키-값 저장소 설계
- key-value 저장소는 NoSQL 중 하나이다.
- 이 저장소에 저장되는 값은 고유 식별자를 키로 가져야 한다.
- 키는 텍스트일 수도, 해시 값일수도 있다.
- 당연히 키는 짧을수록 좋을 것이다.(성능상)
- 완벽한 설계는 없다.
단일 서버 키-값 저장소
- 직관적인 방법 : 키-값 전부를 메모리에 해시 테이블로 저장
- 장점 : 빠른 속도
- 단점 : 모든 데이터를 메모리에 두는 것이 불가능 할 수 있다.
- 해결책
- 데이터 압축
- 자주 쓰이는 데이터만 메모리에 두고 나머지는 디스크에 저장
분산 키-값 저장소
분산 해시 테이블이라고도 불리는데, 이는 키-값 쌍을 여러 서버에 분산시키기 때문이다.
이를 설계하기 위해서는 CAP(Consistency, Availability, Partition Tolerance Theorem)정리를 이해하고 있어야 한다.
CAP정리
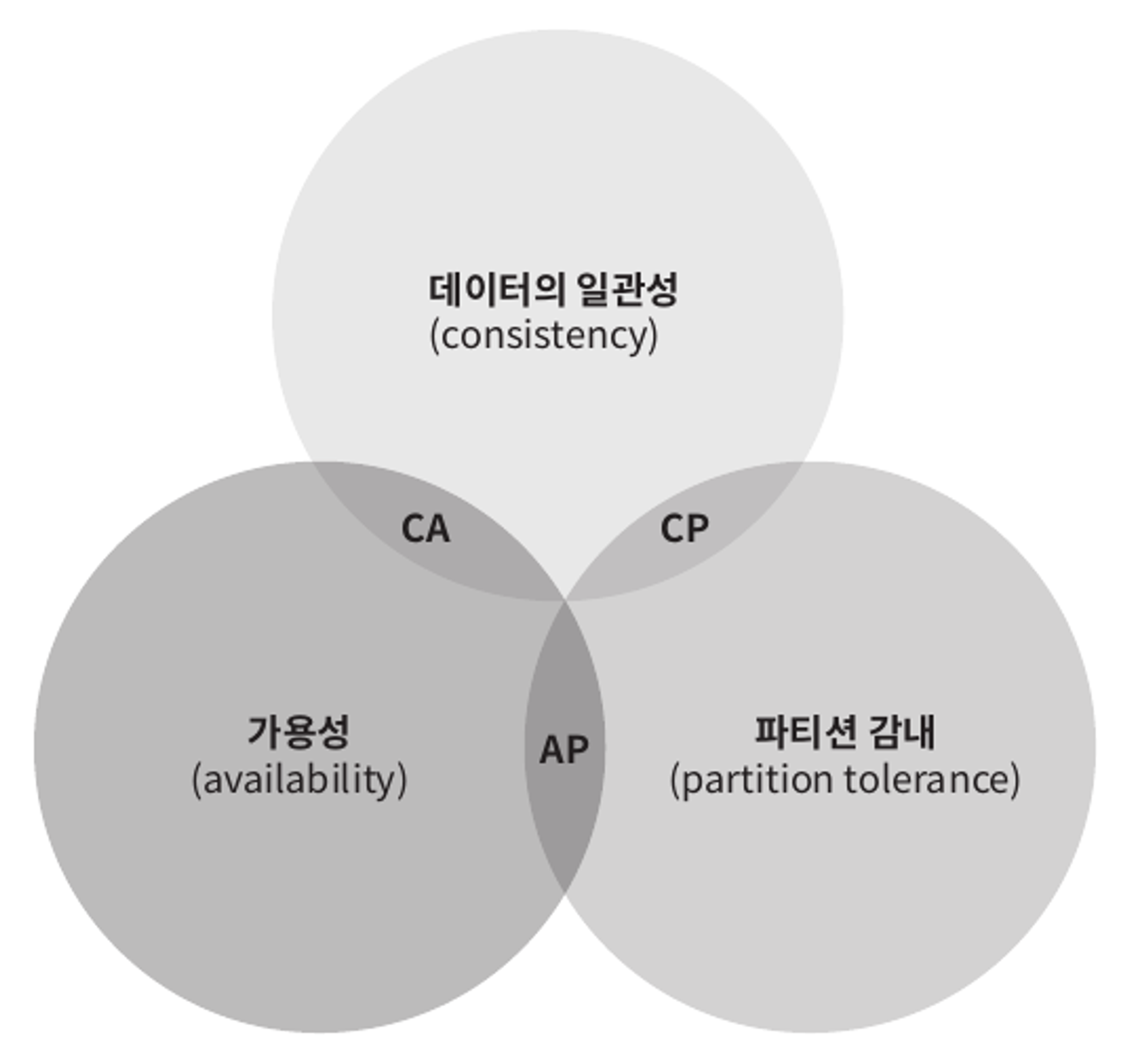
데이터 일관성, 가용성, 파티션 감내 라는 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것은 불가능하다는 정리이다.
먼저 각 요구사항의 의미를 명확히 하자면
데이터 일관성(C)
분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐와 관계 없이 언제나 같은 데이터를 보게 되어야 한다.
가용성(A)
분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
파티션 감내(P)
파티션은 두 노드 사이에 통신 장애가 발생하였음을 의미한다.
즉, 파티션 감내는 네트워크에 파티션이 생기더라도 시스템이 계속 동작해야 한다는 것을 뜻한다.
여기서 2가지를 충족하려면, 나머지 하나는 반드시 희생되어야 한다.
위의 세 요구사항 중 어떤 두 가지를 만족하냐에 따라 다음과 같이 분류할 수 있다.
- CP시스템
- AP시스템
- CA시스템
- 다만 통상 네트워크 장애는 피할 수 없는 것으로 여겨지기 때문에 분산시스템은 반드시 파티션 문제를 감내할 수 있도록 설계되어야 한다.
- 따라서
CA시스템은 실질적으로존재하지 않는다.
이에 관한 몇 가지 사례를 살펴본다.
분산 시스템에서 데이터는 보통 여러 노드에 복제되어 보관된다.
세 개의 복제 노드 n1, n2, n3에 데이터를 복제하여 보관하는 상황이 있다고 한다.
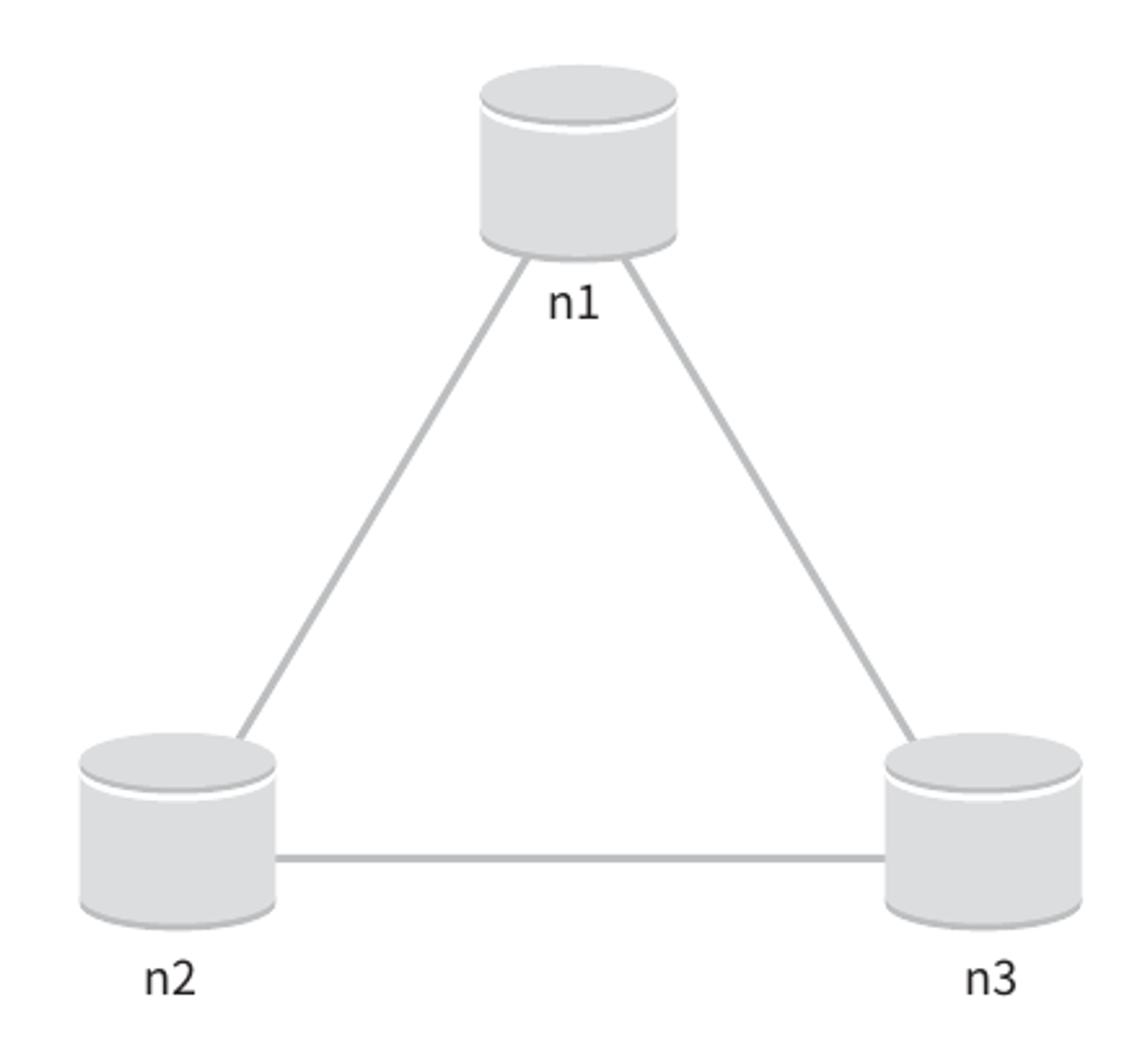
이상적 환경이라면 네트워크가 파티션되는 상황은 절대로 일어나지 않을 것이다.
n1에 기록된 데이터는 자동적으로 n2, n3에 복제된다.
이는 데이터 일관성과 가용성도 만족한다.
분산 시스템은 파티션 문제를 피할 수 없다.
그리고 파티션 문제가 발생하면 우리는 일관성과 가용성 사이에서 하나를 선택하여야 한다.
