NoSQL 데이터 모델링
NoSQL의 모델링 방법
NoSQL 데이타 모델링이란, NoSQL에 저장할 데이터들의 구조를 설계하는 것을 의미한다.
기존의 RDBMS와는 근본적인 2가지 사상의 변경이 필요하다.
객체 모델 지향에서 쿼리 결과 지향 모델링
RDBMS 모델링 기법은 저장할 도메인 모델을 분석한 후, 관계를 식별하고 테이블을 이용하여 쿼리를 구현. 그에 따른 결과를 뽑아내는 방식이다.
하지만, NoSQL의 경우에는 이 방법을 역순으로 진행해야 한다.
정규화(Nomalization)에서 비정규화(Denormalization)
RDBMS 모델링에서는 데이터의 일관성과 도메인 모델과의 일치를 위해 데이터 모델을 정규화한다.
하지만, NoSQL의 경우 쿼리의 효율성을 위해서 데이터를 정규화하지 않고, 의도적으로 중복된 데이터를 저장하는 등의 데이터 모델 설계 방식으로 접근한다.
NoSQL 데이터 모델링 절차
1.도메인 모델 파악
저장하고자하는 도메인을 파악한다. NoSQL도 DB이고 저장할 데이터에 대한 명확한 이해가 없이는 제대로된 모델이 나올 수 없다.
2.쿼리 결과 디자인 (데이터 출력형태 디자인)
쿼리 결과를 디자인 한다. 도메인 모델을 기반으로 Application에 의해서 쿼리되는 결과값을 먼저 정한다. 필요로 하는 출력 형식을 기반으로 필요로 하는 쿼리를 선정하고 내용을 정리한다.
3.패턴을 이용한 데이터 모델링
NoSQL은 RDBMS에서 흔히 사용하는 Sorting, Grouping, Join 등의 기능을 사용할 수 없다. 그렇기 때문에 Put / Get으로만 데이터를 가지고 올 수 있는 형태로 NoSQL의 데이터 모델을 재 정의를 해야한다.
데이터를 가급적으로 중복으로 저장(Demoralization)하여 한 번의 요청으로 데이터를 가급적 많은 정보를 가져와 데이터를 읽어오는 횟수를 줄이도록 한다.
특히 Key 값을 활용하여 여러가지 기능을 만들 수 있다. 각각의 userID나 postID 등의 값을 : 등의 구분자를 활용하여 Join, Orderring 기능으로 사용하는 것이 가능하다.
4.최적화를 위한 필요 기능들을 리스트화
각 저장할 데이터의 형태에 따라서 Document Store, Ordered Key 형태 등을 적용하여 저장한다.
5.후보 NoSQL을 선정 및 테스트
데이터의 성격과 업무의 목적에 맞는 다수의 NoSQL을 선정하여 사용
6.데이터 모델을 선정된 NoSQL에 최적화 및 하드웨어 디자인
선정된 NoSQL을 기반으로 데이터 모델을 최적화. 이에 맞는 Application 인터페이스 설계와 하드웨어에 대한 디자인을 진행.
NoSQL 모델링 패턴
기본적인 데이터 모델링
1. Denormalization
같은 데이터를 중복해서 저장하는 방식. 테이블간의 Join을 없애 1 번의 IO로 데이터를 조회할 수 있게 만든다. Join 쿼리를 여러 번 수행하지 않기 때문에 성능의 향상과 쿼리 로직의 단순함 효과를 가져온다. 하지만 데이터를 중복해서 저장하기 때문에 일관성 문제가 발생할 수 있고 스토리지의 용량이 증가하게 된다.
-
Aggregation
NoSQL이 Key만 같다면, 각 Row의 값이 규격화되지 않은 것을 이용하여 각각 틀린 구조의 데이터를 저장한다. 하나의 데이터에 모든 정보를 저장하므로 Join의 수를 줄여 Query 성능을 높인다. -
Application Side Join
어쩔 수 없이 join을 시도해야하는 경우, Application 단에서 Join이 필요한 테이블의 수 만큼 IO를 진행한다. IO가 발생하는 횟수가 많아 부담이 될 수 있지만, 스토리지 사용량을 절약할 수 있다.
