자연어 처리 전처리
토큰화
텍스트를 단어, 문자로 자르는것
spacy, nltk
import spacy
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
spacy_en = spacy.load("en_core_web_sm")
en_text = "A 한글 1123 한 글 near spare bedrooms zxczxc"
def tokenize(en_text):
return [tok.text for tok in spacy_en.tokenizer(en_text)]
print(tokenize(en_text))
print(word_tokenize(en_text))['A', '한글', '1123', '한', '글', 'near', 'spare', 'bedrooms', 'zxczxc']
['A', '한글', '1123', '한', '글', 'near', 'spare', 'bedrooms', 'zxczxc']split과 비슷하다.
- spacy에는 tensor라는 속성이 있다.
한글 형태소 분석기
제일 잘쓰이는 Komoran과 Hannanum
설정하는방법
- pip3 install konlpy
- JAVA_HOME 환경변수에 jdk1.8 이상 저장
- IDE restart하기
Komoran
from konlpy.tag import Komoran
komoran = Komoran()
print(komoran.morphs(u'금융위 "은행권, 만기연장·상환유예 후 2주간 2조6천억원 지원"'))
print(komoran.nouns(u'금융위 "은행권, 만기연장·상환유예 후 2주간 2조6천억원 지원"'))
print(komoran.pos(u'금융위 "은행권, 만기연장·상환유예 후 2주간 2조6천억원 지원"'))['금융', '위', '"', '은행', '권', ',', '만기', '연장', '·', '상환', '유예', '후', '2', '주간', '2', '조', '6', '천억', '원', '지원', '"']
['금융', '위', '은행', '만기', '연장', '상환', '유예', '후', '주간', '원', '지원']
[('금융', 'NNG'), ('위', 'NNG'), ('"', 'SS'), ('은행', 'NNG'), ('권', 'XSN'), (',', 'SP'), ('만기', 'NNG'), ('연장', 'NNG'), ('·', 'SP'), ('상환', 'NNP'), ('유예', 'NNP'), ('후', 'NNG'), ('2', 'SN'), ('주간', 'NNG'), ('2', 'SN'), ('조', 'NR'), ('6', 'SN'), ('천억', 'NR'), ('원', 'NNB'), ('지원', 'NNG'), ('"', 'SS')]Hannanum
from konlpy.tag import Hannanum
hannanum = Hannanum()
print(hannanum.analyze(u'금융위 "은행권, 만기연장·상환유예 후 2주간 2조6천억원 지원"'))
print(hannanum.nouns(u'금융위 "은행권, 만기연장·상환유예 후 2주간 2조6천억원 지원"'))
print(hannanum.morphs(u'금융위 "은행권, 만기연장·상환유예 후 2주간 2조6천억원 지원"'))
print(hannanum.pos(u'금융위 "은행권, 만기연장·상환유예 후 2주간 2조6천억원 지원"'))['금융위', '은행권', '만기연장·상환유예', '후', '2주간', '2조6천억원', '지원']
['금융위', '"', '은행권', ',', '만기연장·상환유예', '후', '2주간', '2조6천억원', '지원', '"']
[('금융위', 'N'), ('"', 'S'), ('은행권', 'N'), (',', 'S'), ('만기연장·상환유예', 'N'), ('후', 'N'), ('2주간', 'N'), ('2조6천억원', 'N'), ('지원', 'N'), ('"', 'S')]morph
형태소 반환
nouns
명사반환
pos
품사정보 반환
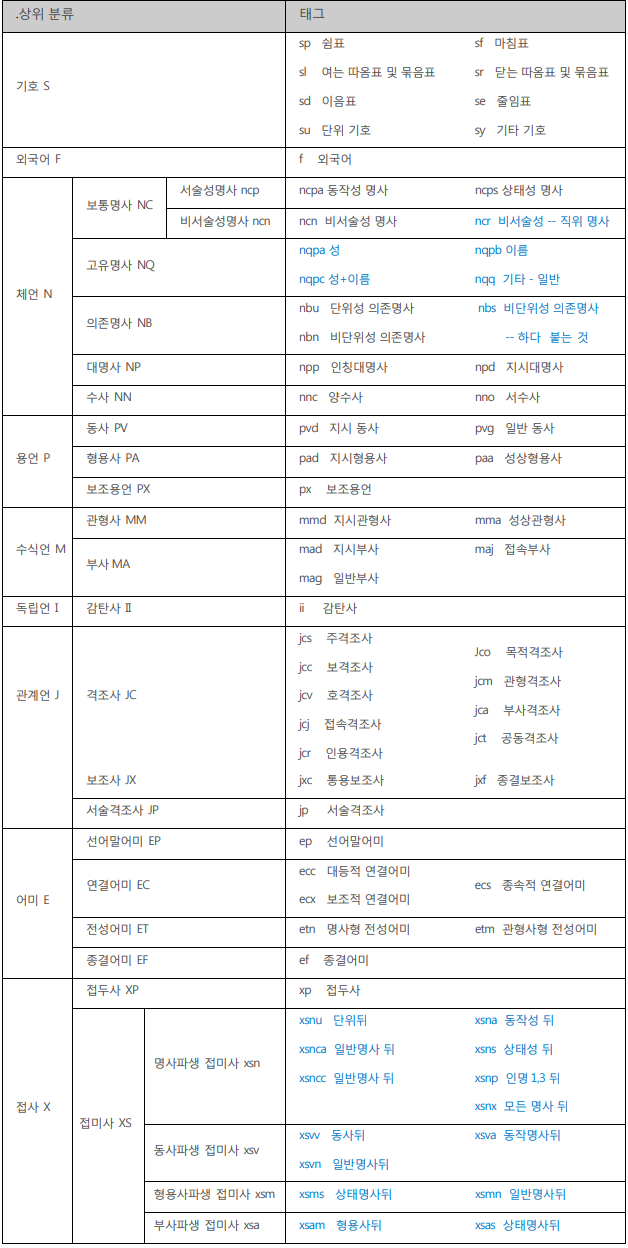
예제
많이 추출된 단어 뽑기
from collections import Counter
from konlpy.tag import Hannanum
from konlpy.tag import Komoran
komoran = Komoran()
hannanum = Hannanum()
text = """