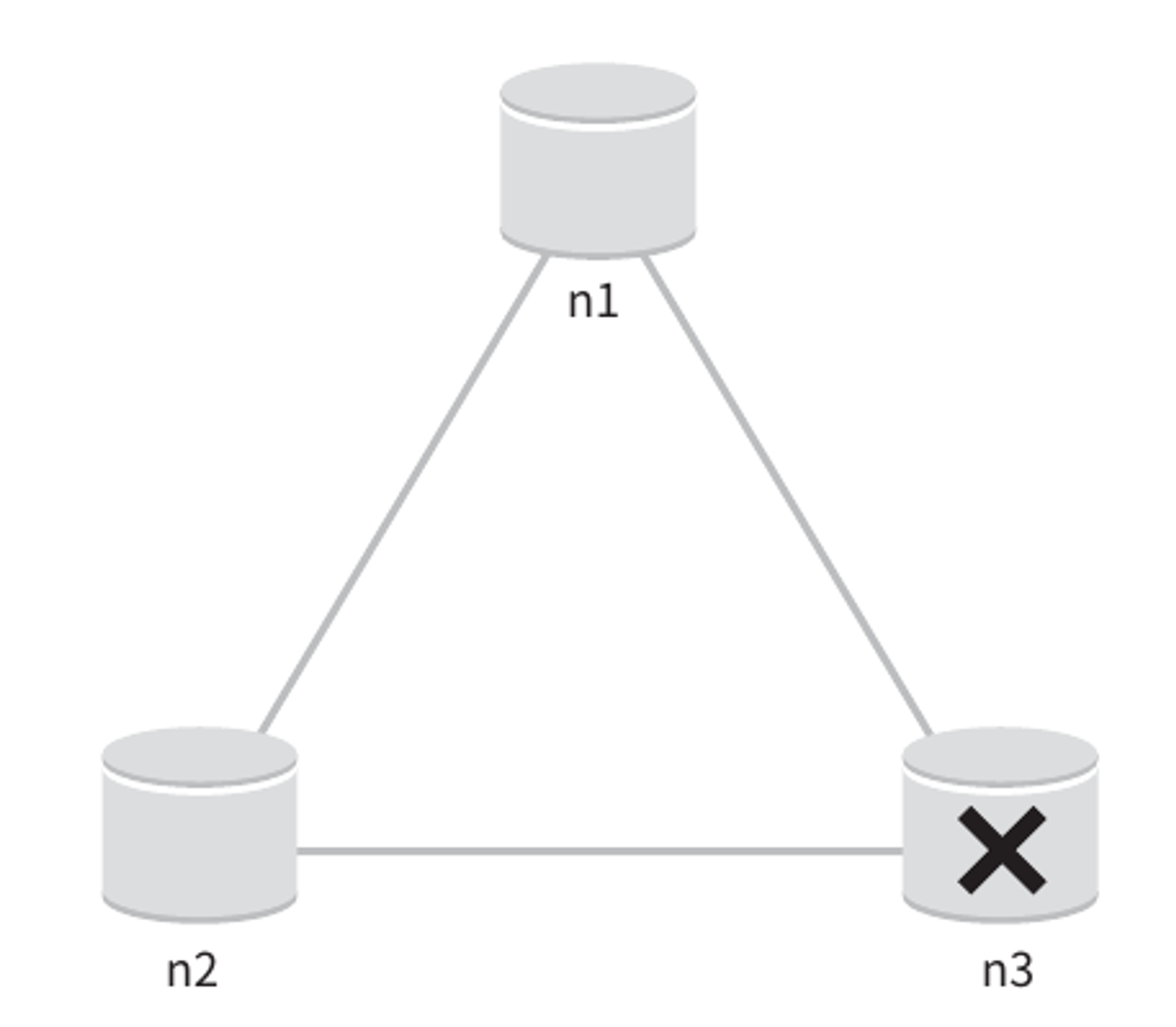
여기서는 n3에 장애가 발생하여 n1및 n2와 통신할 수 없는 상황을 보여준다.
클라이언트가 n1또는 n2에 기록한 데이터가 n3에 전달되지 않는다.
가용성 대신 일관성을 선택했다면(CP시스템) 세 서버 사이에 생길 수 있는 데이터 불일치 문제를 피하기 위해 n1과 n2에 대해 쓰기 연산을 중단시켜야 하는데, 그렇게 하면 가용성이 깨진다.
만약에 일관성이 깨질 수 있는 상황이 발생하면 이런 시스템인 상황이 해결될 때 까지는 오류를 반환해야 한다.
반대로 일관성 대신 가용성을 선택한다면(AP시스템) 낡은 데이터를 반환할 위험이 있다고 해도 계속 읽기 연산을 허용해야 한다.
그리고 n1과 n2에서는 계속 쓰기 연산을 허용할 것이고, 파티션 문제가 해결된 후에 새 데이터를 n3에 전송할 것이다.
분산 키-값 저장소를 만들 때에는 그 요구사항에 맞도록 CAP정리를 적용해야 한다.
시스템 컴포넌트
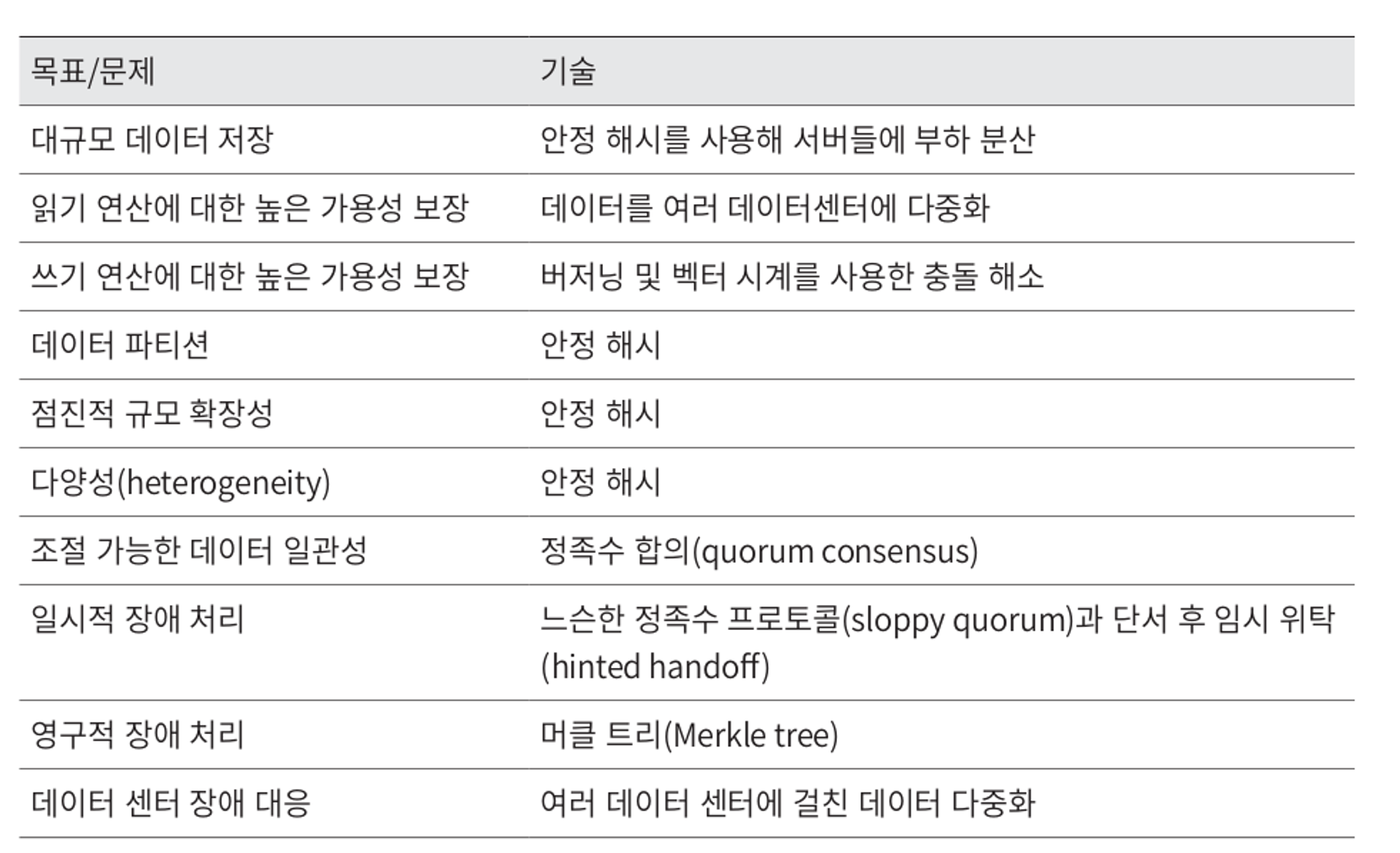
키-값 저장소 구현에 사용될 핵심 컴포넌트 및 기술
- 데이터 파티션
- 데이터 다중화
- 일관성
- 일관성 불일치 해소
- 장애 처리
- 시스템 아케텍처 다이어그램
- 쓰기 경로
- 읽기 경로
데이터 파티션
데이터를 작은 파티션들로 분할한 다음 여러 대의 서버에 저장하는 방식이다.
데이터를 파티션 단위로 나눌 때는 다음 두 가지 문제를 중요하게 살펴보아야 한다.
- 데이터를 여러 서버에
고르게 분산할 수 있는가 노드가 추가되거나 삭제될 때데이터의 이동을 최소화할 수 있는가
이전에 배운 안정 해시는 이런 문제를 푸는 데 적합한 기술이다.
