메타문자로 처리된다.
→ \\이거 사용하는거보다는 rawstring 사용 권장 (r 자 붙이기)
검색 함수
- match(), search() : 패턴과 일치하는 문장이 있는지 여부를 확인할 때 사용
→ 존재 여부 확인 - findall() : 패턴과 일치하는 문장을 찾을 때 사용
Match 객체
- 검색 결과를 담아 반환되는 객체
→ match(), search() 의 반환타입- 패턴과 일치한 문자열과 대상문자열 내에서의 위치를 가지고 있는 객체
- 주요 메소드
→ group() : 매치된 문자열들을 튜플로 반환
→ group(subgroup 번호) : 패턴에 하위그룹이 지정된 경우 특정 그룹의 문자열 반환
→ start(), end() : 대상 문자열내에서 시작, 끝 index 반환
→ span() : 대상 문자열 내에서 시작, 끝 index를 tuple로 반환
match(대상문자열 [, pos=0])
- 대상 문자열의 시작 부터 정규식과 일치하는 것이 있는지 조회
- pos : 시작 index 지정
- 반환값
→ Match 객체: 일치하는 문자열이 있는 경우
→ None: 일치하는 문자열이 없는 경우
ex)
import re
txt = "안녕하세요, nice to meet you. My name is 20"
#객체지향 방식 -> pattern객체를 생성한 뒤 그 메소드를 이용해 패턴의 대상 문자열들을 처리
##1. 패턴 객체를 생성
p = re.compile(r"\w{2}하세요") #\ㅈ{2} - 일반문자, 숫자, __두글자
print(type(p))
result = p.match(txt) #txt가 p의 패턴으로 시작하는지 여부
if result is None:
print(type(result))
print(result)
print("location:", result.span())
print(f"start location::{result.start()}, finish location(index): {result.end()}")
print(f"find 문자열:{result.group()}")
else:
print(result)
print("지정한 패턴으로 시작하는 문자열입니다")ex)
#txt = "안녕하세요, nice to meet you. My name is 20"
txt = " nice to meet you. 안녕하세요, My name is 20"
## 함수를 이용하는 방식
# re 모듈의 match() 함수를 호출 ==> pattern 객체의 match() 메소드와 동일한 기능
result = re.match(r"\w{2}하세요", txt) # (패턴, 대상문자열)
print(result)
if result:
print(result.group())
else:
print("찾는 패턴으로 시작하지 않습니다")search(대상문자열 [, pos=0])
- 대상문자열 전체 안에서 정규식과 일치하는 것이 있는지 조회
- pos: 찾기 시작하는 index 지정
- 반환값
→ Match 객체: 일치하는 문자열이 있는 경우
→ None: 일치하는 문자열이 없는 경우|
txt = "반갑습니다.안녕하세요. 제 나이는 20입니다"
txt = "반갑습니다.안녕하세요. 제 나이는 20입니다. 30. 40. 50"
pattern = r"\d{2}" #숫자 2개
result = re.match(pattern,txt)
print(result)
# 전체 문장 안에 패턴이 있는지 확인 (모두 찾지는 않음. 첫번쨰 것을 찾으면 거기서 종료)
## 찾는것의 존재 유뮤만 신경쓰고 개수는 신경 안씀)
result2 = re.search(pattern,txt)
print(txt[result2.start()])ex)
txt = "가격은 400, 5000, 15000입니다"
#p = re.compile(r"\d+") # 숫자 1개 이상이 연결
#p = re.compile(r"\d{5}") # 숫자 5개가 연결 - 만단위 정수
p =re.compile(r"\d{4,7}") # 숫자가 4개이상 7개 이하 연결 -> 천 ~ 백만 단위
result = p.search(txt)
if result:
print(result)
print(result.group())
print(result.span())
else:
print("찾는 패턴이 없습니다")findall(대상문자열)
- 대상문자열에서 정규식과 매칭되는 문자열들을 리스트로 반환
- 반환값
→ 리스트(List) : 일치하는 문자열들을 가진 리스트를 반환
→ 일치하는 문자열이 없는 경우 빈 리스트 반환
finditer(대상문자열)
- 패턴에 일치하는 모든 문자열을 찾아주는 Iterator => for문, list()
- 찾은 문자열을 Match 객체로 반환.
