DataFrame 합치기
: 두개 이상의 DataFrame을 합쳐 하나의 DataFrame 으로 만들기
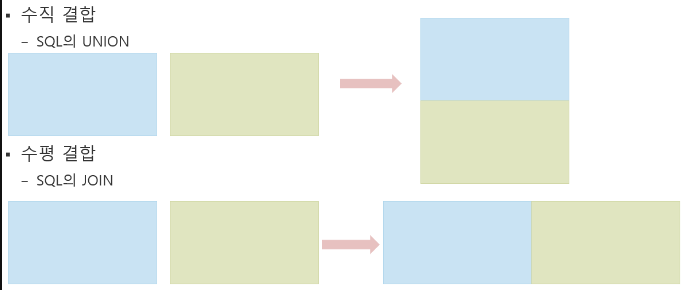
→ SQL에서의 union이나 join이라고 볼 수 있음
- 수직결합
- 단순결합으로 여러개의 DataFrame들의 같은 컬럼끼리 수직으로 합친다.
- 수평결합
- 연관성 있는 여러 데이터를 하나로 합쳐서 조회하는 JOIN 처리를 한다.
- JOIN은 합치려는 DataFrame들의 index 나 특정 컬럼의 값이 같은 행 끼리 합친다.
! 관리는 나눠서 하고, 분석은 합쳐서 하는것이 효과적
glob - 데이터셋 읽기
from glob import glob
: 특정 디렉토리 안의 파일들의 경로를 조회
## 파일명 : * : 0개 이상의 모든 글자
## 디렉토리 : ** 모든 하위 디렉토리"data/*.csv" # data 디렉토리 바로 아래에 있는 파일들 중 확장자가 csv인 파일들의 경로 (하위까진 찾지 않음)
"data/*/.csv" # 데이터 디렉토리 + 하위 디렉토리에 있는 모든 csv 를 다 찾아보라는 위미
ex)
[pd.read_csv(file) for file in glob("data/stock*.csv")]concat() 이용
: 수직 결합, 수평 결합 모두 지원
→ 하나의 데이터셋을 여러 DataFrame으로 나눈 것을 하나의 DataFrame으로 합칠 때 사용
- 수직 결합 → 행이 늘어나도록 합침
- 컬럼명이 같은 열끼리 합침
- 같은 column 명이 없는 열들도 결과 DataFrame에 들어감 (default)
- full outer join 개념
- 수평결합 → 열이 늘어나도록 합침
- index명이 같은 행 끼리 합침 (equi-join)
- 같은 index명이 없는 행들도 결과 DataFrame에 들어감(default)
- full outer join
pd.concat(objs, [, key=리스트]), axis=0, join='outer' )- 매개변수
objs: 합칠 DataFrame들을 리스트로 전달keys=[]를 이용해 합친 행들을 구분하기 위한 다중 인덱스 처리- axis
- 0 또는 index : 수직결합
- 1 또는 columns : 수평결합
- join:
- 합치는 방식으로 다음 문자열을 값으로 설정
- 'outer'(기본값): full outer join
- 'inner': inner join (동일한 index명, column명 끼리 합침)
- 합치는 방식으로 다음 문자열을 값으로 설정
- 매개변수
ex)
stock_2016, stock_2017, stock_2018 라는 3개의 stcok 데이터가 있다고 가정할 떄 이를 하나의 데이터에 표기하려면
stocks = pd.concat([stock_2016, stock_2017, stock_2018])
stocks.shape- 방법 1
stocks2 = stocks = pd.concat([stock_2016, stock_2017, stock_2018],
ignore_index = True
)
stocks2→ ignore_index = True : index 이름은 합칠 때 무시해라
- 방법 2
stocks3 = stocks = pd.concat([stock_2016, stock_2017, stock_2018],
keys = ["2016년", "2017년", "2018년"]
stocks3→ 각 DataFrame 을 구분할 수 있는 index를 추가
→ Multi index => 2016년이라는 한 index에 대하여 행이 3개 존재
+@
stocks3.loc[('2016년', 0)]
level 0 , level 1 묶어서 조회 → 튜플로 묶어서 전달 (이때 level 0이 기준)
stocks3.loc[['2016년', '2018년']]
index으로 조회
multi index를 조회할 때에는
xs를 사용하면 자유롭게 조회 가능
ex)
# multi index 햏/컬럼을 조회하는 method
stocks3.xs(0, #조회할 컬럼/ 행 이름
axis = 0, # 0: 행 조회, 1: 열조회
level = 1 # 조회할 이름의 level 위치
)조인(join)
- 여러 데이터프레임에 흩어져 있는 정보 중 필요한 정보만 모아서 결합하기 위한 것
- 두개 이상의 데이터프레임을 특정 컬럼(열)의 값이 같은 행 끼리 수평 결합하는 것
- Inner Join, Left Outer Join, Right Outer Join, Full Outer Join
예시 추가
조인을 통한 DataFrame 합치기
- 연관성있는 둘 이상의 DataFrame을 하나로 합치기
- ex) 고객과 주문정보, 교수와 수업정보, 직원과 부서정보
- join()
- 2개 이상의 DataFrame을 조인할 때 사용
- merge()
- 2개의 DataFrame의 조인만 지원
join()
dataframe객체.join(others, how='left', lsuffix='', rsuffix='')df_A.join(df_b),df_A.join([df_b, df_c, df_d])- 두개 이상의 DataFrame들을 조인 할 수 있음
- 조인 기준: index가 같은 값인 행끼리 합치기 (equi-join)
- 조인 기본 방식:
Left Outer Join
-
매개변수
-
lsuffix, rsuffix
→ 조인 대상 DataFrame에 같은 이름의 컬럼이 있으면 에러 발생
→ 같은 이름이 있는 경우 붙일 접미어 지정> **how : 조인방식** >'left', 'right', 'outer', 'inner'. left가 기본