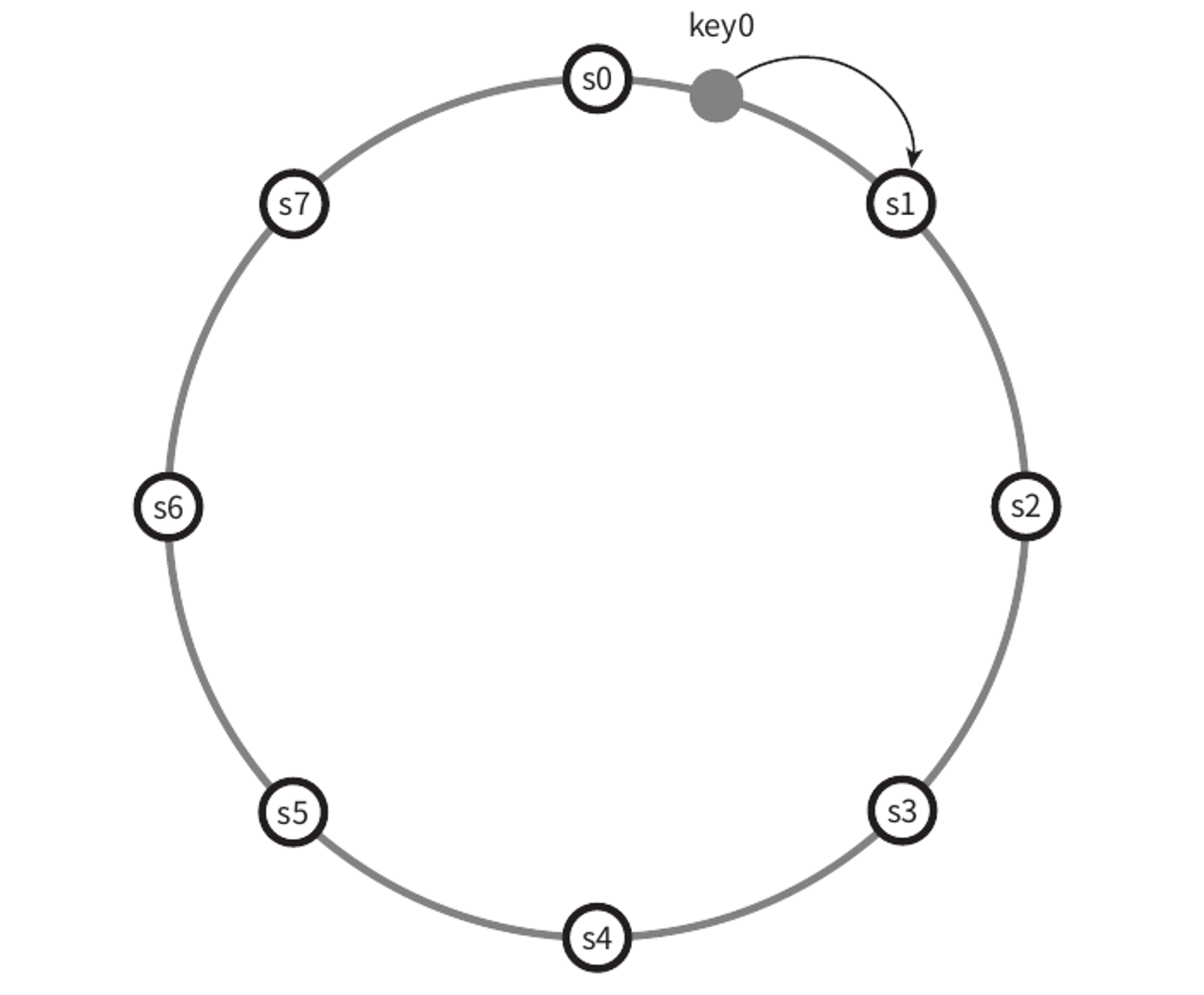
- 서버를 해시링에 배치한다. 여기는 s0~ s7의 여덟 개 서버가 있다.
- 어떤 키-값 쌍을 어떤 서버에 저장할지 결정하려면 우선 해당 키를 같은 링 위에 배치한다.
- 그 지점으로부터 링을 시계 방향으로 순회하다가 만나는 첫번째 서버가 바로 해당 키-값쌍을 저장할 서버이다.
이 장점은 다음과 같다.
규모 확장 자동화
시스템 부하에 따라 서버가 자동으로 추가되거나 삭제될 수 있다.
다양성
각 서버의 용량에 맞게 가상 노드의 수를 조정할 수 있다.
다시 말해, 고성능 서버는 더 많은 가상 노드를 갖도록 설정할 수 있다.
데이터 다중화
높은 가용성과 안정성을 확보하기 위해서는 데이터를 N개 서버에 비동기적으로 다중화할 필요가 있다.
여기서 N은 튜닝 가능한 값이다.
N개 서버를 선정하는 방법은 어떤 키를 해시 링 위에 배치한 후, 그 지점으로부터 시계 방향으로 링을 순회하면서 만나는 첫 N개 서버에 데이터 사본을 보관하는 것이다.
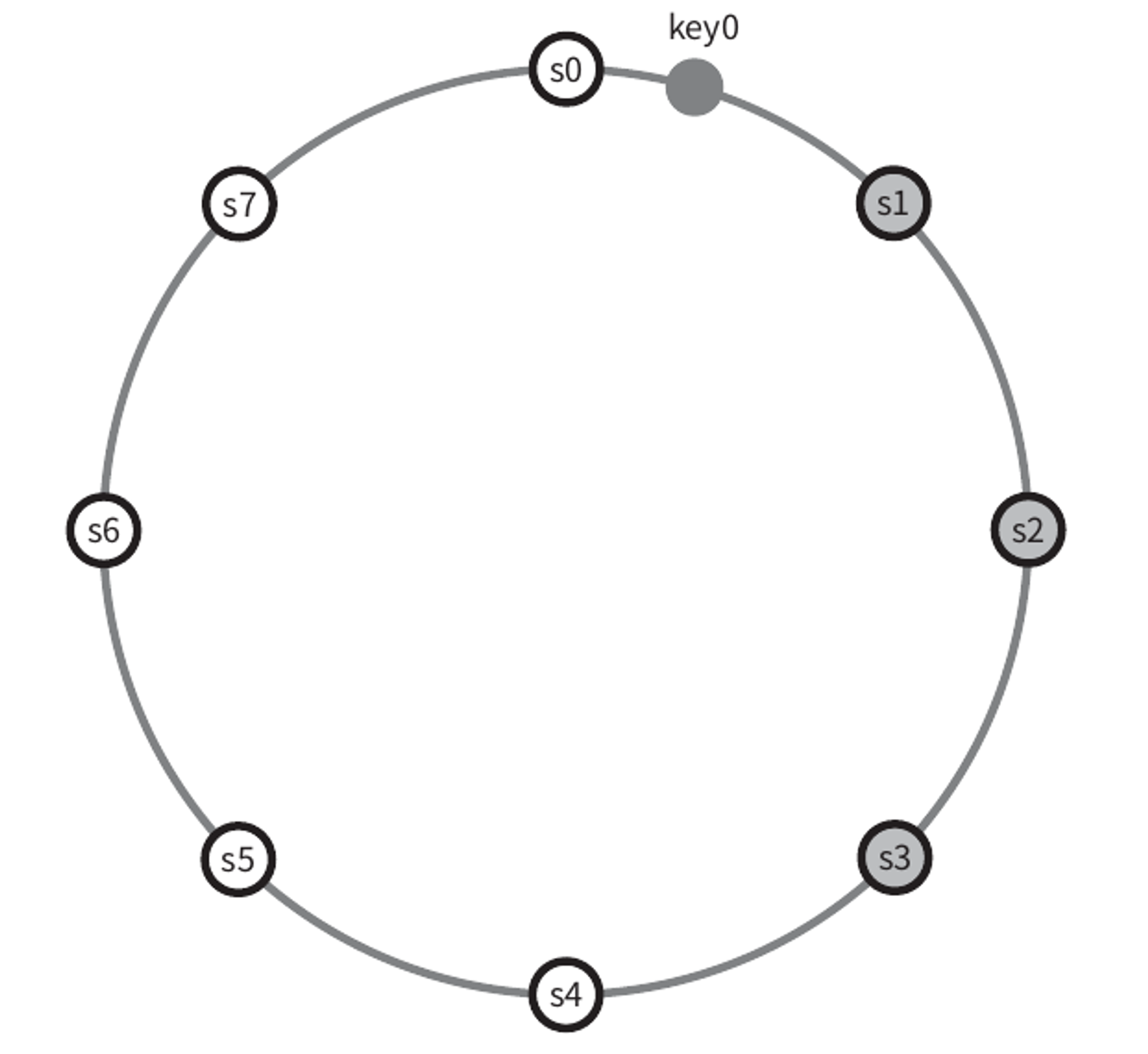
따라서 N=3으로 설정한 이 예제에서 key0은 s1, s2, s3에 보관된다.
그런데 가상 노드를 사용한다면 위와 같이 선택한 N개의 노드가 대응될 실제 물리 서버의 개수가 N보다 작아질 수 있다.
이를 해결하기 위해서는 같은 물리 서버를 중복 선택하지 않도록 해야 한다.
같은 데이터 센터에 속한 노드는 정전, 네트워크 이슈 등의 문제를 동시에 겪을 가능성이 있다.
따라서 안정성을 담보하기 위해 데이터의 사본은 다른 센터의 서버에 보관하고, 센터들은 고속 네트워크로 연결한다.
데이터 일관성
여러 노드에 다중화된 데이터는 적절히 동기화가 되어야 한다.
정족수 합의(Quorum Consensus) 프로토콜을 사용하면 읽기/쓰기 연산 모두에 일관성을 보장할 수 있다.
우선 관계된 정의부터 몇 가지 살펴보자
- N = 사본 개수
- W = 쓰기 연산에 대한 정족수. 쓰기 연산이 성공한 것으로 간주되려면 적어도 W개의 서버로부터 쓰기 연산이 성공했다는 응답을 받아야 한다.
- R = 읽기 연산에 대한 정족수. 읽기 연산이 성공한 것으로 간주되려면 적어도 R개의 서버로부터 응답을 받아야 한다.