확장된 데이터 모델링
1. Atomic aggregation
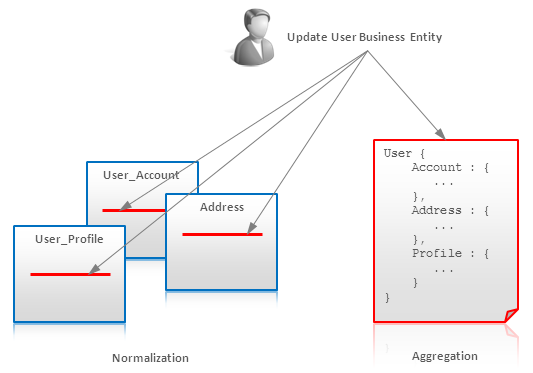
여러 테이블에 업데이트를 시도할 경우, 데이터의 일관성에 문제가 발생할 수 있다. 이러한 문제를 방지하기 위해 테이블을 하나로 합쳐서 관리를 하는 모델링을 말한다. NoSQL도 하나의 테이블에 대해서는 Atomic operation을 보장하기 때문에 트랜잭션을 보장받을 수 있어, 하나의 트랜잭션에 여러 개의 테이블로 나눠서 데이터를 보관하고 있을 경우, 하나의 테이블로 관리하여 정보를 변경하도록 한다.
- Index table
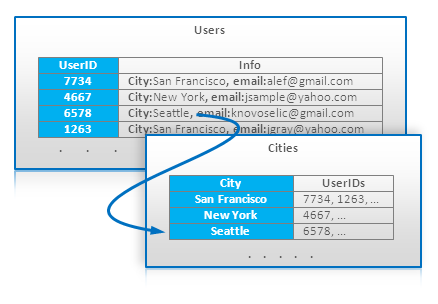
NoSQL은 RDBMS처럼 index가 없기 때문에, Key 이외의 속성값을 이용하여 조회를 하면, 전체 Table을 전부 조회하거나 아예 조회가 불가능하다.
이러한 문제를 해결하기 위한 방법으로 Index를 위한 별도의 Index Table을 만들어서 사용하는 경우를 말한다.
- CompositeKey
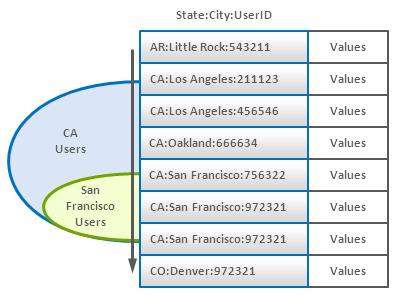
하나 이상의 필드를 구분자를 이용하여 구분지어 사용하는 방법으로 RDBMS의 복합키 (Composite primary Key)와 같은 개념으로 볼 수 있다.
- Inverted search index
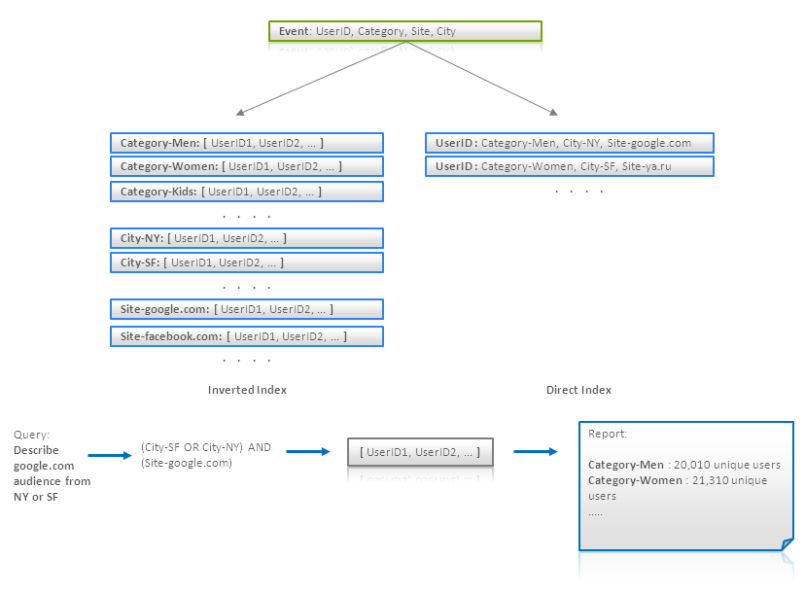
이 기법은 모델링이라기 보다는 데이터 처리 패턴에 조금 더 가깝다. 인덱스를 사용하여 특정한 기준에 맞춰 데이터를 찾도록 원본의 데이터의 표현 또는 전체 검색을 할 때 사용 된다.