txt = "가격은 400, 5000, 15000입니다. 물건은 각각 10개 20개 100개 있습니다"
p = re.compile(r"\d+")
# p = re.compile(r"\d{10}")
result = p.findall(txt)
print(type(result))
print(result)
# 찾은 목록을 모두 list로 보여줌위의 코드에서 # p = re.compile(r"\d{10}")를 사용한다면 일치하는 패턴의 문장이 없을 경우 빈 리스트를 반환받게 될 것이다.
finditer (대상문자열)은 찾은 결과를 조회할 수 있는 Iterator을 반환한다. 그리고 Iterator는 각 결과를 match 객체로 반환한다.
txt = "가격은 400, 5000, 15000입니다. 물건은 각각 10개 20개 100개 있습니다"
p = re.compile(r"\d+")
result = p.finditer(txt)
print(type(result))
for match in result:
print(match)example )
info ='''김정수 kjs@gmail.com 801023-1010221
박영수 pys.abc@gmail.com 700121-1120212
이민영 lmy-abc@naver.com 820301-2020122
김순희 ksh@daum.net 781223-2012212
오주연 ojy@daum.net 900522-1023218
'''# Email 주소만 추출 해서 출력
import re
e_pattern = r"\b[\w\.-]+@[\w\.-]+\.\w{2,4}\b"
p = re.compile(e_pattern)
result = p.findall(info)
print(result)
# 주민번호들만 조회해서 출력
import re
pattern = r"\d{6}-\d{7}"
pattern = r"\d{6}-[01234]\d{6}" # [] 안은 주민번호 뒷자리중 맨 첫자리를 의미한다
p = re.compile(pattern)
result = p.findall(info)
print(result)정규 표현식 연습 사이트
https://regexr.com/
문자열 변경
- sub(): 변경된 문자열 반환
- subn(): 변경된 문자열, 변경개수 반환
sub(바꿀문자열, 대상문자열 [, count=양수])
- 대상문자열에서 패턴과 일치하는 것을 바꿀문자열로 변경한다.
- count: 변경할 개수를 지정. 기본: 매칭되는 문자열은 다 변경
- 반환값: 변경된 문자열
subn(바꿀문자열, 대상문자열 [, count=양수])
- sub()와 동일한 역할.
- 반환값 : (변경된 문자열, 변경된문자열개수) 를 tuple로 반환
txt = " 오늘은 화요일 입니다. ".strip()
print(txt)
#pattern = r"\s"
pattern = r" {2,}"
result = re.sub(pattern, " ", txt) # 함수(패턴표현식, 바꿀문자열, 대상문자열)
print(result)이때 바깥의 공백은 strip()으로 없앨 수 있다. 그러나 안의 공백은 어떻게 없애야 할까? 여러개의 공백을 한개의 공백으로 변환해야 한다. 이떄 이 경우에는 pattern = r"\s" 을 사용 할 수 있는데 이는 공백문자, tap, enter모두 공백 하나로 취급하기 때문에 여기선 가능한데 tab이나 enter을 살려야 할 경우 사용이 불가하다. 그래서 대신 pattern = r" {2,}"를 사용하였다.여기에선 공백이 여러개 이므로 space도 문자로 취급하기 때문에 2개 이상의 공백이라고 표시한다.
그리고 result = re.sub(pattern, " ", txt) 이 과정을 통해 공백 2개 이상인 것은 1개로 바꾸어준다.
나누기(토큰화)
split(대상문자열)
- pattern을 구분자로 문장을 나눈다.
- 반환: 나눈 문자열을 원소로 하는 리스트
fruits = "사과, 배, 복숭아, 수박|파인애플"
#fruits.split(",")
result = re.split(r"[,+|]", fruits)
result|를 두고 붙어있는 수박과 파인애플을 split해서 이러한 결과를 얻었다.
['사과', ' 배', ' 복숭아', ' 수박', '파인애플']
패턴내 하위패턴 만들기 (Grouping)
- 전체 패턴에서 일부 패턴들을 묶어 하위패턴으로 만든다.