- 정족수 : 여러 사람의 합의로 운영되는 의사기관에서 의결을 하는데 필요한
최소한의 참석자 수
- 정족수 : 여러 사람의 합의로 운영되는 의사기관에서 의결을 하는데 필요한
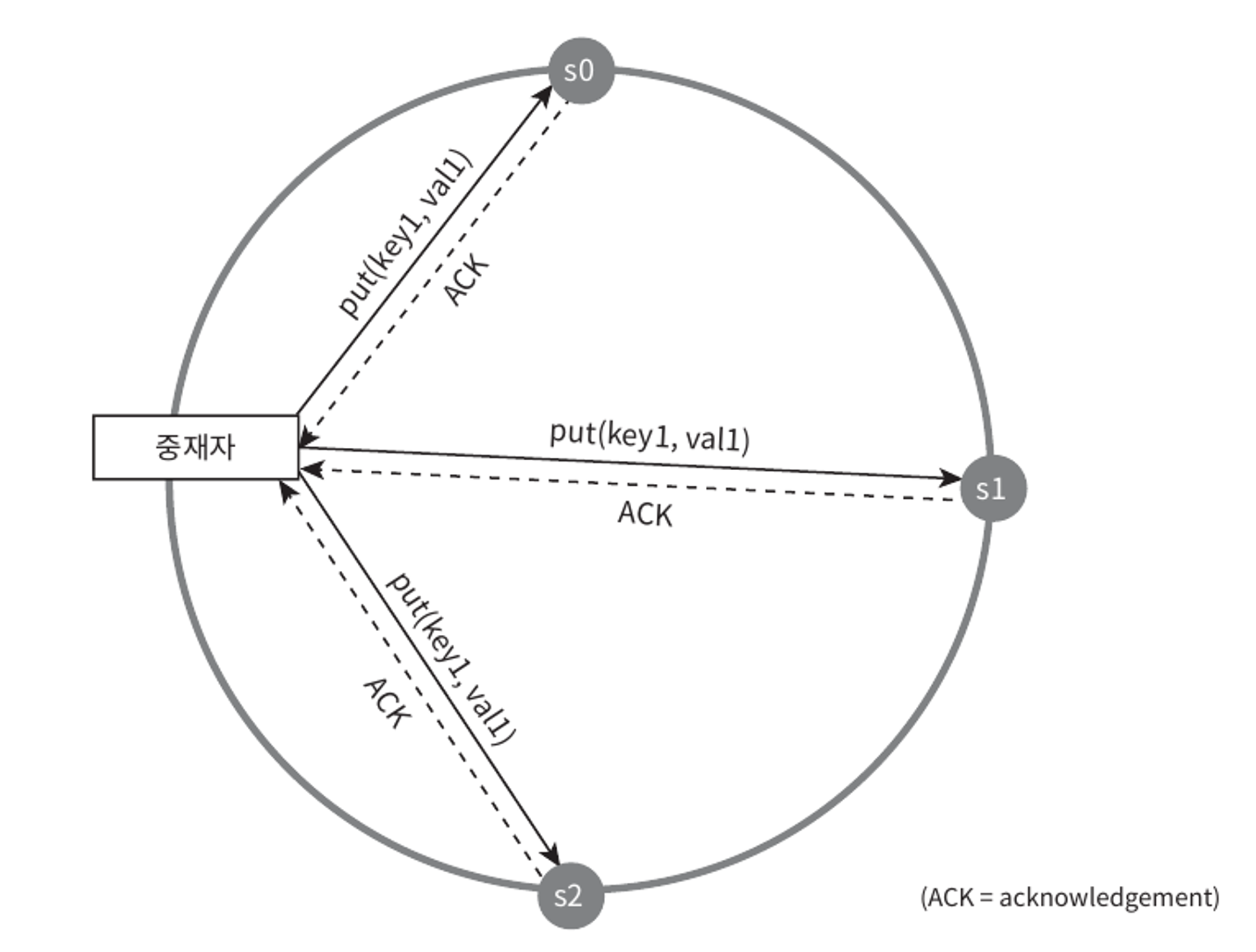
N = 3인 경우에 대해
W = 1은 데이터가 한 대 서버에만 기록된다는 뜻이 아니다.
위의 사진처럼 데이터가 s0, s1, s2에 다중화되는 상황을 예로 들자면
W = 1의 의미는, 쓰기 연산이 성공했다고 판단하기 위해 중재자는 최소 한 대의 서버로부터 쓰기 성공 응답을 받아야 한다는 것이다.
즉, s1으로부터 성공 응답을 받았다면 s0, s2로부터의 응답을 기다릴 필요는 없다.
W, R, N의 값을 정하는 것은 응답 지연과 데이터 일관성 사이의 타협점을 찾는 전형적인 과정이다.
- R = 1, W = N : 빠른 읽기 연산에 최적화된 시스템
- W = 1, R = N : 빠른 쓰기 연산에 최적화된 시스템
- W + R > N : 강한 일관성 보장
- W + R <= N : 강한 일관성의 보장이 없다.요구되는 일관성 수준에 따라 조정하면 된다.
일관성 모델
일관성 모델은 데이터 일관성의 수준을 결정하는데, 종류가 다양하다.
강한 일관성
- 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환한다. 다시 말해서 클라이언트는 절대로 낡은 데이터를 보지 못한다.
- 현재 쓰기 연산의 결과가 반영될 때 까지 해당 데이터에 대한 읽기/쓰기를 금지하는 것이다.
- 새로운 요청의 처리가 중단되기 때문에 고가용성 시스템에 적합하지 않다.
약한 일관성
- 읽기 연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있다.
최종 일관성
- 약한 일관성의 한 형태로, 갱신 결과가 결국에는 모든 사본에 반영(동기화) 되는 모델이다.
- 쓰기 연산이 병렬적으로 발생하면 시스템에 저장된 값의 일관성이 깨질 수 있다.
- 이 문제는 클라이언트가 해결해야 한다.
클라이언트 측에서 데이터의 버전 정보를 활용해 일관성이 깨진 데이터를 읽지 않도록 하기 위해서 살펴본다.
비 일관성 해소 기법 : 데이터 버저닝
버저닝과 벡터 시계는 그 문제를 해소하기 위해 등장한 기술이다.
버저닝은 데이터를 변경할 때마다 해당 데이터의 새로운 버전을 만드는 것을 의미한다.
따라서 각 버전의 데이터는 변경 불가능하다.
<데이터 일관성이 깨지는 과정>
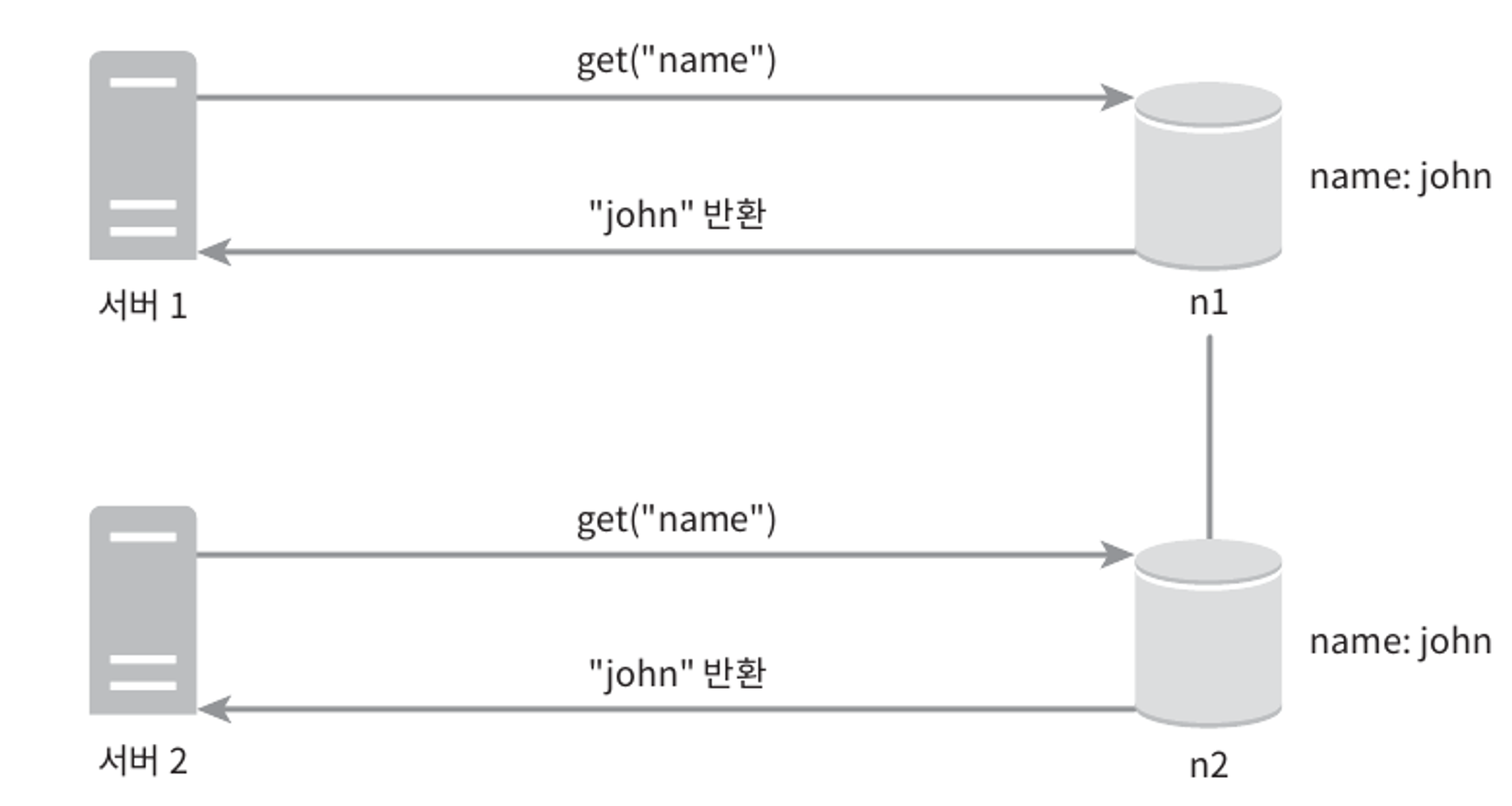
이렇게 어떤 데이터의 사본이 노드 n1과 n2에 보관되어 있다고 한다.
이 데이터를 가져오려는 서버1과 서버2는 get("name")의 결과로 같은 값을 얻는다.
이번에는 서버1은 "name"에 매달린 값을 "johnSanFrancisco"로 바꾸고, 서버2는 "johnNewYork"로 바꾼다고 한다.
그리고 이 두 연산은 동시에 이루어진다고 하자.
이제 우리는 충돌하는 두 값을 갖게 되었다. 각각을 v1, v2라고 하자.