상대성 이론(相對性理論 / Theory of Relativity)은 알베르트 아인슈타인이 주장한 인간, 생물, 행성, 항성, 은하
크기 이상의 거시 세계를 다루는 이론이다. 양자역학과 함께 우주에
기본적으로 작용하는 법칙을 설명하는 이론이자 현대 물리학에서 우주를
이해하는 데 사용하는 두 개의 가장 근본적인 이론이다. 시간과 공간을 시공간으로,
물질과 에너지를 통합하는 데에 성공해 빛과 어둠을 인류에게 가져다 주었다.
"""
text = (u'%s' % text)
komoranNounsList = komoran.nouns(text)
hannanumNounsList = komoran.nouns(text)
komoranNounsCount = Counter(komoranNounsList)
hannanumNounsCount = Counter(hannanumNounsList)
print(komoranNounsCount)
print(hannanumNounsCount)여기까지는 형태소분석 라이브러리다.
참고
https://konlpy-ko.readthedocs.io/ko/v0.4.3/api/konlpy.tag/
https://wikidocs.net/64517
torchtext 세팅하는데만 며칠걸렸다.
pytorch버전이랑 torchtext버전이 충돌난거 같은데 세팅을 계속 시도하다가 IDE를 재실행하니 갑자기 됐다.
from torchtext import data # torchtext.data 임포트
from torchtext.data import TabularDataset
import urllib.request
import pandas as pd
from torchtext.data import Iterator
def imdb():
urllib.request.urlretrieve(
"https://raw.githubusercontent.com/LawrenceDuan/IMDb-Review-Analysis/master/IMDb_Reviews.csv",
filename="IMDb_Reviews.csv")
def getIMDB():
df = pd.read_csv('IMDb_Reviews.csv', encoding='latin1')
df.head()
print(df)
def splitIMDB():
df = pd.read_csv('IMDb_Reviews.csv', encoding='latin1')
train_df = df[:25000]
test_df = df[25000:]
train_df.to_csv("train_data.csv", index=False)
test_df.to_csv("test_data.csv", index=False)
class TorchTextExample:
def __init__(self):
self.TEXT = data.Field(sequential=True,
use_vocab=True,
tokenize=str.split,
lower=True,
batch_first=True,
fix_length=20)
self.LABEL = data.Field(sequential=False,
use_vocab=False,
batch_first=False,
is_target=True)
def makeDataset(self):
# 훈련, 테스트데이터로 나누기
self.train_data, self.test_data = TabularDataset.splits(
path='.', train='train_data.csv', test='test_data.csv', format='csv',
fields=[('text', self.TEXT), ('label', self.LABEL)], skip_header=True)
print('훈련 샘플의 개수 : {}'.format(len(self.train_data)))
print('테스트 샘플의 개수 : {}'.format(len(self.test_data)))
print(vars(self.train_data[0])) # 첫번째 데이터 샘플 확인
print(self.train_data.fields.items()) # 필드 구성확인
def wordVoca(self):
# 단어집합
# 단어의 집합 생성
# min_freq : 단어집합의 최소 등장빈도, max_size : 단어집합의 최대 크기
self.TEXT.build_vocab(self.train_data, min_freq=10, max_size=10000)
