순열
n개중 r를 뽑는 경우의 수 구할 때 순서를 고려해 뽑는다.
const permutation = (arr, selectNumber) => {
const result = [];
if (selectNumber === 1) return arr.map((e) => [e]);
arr.forEach((fixed, index, origin) => {
const fixer = fixed;
const restArr = origin.filter((e, i) => e !== fixer);
//const restArr = origin; // restArr만 바꿔주면 중복순열이 됨.
const permutaionArr = permutation(restArr, selectNumber - 1);
const combineFixer = permutaionArr.map((e) => [fixer, ...e]);
result.push(...combineFixer);
});
return result;
};
설명
- 한 개(selectNumber가 1이 된 경우)를 선택할 땐, 모든 배열의 원소를 하나씩 선택해 배열로 return하는 것이 재귀 종료 조건이다.
- 순열을 할 배열을 forEach문으로 돈다.
- 배열의 첫번째 값부터 차례대로 fixer에 저장하고 그걸 제외한 restArr을 만든다. 첫번째 값을 제외하지 않은 restArr을 사용할 경우 중복순열이 된다.
- permutaitionArr에 restArr과 selectNumber-1을 인수로 재귀를 실행한다. 이게 반복이 되다가 selectNumber가 1이 되면 리턴이 시작되어 되돌아온다.
- combineFixer에 되돌아 온 permutaitionArr에 fixer와 합치는 작업을 한다.
여기부턴 다른글에 작성했던 이진탐색 알고리즘을 활용하는 코드가 나온다. 이진트리탐색
다른 버전 (중복 순열)
깊이 우선 탐색을 이용한 방법이다.
const permutation2 = (n, m) => {
let answer = [];
let tmp = new Array(m).fill(0); // 삽입용
function dfs(L) {
if (L === m) {
answer.push([...tmp]);
} else {
for (let i = 1; i <= n; i++) {
tmp[L] = i;
dfs(L + 1);
}
}
}
dfs(0);
return answer;
};설명
- 1부터 n까지 m개를 뽑는 중복순열이다.
- dfs의 매개변수 L은 Level을 뜻하며 이진트리에서 얼마나 내려갈 것인지를 판단할 수 있는 변수이다.
- 내부함수 dfs에 if문 조건이 L === m인 이유는 m개만 뽑기 때문이다.
funnction dfs(L) {
if(L ===m-1)
else
}
dfs(1);
dfs(1)부터 한다면 이런식이 되는 것이다.
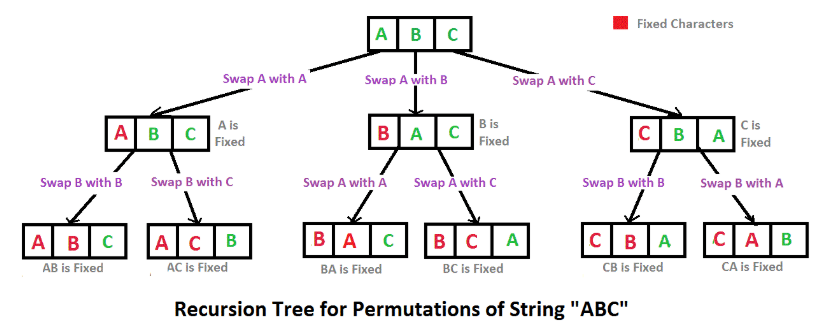
Level 변수를 쉽게 이해 할 수 있는 이미지를 찾았다.
다른 버전 순열(중복x)
깊이 우선 탐색을 이용한 방법이다.
const permutation3 = (m, arr) => {
let answer = [];
let n = arr.length;
let check = new Array(n).fill(0);
let tmp = new Array(m).fill(0);
function dfs(L) {
if (L === m) {
answer.push([...tmp]);
} else {
for (let i = 0; i < n; i++) {
if (check[i] === 0) {
check[i] = 1;
tmp[L] = arr[i];
dfs(L + 1);
check[i] = 0;
}
}
}
}
dfs(0);
return answer;
};설명
- 배열의 요소를 m개씩 중복없이 순열을 만드는 함수이다.