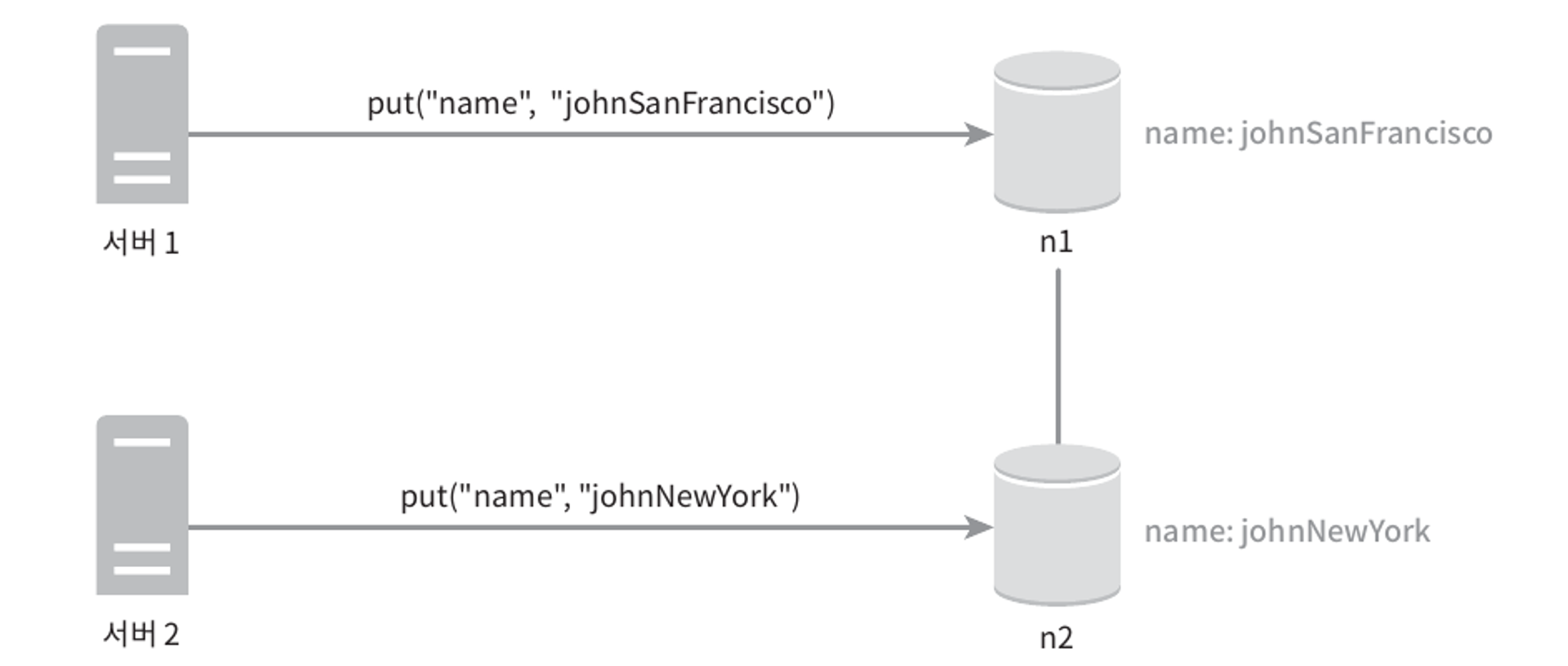
이 문제를 해결하려면 충돌을 발견하고 자동으로 해결해 낼 버저닝 시스템이 필요하다.
벡터 시계는 이런 문제 해결에 보편적으로 사용되는 기술이다.
벡터 시계는 [서버, 버전]의 순서쌍을 데이터에 매단 것이다.
어떤 버전이 선행 버전인지, 후행 버전인지, 아니면 다른 버전과 충돌이 있는지 판별하는 데에 쓰인다.
벡터 시계는 D([S1, v1], [S2, v2] ... [Sn, vn])와 같이 표현한다고 가정하자.
D는 데이터, vi는 카운터, si는 서버 번호이다.
만일 데이터 D를 서버 Si에 기록하면, 시스템은 아래 작업 가운데 하나를 수행해야 한다.
- [Si, vi]가 있다면 vi를 증가시킨다.
- 그렇지 않으면 새 항목[Si, 1]를 만든다.이 추상적 로직이 실제로 어떻게 수행되었는지를 구체적 사례를 통해 알아본다.
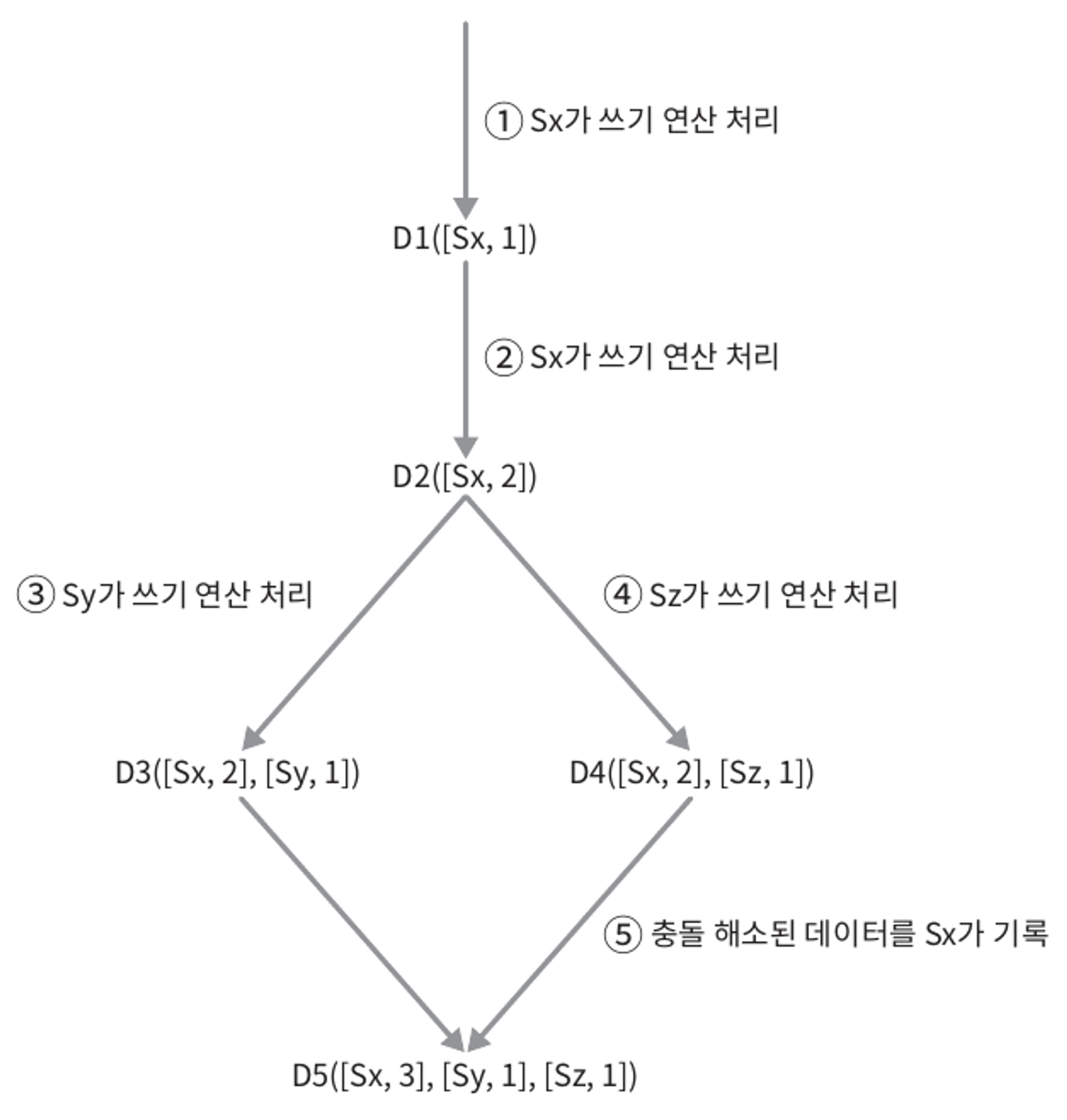
- 클라이언트가 데이터 D1을 시스템에 기록한다. 이 쓰기 연산을 처리한 서버는 Sx이다. 따라서 벤터 시계는 D1[(Sx, 1)]으로 변한다.
- 다른 클라이언트가 데이터 D1을 읽고 D2로 업데이트 한 다음 기록한다. D2는 D1에 대한 변경이므로 D1을 덮어쓴다.이 때 쓰기 연산은 같은 서버 Sx가 처리한다고 가정하자. 벡터 시계는 D2([Sx, 2])로 바뀔 것이다.
- 다른 클라이언트가 D2를 읽어 D3로 갱신한 다음 기록한다. 이 쓰기 연산은 Sy가 처리한다고 가정하자. 벡터 시계 상태는 D3([Sx, 2], [Sy, 1]])로 바뀐다.
- 또 다른 클라이언트가 D2를 읽고 D4로 갱신한 다음 기록한다. 이 때 쓰기 연산은 서버 Sz가 처리한다고 가정하자. 벡터 시계는 D4([Sx, 2], [Sz, 1])일 것이다.
- 어떤 클라이언트가 D3와 D4를 읽으면 데이터 간 충돌이 있다는 것을 알게 된다. D2를 Sy와 Sz가 각기 다른 값으로 바꾸었기 때문이다. 이 충돌은 클라이언트가 해소한 후에 서버에 기록한다. 이 쓰기 연산을 처리한 서버는 Sx였다고 하자. 벡터 시계는 D5([Sx, 3], [Sy, 1], [Sz, 1])로 바뀐다. 충돌이 있어났다는 것을 어떻게 감지하는지는 잠시 후에 더 자세히 살펴볼 것이다.
벡터 시계를 사용하면 어떤 버전 X가 버전 Y의 이전 버전인지(따라서 충돌이 없는지) 쉽게 판단할 수 있다.
버전 Y에 포함된 모든 구성요소의 값이 X에 포함된 모든 구성요소 값보다 같거나 큰지만 보면 된다.
예를 들어 벡터 시계 D([S0, 1], [s1, 1])은 D([s0, 1], [s1, 2])의 이전 버전이다. 따라서 두 데이터 사이에 충돌은 없다.
버전 X와 Y사이에 충돌이 있는지 보려면 Y의 벡터 시계 구성요소 가운제 X의 벡터 시계 동일 서버 구성요소보다 작은 값을 갖는 것이 있는지 확인해 보면 된다.
이 방식에는 두 가지 단점이 있다.
- 충돌 감지 및
해소 로직이 클라이언트에들어가야 하므로, 클라이언트 구현이 복잡해진다. - [서버:버전] 의 순서쌍 개수가 굉장히 빨리 늘어난다.
장애 처리
이번에 장애 감지 기법에 대해 알아보고, 다음으로 장애 해소 전략을 짚어본다.
장애 감지
분산 시스템에서는 그냥 서버 한대가 죽었다고 "지금 서버 A가 죽었습니다." 라고 해서 바로 서버 A를 장애처리 하지 않는다.
보통 두 대 이상의 서버가 똑같이 서버 A의 장애를 보고해야 실제로 해당 서버에 장애가 발생했다고 간주한다.