-
stock_info.join(stock_2016, lsuffix = 'info')
#stock_info : Symbpl
#Stock_2018 : Symbol
## Symbol을 index으로 변경
join_result1 = stock_info.set_index("Symbol").join(stock_2018.set_index("Symbol"))
join_result1join_result2 = stock_info.set_index("Symbol").join(stock_2018.set_index("Symbol"),
how = 'right')
join_result2이는 right join 한 상태를 보여주는데 이때, right 대신 inner도 사용 가능함
stock_2016.add_suffix("_2016") 이 코드는 컬럼명 뒤에 접미어를 붙여줌. 이때 붙는 접미어는 전체적으로 모든 column명 뒤에 붙게됨. 그리고 add_suffix() 대신 add_preffix()을 사용하면 접미사 대신 접두사를 붙여줌
merge()
-
df_a.merge(df_b) -
두개의 DataFrame간의 조인만 가능
-
조인 기준
- 같은 컬럼명을 기준으로 equi-join을 하는 것이 기본
- 조인기준을 다양하게 정할 수 있다.
- 컬럼, index등을 기준으로 같은 행끼리 join 하도록 설정 가능- 조인 기본 방식
- inner join
- how 매개변수를 이용해 변경이 가능
- 조인 기본 방식
-
dataframe.merge(합칠dataframe, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False)
- 매개변수
- on : 같은 컬럼명이 여러개일때 join 대상 컬럼을 선택
- right_on, left_on : 조인할 때 사용할 왼쪽,오른쪽 Dataframe의 컬럼명.
- left_index, right_index: 조인 할때 index를 사용할 경우 True로 지정
- how : 조인 방식. 'left', 'right', 'outer', 'inner'. 기본: inner
- suffixes: 두 DataFrame에 같은 이름의 컬럼명이 있을 경우 구분을 위해 붙인 접미어를 리스트로 설정
- 생략시 x, y를 붙임
ex)
stock_info.merge(stock_2016)아래의 경우에는 같은 이름의 column명을 기준으로 join시킨 것
stock_info.merge(stock_2016,
how = 'left'
)이때 default 값은 inner join
stock_info.merge(stock2016
, left_on = "Symbol"
, right_index = True
)
이때 left_on = "Symbol" 는 왼쪽 DF(stock_info)의 join 컬럼을 지정한 것이고 right_index = True는 오른쪽 DF(stock2016)의 index를 join의 기준으로 사용한 것
하나의 데이터셋을 어떤 특정행 또튼 특정열을 기준으로 단순해 분리 한 경우를 합치는 경우 concat() 사용
수직 결합일 경우는 concat()을 사용해야 한다.
서로 연관성 있는 다른 데이터셋을 결합해서 보는 경우 join(), merge()를 사용한다. (Join)
두 개 이상의 DataFrame을 조인할 때는 하는 경우 : join() 사용
두개의 DataFrame을 조인할 때는 merge() 를 사용한다. => 컨트롤이 편하다.
ex)
import pandas as pd
# 1 data/customer.csv, data/order.csv, data/qna.csv 를 DataFrame으로 읽으시오.
file_names = ["customer", "order", "qna"]
customer, order, qna = [pd.read_csv(f"data/{name}.csv") for name in file_names]
customer.shape, order.shape, qna.shape
# 2 TODO1에서 읽은 세개의 데이터셋의 정보를 확인하세요.
print(customer.columns)
print(order.columns)
print(qna.columns)
# 3 customer DataFrame과 order DataFrame을 고객정보는 모두 나오도록 join 하세요.
result = customer.merge(order, left_on = "id", right_on = "cust_id", how = 'left').drop(columns = 'cust_id')
result
# 4 customer DataFrame의 index를 id컬럼으로 변경.
customer.set_index('id', inplace = True)
customer
# 5 4에서 만든 customer DataFrame과 qna DataFrame을 inner join 하세요.
## join() 사용 - index name 기
customer.join(qna.set_index('cust_id'), how = "inner")
##merge()
customer.merge(qna, left_index=True, right_on = "cust_id", how = "inner")
# 6. 세개의 DataFrame을 고객정보는 모두 나오도록 join 하세요.
customer.join([order.set_index('cust_id'),
qna.set_index('cust_id')]
, how = 'left')