계층형 데이터 모델링
1. Tree Aggregation

하나의 단일 Document 형태로 Tree구조 혹은 간단한 그래프 구조를 나타내도록 하는 방식을 말한다. 한 번에 블로그 글을 조회하거나 하는 방식에 매우 효과적이지만 내용을 자주 변경하거나 임의로 엑세스 하는 과정이 들어가는 경우 비효율적인 저장 방식이다.
적용 가능 : Key-Value Stores, Document Databases
2. Adjacency Lists
Adjancency List는 각 노드가 직접적으로 부모 노드, 또는 자식 노드의 배열을 포함하여 서로 의존적이지 않는 형태의 그래프 모델링입니다.
부모나 자식 노드의 식별자를 활용하여 검색할 수 있다. 하나의 노드로 전체 하위 노드의 정보를 가져오는데는 비효율적인 방법이다.
적용 가능 : Key-Value Stores, Document Databases
3. Materialized Paths
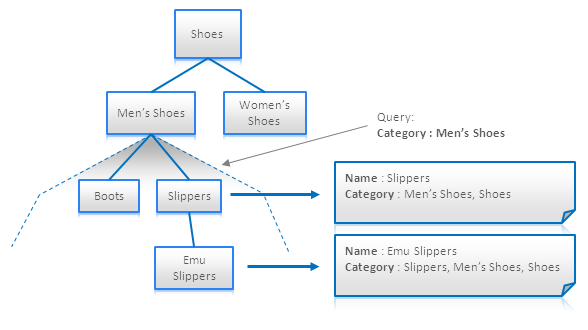
Meterialized Paths는 트리 구조처럼 순회하는 것을 방지해주는 방법이다. 각 노드는 각자 부모 또는 자식노드를 특정지을 수 있도록 만들어져 있다. 이러한 방식의 구조는 이 방법은 계층 구조를 무계층 문서로 변환할 수 있기 때문에 전체 텍스트 검색 엔진에 특히 좋은 성능을 발휘합니다.
적용 가능 : Key-Value Stores, Document Databases, Search Engines
4. Nested Sets
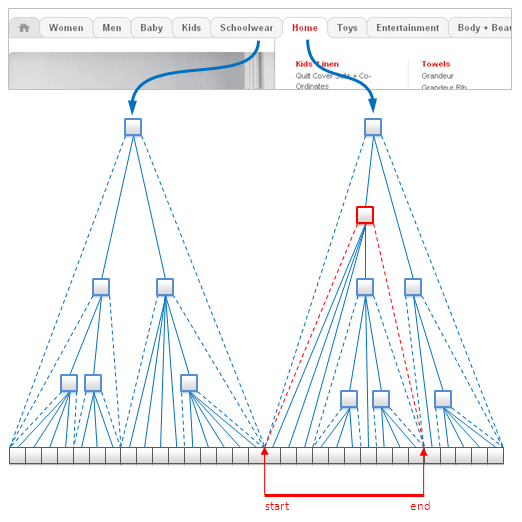
Nested Sets은 트리 같은 구조에서 기본적으로 사용이 되는 방법이다. 관계형 DB에서 넓게 사용이 되지만, Key-Value와 Document DB 에서도 완벽하게 사용하는 것이 가능하다. 이러한 구조는 그림과 같이 트리 구조의 리프를 배열에 저장하고 시작, 끝 인덱스를 사용하여 각 리프의 범위에 매핑하는 방식이다.
데이터의 양이 변하지 않는 상황일 경우 유용한 구조가 될 수 있지만 자주 삽입, 변경, 삭제가 일어나는 데이터의 경우에는 부적절한 방법이다.
적용 가능 : Key-Value Stores, Document Databases
출처