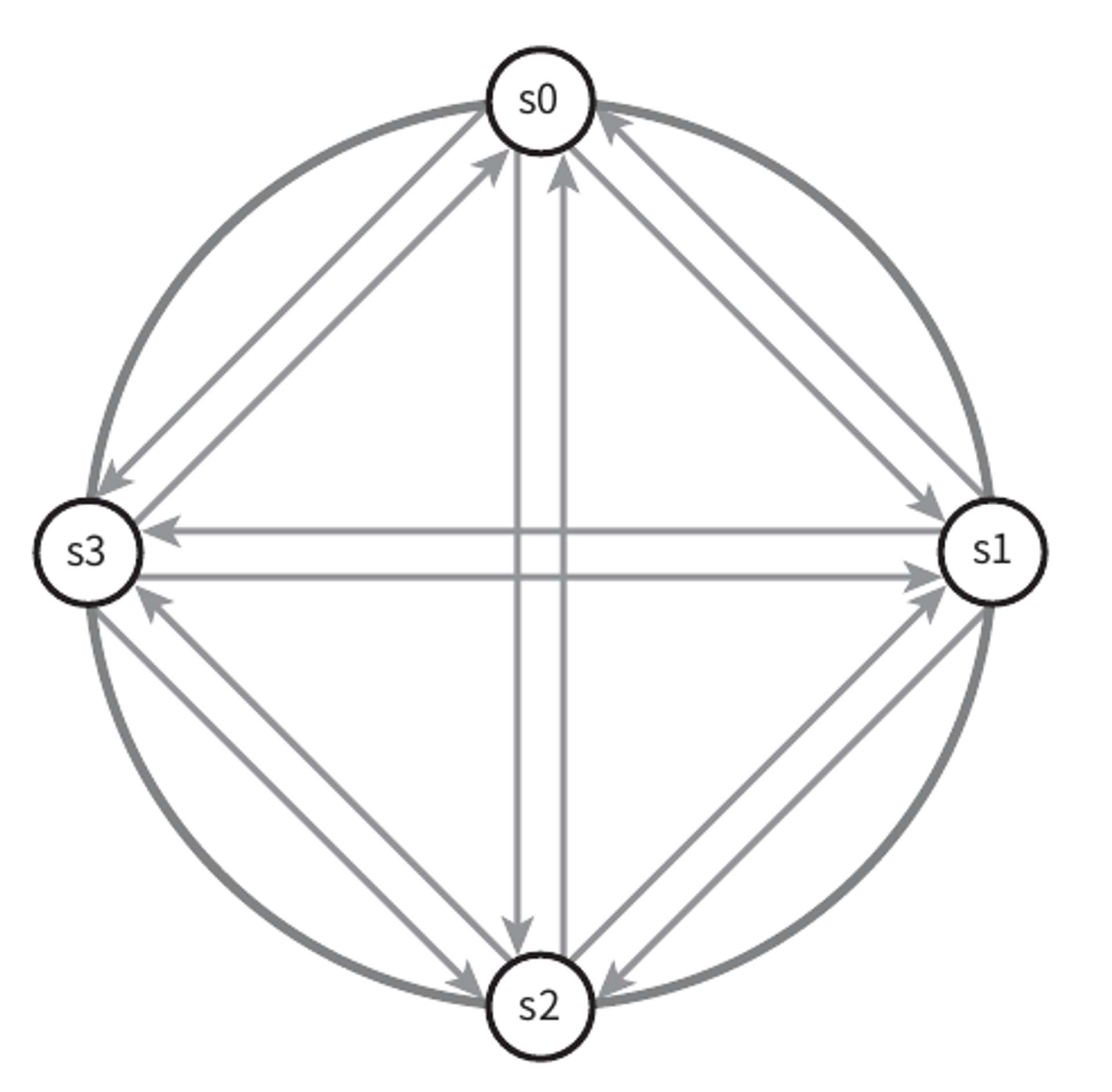
모든 노드 사이에 멀티캐스팅 채널을 구축
- 서버가 많을 때에는 비효율적
가십 프로토콜같은 분산형 장애 감지 솔루션을 채택하는 편이 더 효육적이다.
가십 프로토콜의 동작 원리는 다음과 같다.
- 각 노드는 멤버십 목록을 유지한다. 멤버십 목록은 각 멤버 Id와 그 박동 카운터 쌍의 목록이다.
- 각 노드는 주기적으로 자신의 박동 카운터를 증가시킨다.
- 각 노드는 무작위로 선정된 노드들에게 주기적으로 자기 박동 카운터 목록을 보낸다.
- 박동 카운터 목록을 받은 노드는 멤버십 목록을 최신 값으로 갱신한다.
- 어떤 멤버의 박동 카운터 값이 지정된 시간 동안 갱신되지 않으면 해당 멤버는 장애 상태인 것으로 간주한다.
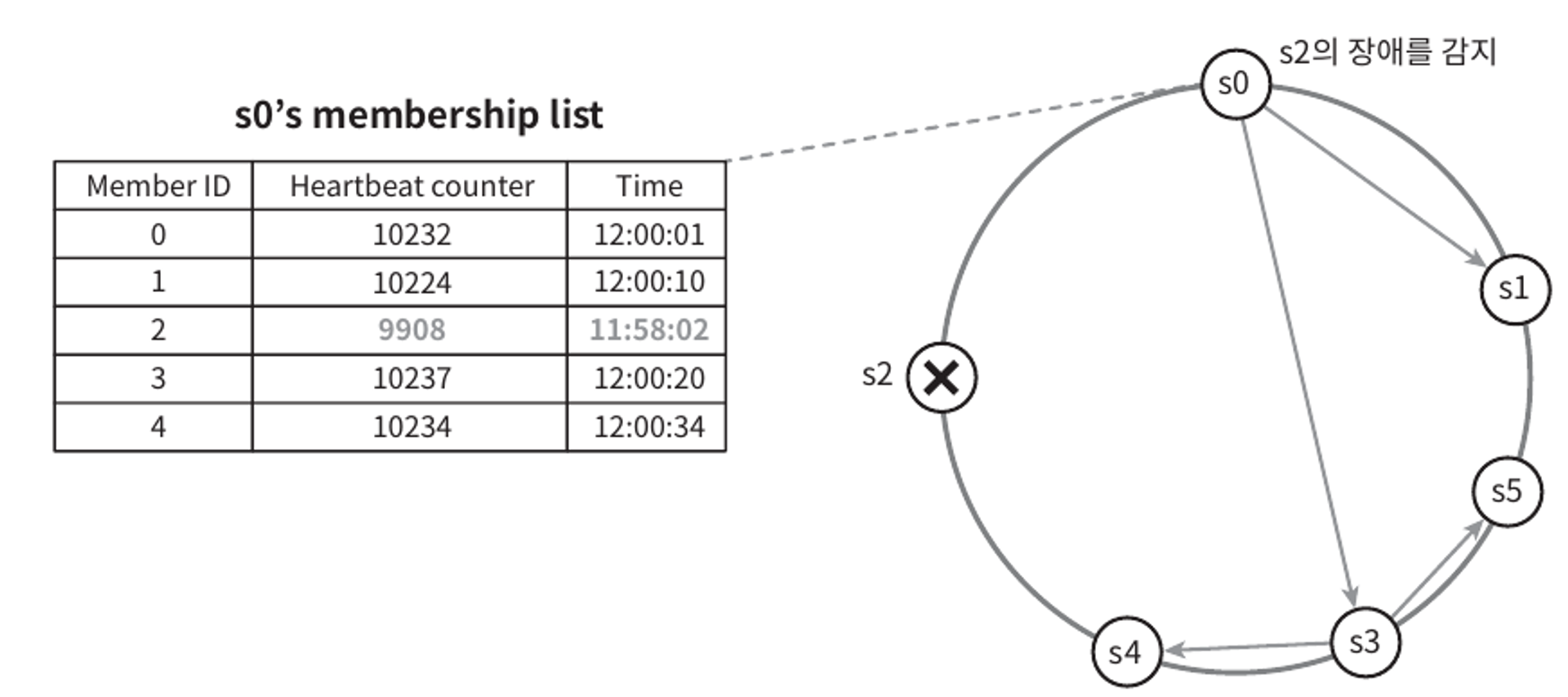
이 예제에서
- 노드 s0은 그림 좌측의 테이블과 같은 멤버십 목록을 가진 상태이다.
- 노드 s0은 노드 s2(멤버ID=2)의 박동 카운터가 오랫동안 증가되지 않았다는 것을 발견한다.
- 노드 s0은 노드 s2를 포함하는 박동 카운터 목록을 무작위로 선택된 다른 노드에게 전달한다.
- 노드 s2의 박동 카운터가 오랫동안 증가되지 않았음을 발견한 모든 노드는 해당 노드를 장애 노드로 표시한다.
일시적 장애 처리
가십 프로토콜로 장애를 감지한 시스템은 가용성을 보장하기 위한 조치를 해야 한다.
엄격한 정족수 접근법 : 읽기와 쓰기 연산을 금지
느슨한 정족수 접근법 : 읽기와 쓰기 연산을 금지 조건을 완화하여 가용성을 높인다.
정족수 요구사항을 강제하는대신, 쓰기 연산을 수행할 W개의 건강한 서버와 읽기 연산을 수행할 R개의 건강한 서버를 해시 링에서 고른다. 이 때 장애 상태인 서버는 무시한다.
장애 서버로 가는 요청은 다른 서버에서 처리한다.
그동안의 변경사항은 해당 서버 복구 시 일괄로 반영하여 일관성을 높인다.
이를 위해 임시로 쓰기 연산을 처리한 서버에서 hint를 남기고, 이를 단서 후 임시 위탁이라 한다.

영구 장애 처리
영구 장애 처리는 반-엔트로피 프로토콜을 사용해서 사본을 동기화한다.
반-엔트로피 프로토콜은 사본들을 비교하여 최신 버전으로 갱신하는 과정을 포함한다.
사본 간의 일관성이 망가진 상태를 탐지하고 전송 데이터의 양을 줄이기 위해서는 머클트리를 사용할 것이다.
머클 트리란 해시 트리라고도 불리며 각 노드에 그 자식 노드들에 보관된 값의 해시, 또는 자식 노드들의 레이블로부터 계산된 해시 값을 레이블로 붙여두든 트리이다.
이 머클 트리를 사용하면 동기화해야 하는 데이터의 양은 실제로 존재하는 차이의 크기에 비례할 뿐, 두 서버에 보관된 데이터의 총량과는 무관해진다. 하지만 실제로 쓰이는 시스템의 경우 버킷 하나의 크기가 꽤 크다는 것은 알아두어야 한다.
데이터 센터 장애 처리
데이터 센터 장애는 정전, 네트워크 장애, 자연재해 등 다양한 이유로 발생할 수 있다.
데이터 센터 장애에 대응할 수 있는 시스템을 만들려면 데이터를 여러 데이터 센터에 다중화하는 것이 중요하다.
시스템 아키텍처 다이어그램
아키텍처의 주된 기능
- 클라이언트는 키-값 저장소가 제공하는 두 가지 단순한 API, 즉 get(key) 및 put(key, value)와 통신한다.
- 중재자는 클라이언트에게 키-값 저장소에 대한 프락시 역할을 하는 노드이다.
- 노드는 안정 해시의 해시 링 위에 분포한다.