- 구문: (패턴)
ex) 전체 패턴 내에서 일부 패턴을 조회
ex) 패턴 내에서 하위그룹 참조
\번호- 지정한 '번호' 번째 패턴으로 매칭된 문자열과 같은 문자열을 의미
ex) 패턴내의 특정 부분만 변경
info ='''김정수 kjs@gmail.com 801023-1010221
박영수 pys.abc@gmail.com 700121-1120212
이민영 lmy-abc@naver.com 820301-2020122
김순희 ksh@daum.net 781223-2012212
오주연 ojy@daum.net 900522-1023218
'''print(info)
# 주민번호 뒷 7자리 중에 8자리를 감추기 -> '*'으로 변경하기
# 주민번호를 조회한 뒤에 뒷 6자리만 변경
jumin_pattern = r"(\d{6}-[012349])\d{6}" # 변경하지 않을 부분을 subgroup으로 묶어주기
p = re.compile(jumin_pattern)
result = p.sub("\g<1>******", info) # \g<1>-> 1번 subgroup으로 찾은 값을 그대로 사용
print(result)ourput:
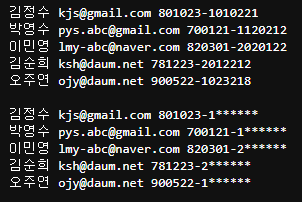
group으로 묶인 것 참조(조회)
- 패턴 안에서 참조
→\번호,r'(\d{3}) \1'=> 중복되는 것을 패턴으로 표현할 때. - match 조회
→ match객체.group(번호) - sub() 함수에서 대체 문자로 참조
→\g<번호>
Greedy 와 Non-Greedy
-
Greedy(탐욕스러운-최대일치) 의미
→ 주어진 패턴에 만족하는 문자열을 최대한 넓게(길게) 잡아 찾는다.
→매칭시 기본 방식 -
Non-Greedy(최소일치)
→ 주어진 패턴에 만족하는 문자열을 최초의 일치하는 위치까지 찾는다
→ 개수를 나타내는 메타문자(수량자)에?를 붙인다.
→*?,+?,{m,n}? -
greedy로 찾아질 때
txt = "<div>파이썬 <b>정규표현식</b></div>"
# 태그만 조회: <div> <b> </b> </div>
pattern = r"<.+>" # 모든 글자 중 한글자 이상을 의미
# enter제외 다 '.' 부분에 포함 됨
p = re.compile(pattern)
result = p.findall(txt)
print(len(result), result)
# <.+>이 과정 안에 마지막 닫아주는 </div> 의 >도 .+에 해당한다고 해석되버림
## <.+>의 마지막 > 가 </div> 의 >로 해석되버린것 -> greedy 한 탐색- non-greedy로 찾을때
txt = "<div>파이썬 <b>정규표현식</b></div>"
pattern = r"<.+?>"
p = re.compile(pattern)
result = p.findall(txt)
print(len(result), result)전방/후방 탐색
: 패턴과 일치하는 문자열을 찾을 때는 사용하되 반환(소비) 되지 않도록 하는 패턴이 있을 때 사용
- 전방탐색
반환(소비)될 문자열들이 앞에 있는 경우.긍정 전방탐색
%%%(?=패턴) : %%%-반환될 패턴
부정 전방탐색
%%%(?!패턴) : 부정은 =를 !로 바꾼다.
- 후방탐색
반환(소비)될 문자열이 뒤에 있는 경우.
긍정 후방탐색
(?<=패턴)%%%
부정 후방탐색
(?<!패턴)%%%
ex) 전방탐색
info = """TV 30000원 30개
컴퓨터 32000원 50개
모니터 15000원 70개"""
#info에서 가격만 조회 => 조회 결과에서는 원을 뺴고 사용
pattern = r"\d+(?=원)" # 사용하지 않을 것 묶어주기
## (? 왜묶는지_이유 패턴)-> subgroub의 소괄호 아님을 나타냄
# \d+(?=원)찾을때: \d+ 원, 찾은값에서 사용 할 것: \ㅇ+ (?="패턴") 이 패턴으로 찾은 것은 사용 안함
p = re.compile(pattern)
print(p.findall(info))
for price in p.findall(info):
print(int(price)*0.8)ex) 후방탐색
info = """TV $30000원 30개
컴퓨터 $32000원 50개
모니터 $15000원 70개"""
# (?<=패턴1)패턴2 -> 패턴 1은 조회할때만 사용, 값 사용시에는 제거 후 뒤의 패턴 2만 사용
pattern = r"(?<=\$)\d+" # $는 메타문자 -> literal로 사용할 경우 '|'를 붙인다
p = re.compile(pattern)
print(p.findall(info))
for price in p.findall(info):
print(int(price) * 0.8)