- 앞서 설명했지만 내부함수 dfs의 L은 레벨을 의미하고 이진트리를 놓고 봤을 때 얼마나 안으로 들어갈지를 판단해준다.
- arr과 같은 길이의 check 배열을 만들고 이미 사용했다면 1을 할당, 사용 이후 0을 할당해준다.
dfs의 재귀 호출 이전는 사용전 인거고 이후는 사용 이후가 된다. 이 로직을 잘 이해해야 한다.
- tmp배열을 다시 설명하자면 m과 같은 길이의 배열이고 answer배열에 넣는 삽입용이다.
tmp[L] = arr[i]tmp배열에 arr의 요소중 사용하지 않았던 요소를 넣고 그것을 후에 answer에 push해준다.
조합
n개 중 r개를 뽑는 경우의 수 구할 때 순서를 고려하지 않는다.
const Combinations = function (arr, selectNumber) {
const results = [];
if (selectNumber === 1) return arr.map((e) => [e]); // 1개씩 택할 때, 바로 모든 배열의 원소 return
arr.forEach((element, index, origin) => {
const fixed = element;
const rest = origin.slice(index + 1); // fixed의 인덱스 다음부터 남게 만드는.
const combinationArr = Combinations(rest, selectNumber - 1); // 나머지에 대해서 조합을 구한다.
const attached = combinationArr.map((e) => [fixed, ...e]); // 돌아온 조합에 떼 놓은(fixed) 값 붙이기
results.push(...attached); // 배열 spread syntax 로 모두 다 push
});
return results; // 결과가 담긴 results를 return
};설명
- 배열에서 selectNumber갯수를 뽑아 만드는 조합.
- 순열과 비슷한 원리
- 1개를 뽑는 경우(selectNumber가 1이된 경우) 배열의 모든 원소를 각각 배열에 담아 return
- 조합은 순서를 고려치 않음으로 (1,2) 와 (2,1)이 같은 것이 된다. 따라서 rest 배열은 fixed의 다음 인덱스부터 끝까지 남긴 배열이 된다.
다른버전 조합
이진트리탐색 탐색을 이용한 방법
const combination2 = (n, m) => {
let answer = [];
let tmp = new Array(m).fill(0); // 삽입용
function DFS(L, s) {
// s는 level보다 1크게
if (L === m) {
answer.push([...tmp]);
} else {
for (let i = s; i <= n; i++) {
tmp[L] = i;
DFS(L + 1, i + 1);
}
}
}
DFS(0, 1);
return answer;
}
설명
- 1부터 n까지 m개 뽑는 조합이다.
- 원래 조합 알고리즘에서 설명한 rest를 만들어 내기 위해 s라는 변수를 L(level)변수보다 1크게 설명을 하여 s부터 반복문이 돌게하는 방법이다.
- L이 0일 경우 반복문은 1부터 n까지이고 L이 1일 경우 반복문은 2부터 n까지가 된다.
- 1을 사용한 가닥으로 뻗어나가면 다음은 2부터 들어가게 되는 것이다.
제너레이터
const permutations = function* (elements, selectNumber) {
if (selectNumber === 1) {
yield elements.map((e) => e);
} else {
const [first, ...rest] = elements;
for (const a of permutations(rest, selectNumber - 1)) {
for (let i = 0; i < elements.length; i++) {
const start = a.slice(0, i);
const ended = a.slice(i);
yield [...start, first, ...ended];
}
}
}
};- 제너레이터를 이용한 순열
- 반환되는 결과물이 이터러블이기 때문에 for of 나 ...연산자를 사용 할 수 있다.
const combinations = function* (elements, selectNumber) {
for (let i = 0; i < elements.length; i++) {
if (selectNumber === 1) {
yield [elements[i]];
} else {
const fixed = elements[i];
const rest = combinations(elements.slice(i + 1), selectNumber - 1);
for (const a of rest) {
yield [fixed, ...a];
}
}
}
};- 제너레이터를 이용한 조합
- 반환되는 결과물이 이터러블이기 때문에 for of 나 ...연산자를 사용 할 수 있다.

음악하는 개발자