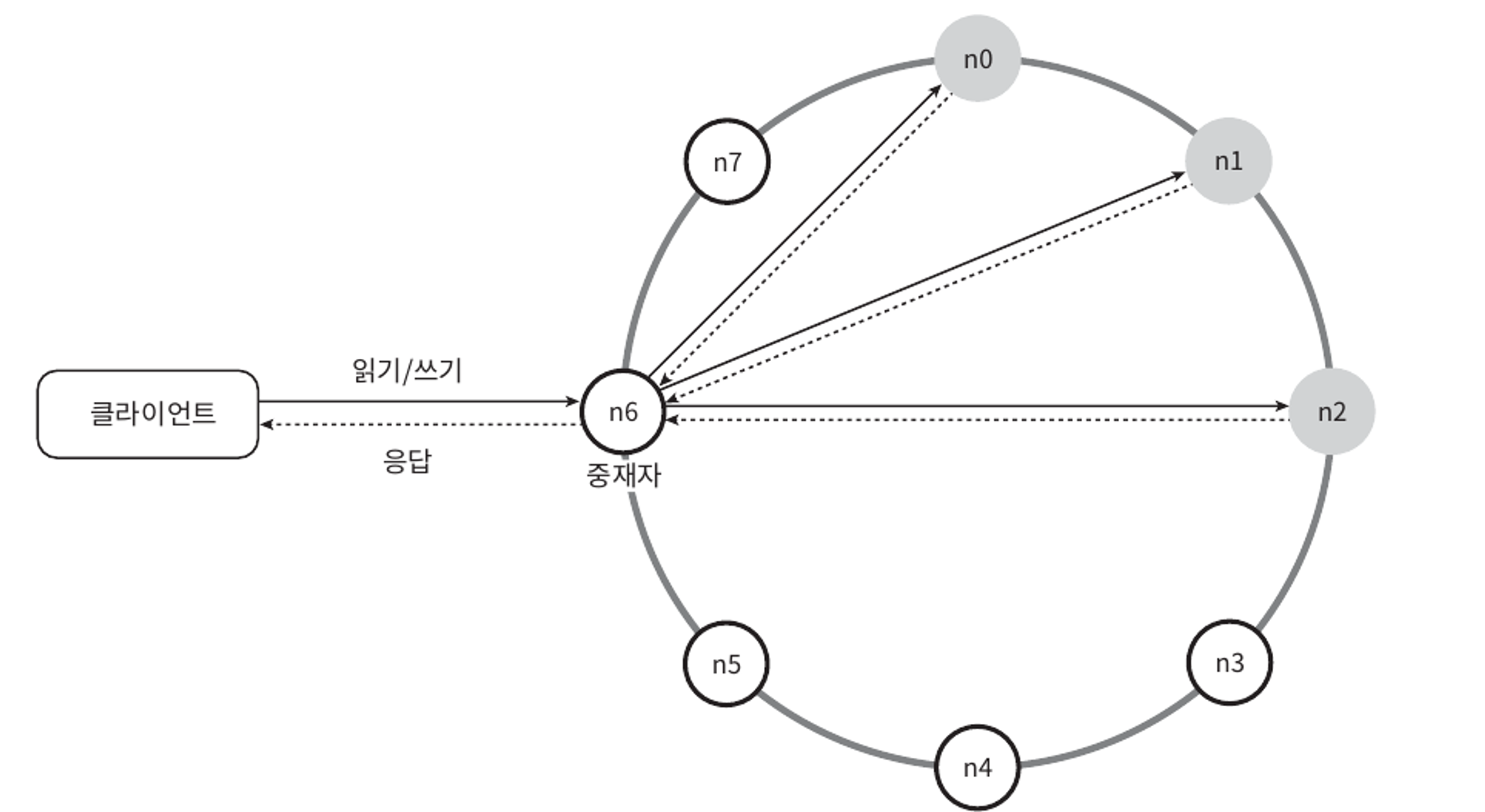
- 노드를 자동으로 추가/삭제할 수 있도록 시스템은 완전히 분산된다.
- 데이터는 여러 노드에 다중화된다.
- 모든 노드가 같은 책임을 지므로, SPOF(Single Point of Failure)는 존재하지 않는다.
완전히 분산된 설계를 채택하였으므로, 모든 노드는 아래 그림에서 제시된 기능 전부를 지원해야 한다.
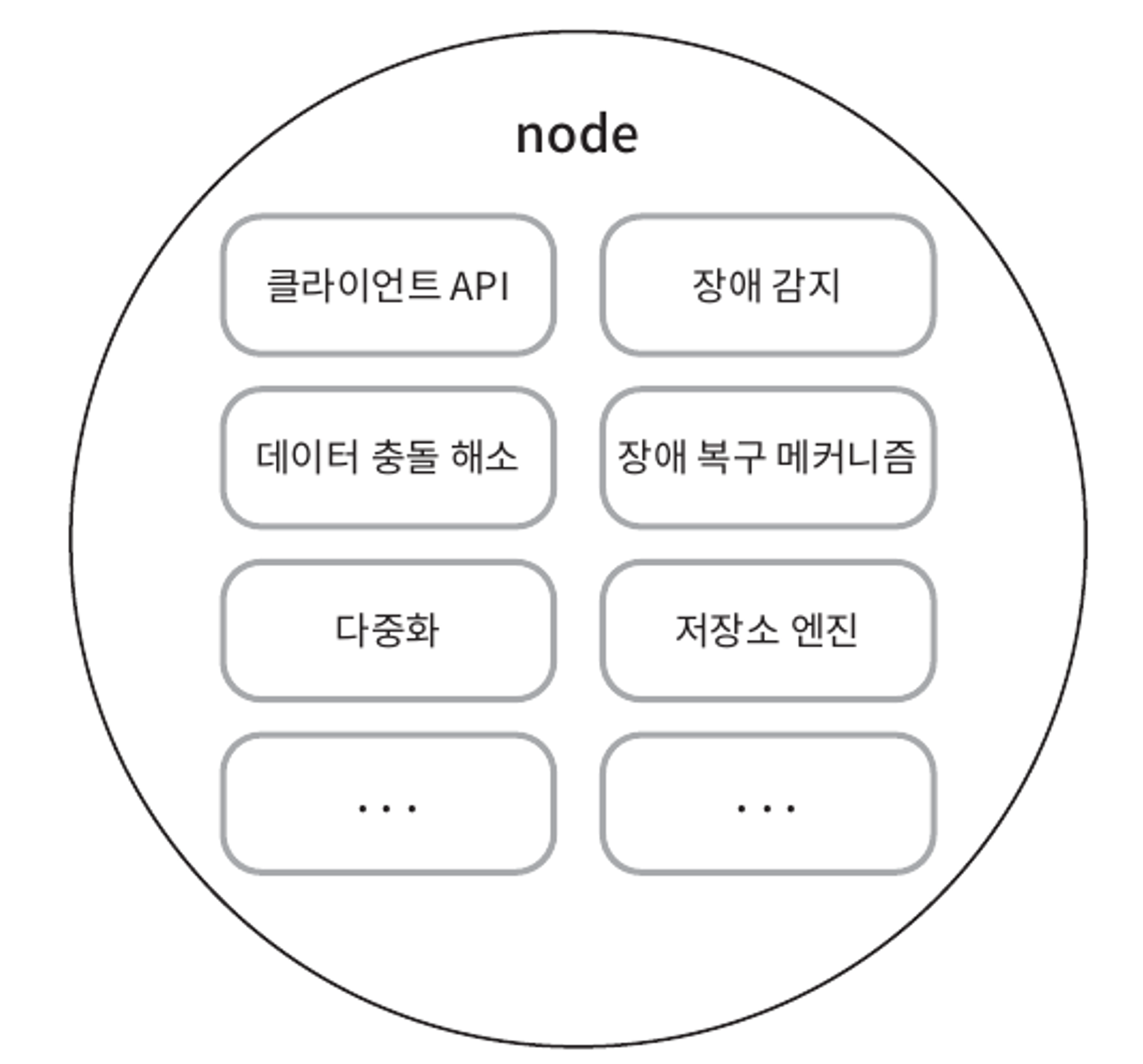
쓰기 경로
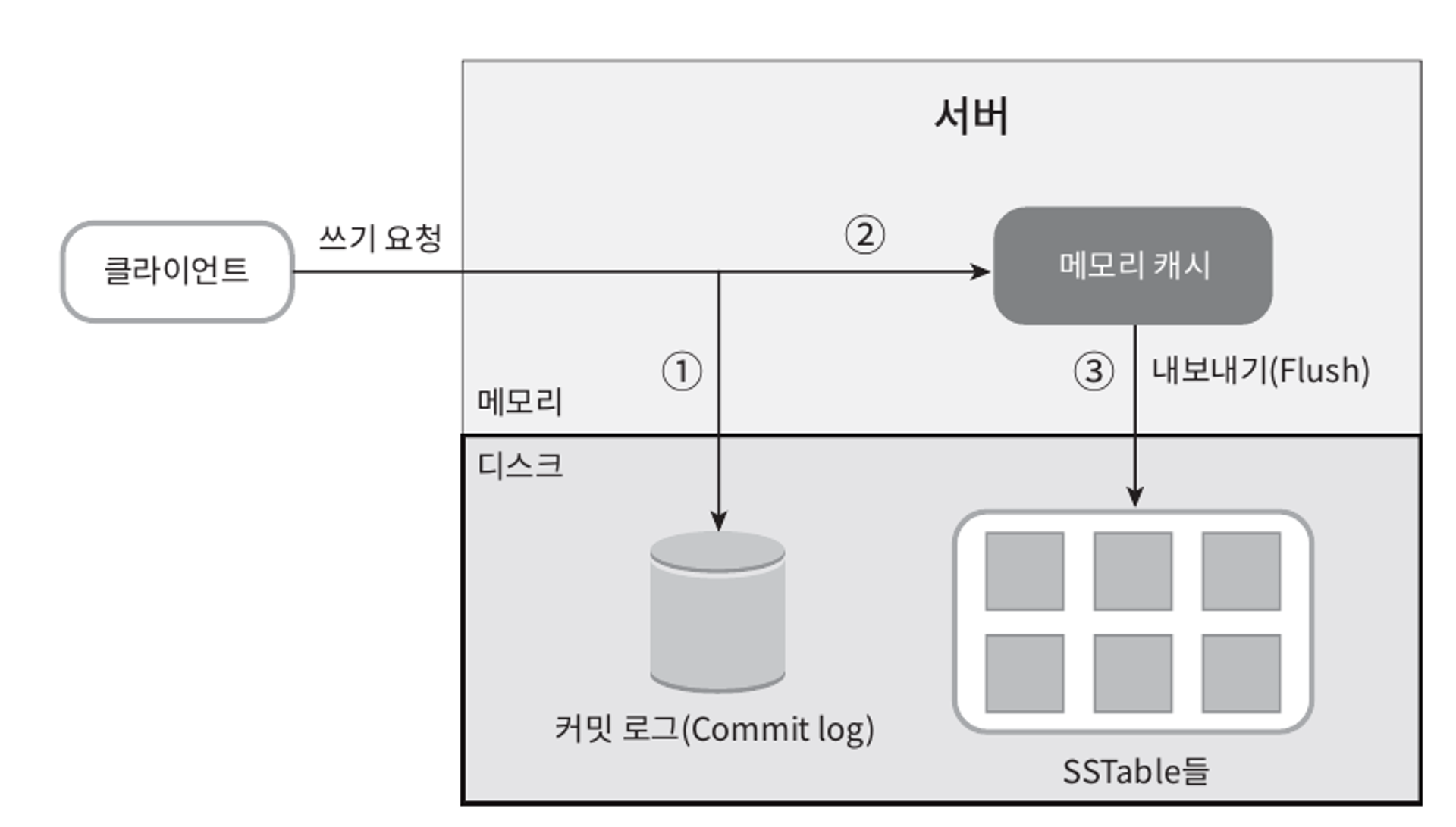
쓰기 요청이 특정 노드에 전달되면 무슨 일이 벌어지는지를 보여준다.
- 쓰기 요청이 커밋 로그 파일에 기록된다.
- 데이터가 메모리 캐시에 기록된다.
- 메모리 캐시가 가득차거나 사전에 정의된 어떤 임계치에 도달하면 데이터는 디스크에 있는
SSTable에 기록된다. SSTable은 Sorted-String Table의 약어로, <키, 값>의 순서쌍을 정렬된 리스트 형태로 관리하는 테이블이다.
읽기 경로
읽기 요청을 받은 노드는 데이터가 메모리 캐시에 있는지부터 살핀다. 있는 경우는 아래와 같이 해당 데이터를 클라이언트에 반환한다.
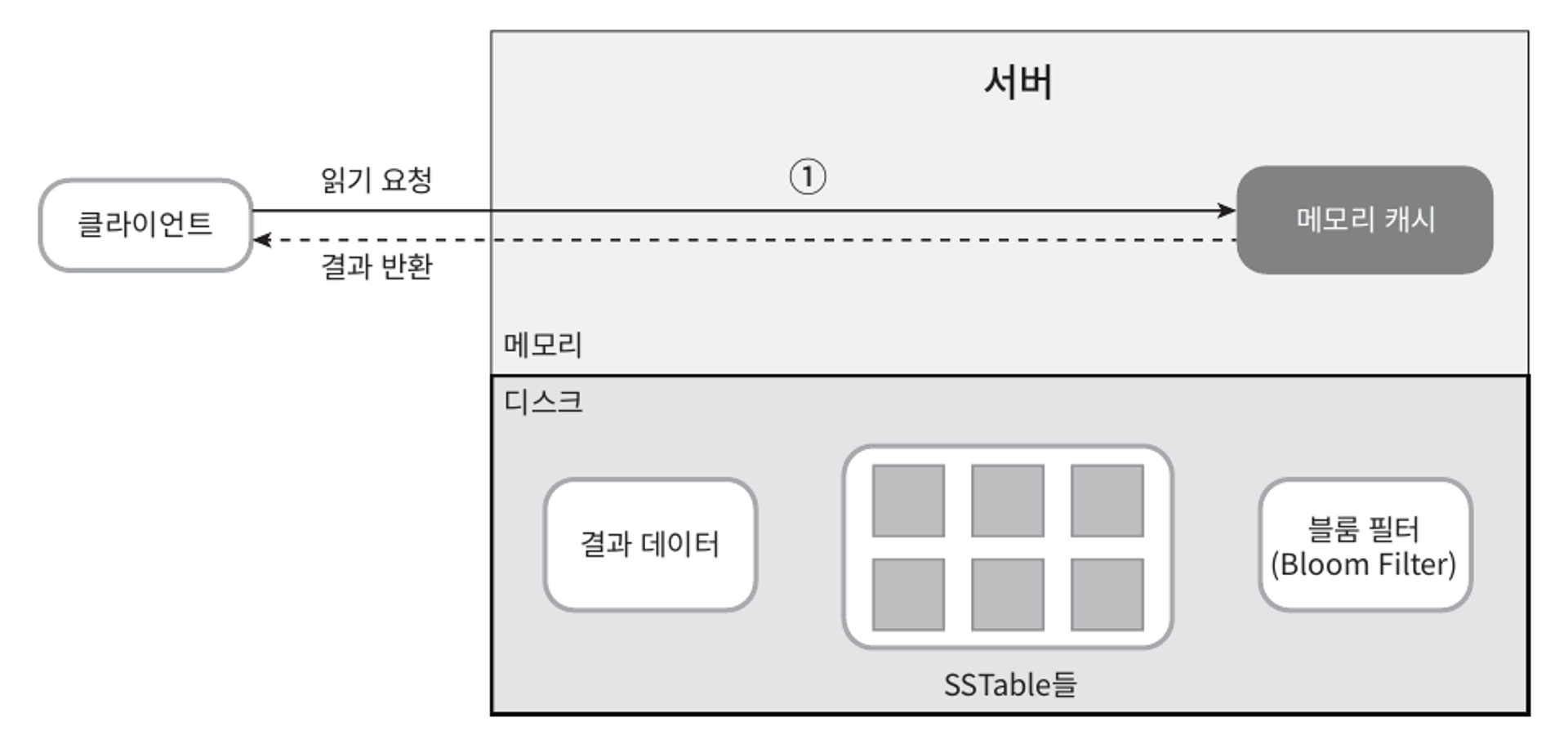
데이터가 메모리에 없는 경우에는 디스크에서 가져와야 한다. 어느 SSTable에 찾는 키가 있는지 알아낼 효율적인 방법이 필요할 것이다.
이런 문제를 푸는데에는 블룸 필터가 흔히 사용된다.
블룸 필터
- 특정 원소가 집합에 속하는지 검사하는데 사용할 수 있는 확률형 자료 구조
- 확률형 자료구조라 틀릴 수 있다.
집합의 크기가 굉장히 크거나집합의 속해있는 원소의 크기가 커서 원소가 집합에 속해있는지 정확히 판단하는데 시간이 오래걸리는 경우 사용- 예시 : 100억개의 url이 있는데 중복된 url의 개수를 알기 위한 방법을 설계
데이터가 메모리에 없을 때 읽기 연산이 처리되는 경로를 보면 아래와 같다.

- 데이터가 메모리 있는지 검사한다. 없으면 2로
- 데이터가 메모리에 없으므로 블룸 필터를 검사한다.
- 블룸 필터를 통해 어떤 SSTable에 키가 보관되어 있는지 알아낸다.
- SSTable에서 데이터를 가져온다.
- 해당 데이터를 클라이언트에 반환한다.
요약
분산 키-값 저장소가 가져야 하는 기능과 그 기능 구현에 이용되는 기술..
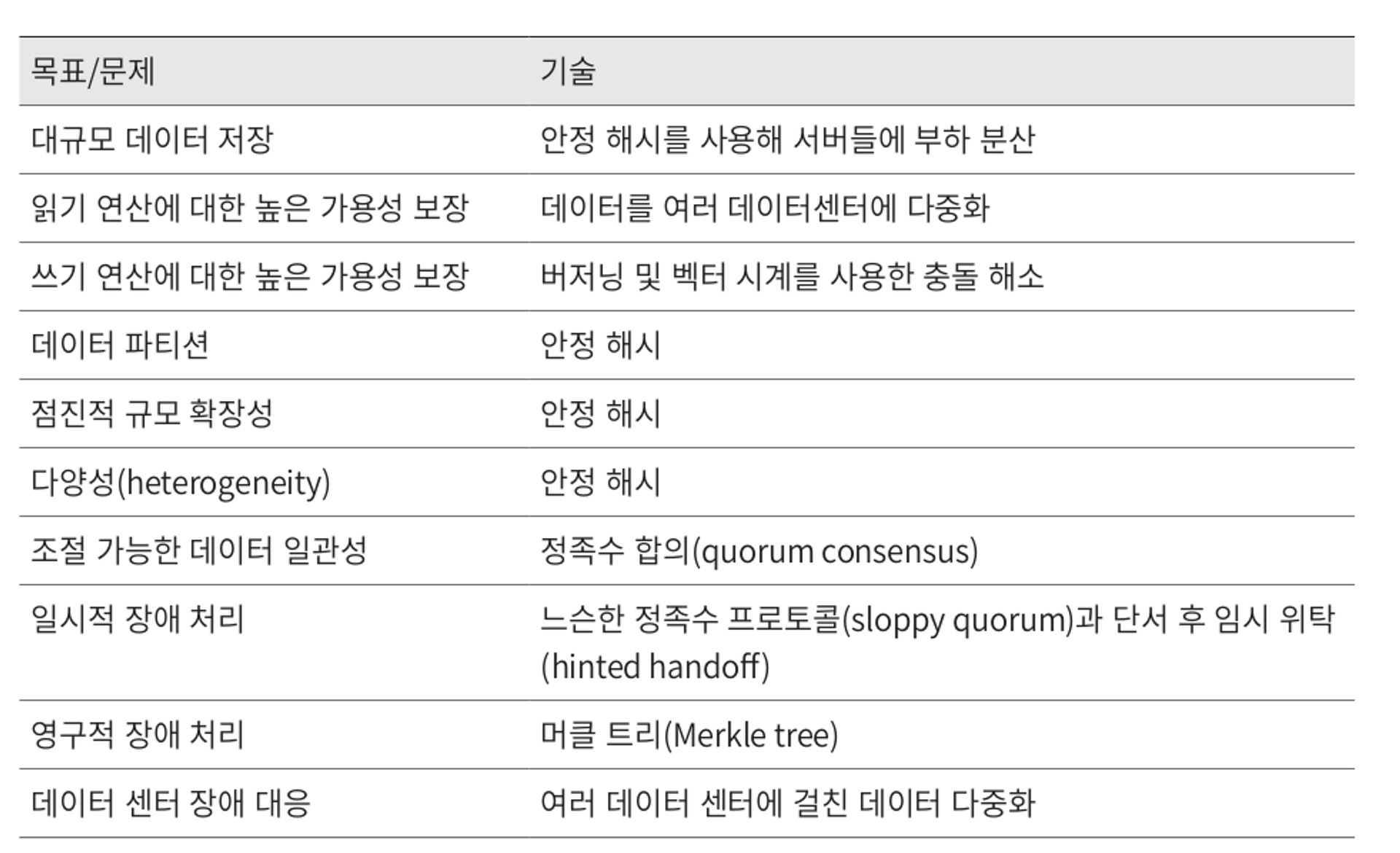
참고
https://velog.io/@bbkyoo/가상-면접-사례로-배우는-대규모-시스템-설계-기초-6장-키-값-저장소-설계