# 10002가 나옴
# 10002가 나오는 이유는 <unk> <pad> 토큰이 0,1번에 추가되서다.
# unk 토큰 : 단어집합에 없는 단어 표현
# pad 토큰 : 길이 맞추는 패딩작업
print('단어 집합의 크기 : {}'.format(len(self.TEXT.vocab)))
print(self.TEXT.vocab.stoi)
def dataLoader(self):
# 데이터로더
batch_size = 25 # 배치크기
train_loader = Iterator(dataset=self.train_data, batch_size=batch_size)
test_loader = Iterator(dataset=self.test_data, batch_size=batch_size)
# 25000개를 5개 배치로 묶어줘서 5000개가 나옴
print('훈련 데이터의 미니 배치 수 : {}'.format(len(train_loader))) # 5000
print('테스트 데이터의 미니 배치 수 : {}'.format(len(test_loader))) # 5000
batch = next(iter(train_loader)) # 첫번째 미니배치
print(type(batch)) # 자료형 <class 'torchtext.data.batch.Batch'>
print(batch.text)
batch = next(iter(train_loader)) # 첫번째 미니배치
print(batch.text[0]) # 첫번째 미니배치 중 첫번째 샘플
# 샘플의 길이는 5x20으로 나온다.
# 배치사이즈 : 5, 전처리 fix_length : 20
torchTextExample = TorchTextExample()
torchTextExample.makeDataset()
torchTextExample.wordVoca()
torchTextExample.dataLoader()imdb() 리뷰데이터를 다운받는 함수다.
getIMDB() 저장된 파일을 읽는 함수다.
splitIMDB() 훈련데이터와 테스트 데이터로 나눠 파일로 저장하는 함수
- 데이터와 테스트를 나누기위해서 흔히 사용
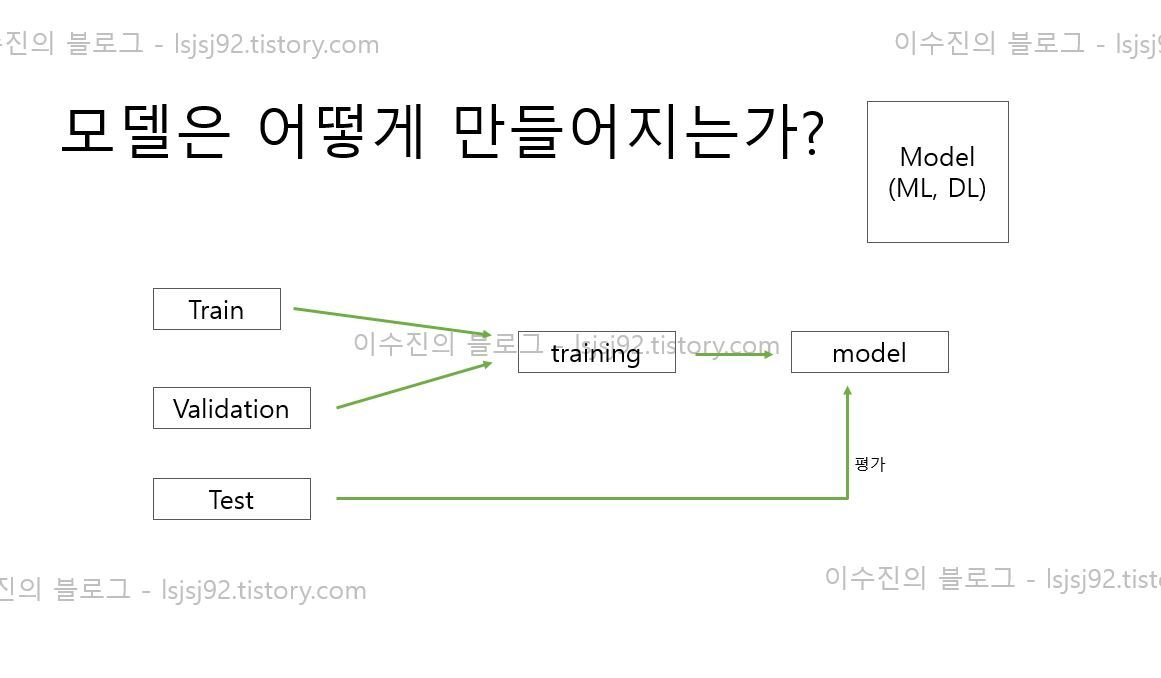
그림 출처 : https://lsjsj92.tistory.com/545
테스트데이터 (test_data)
- 훈련 하기전 예측이 잘되는지
- 학습이 없을때 예측이 얼마나 잘되는지
훈련 데이터 (train_data)
- 실제 학습할 데이터
__init__ 메서드에 TEXT와 LABEL
전처리를 어떻게할지 미리 정함
- sequential : 객체의 순서 (boolean)
- use_vocab : 단어장 객체 사용여부 (boolean)
- tokenize : 토큰화 함수
- lower : 소문자 변환 (boolean)
- batch_first : 미니 배치차원을 맨앞으로
결과
배치사이즈3으로한 결과다.
실행할때마다 결과가 바뀐다.
숫자들은 단어집합이다.
tensor([[ 0, 3, 0, 0, 228, 3144, 5, 2, 252, 425, 5436, 212,
26, 71, 2, 450, 1768, 2065, 4, 535],
[ 50, 10, 20, 14, 95, 8, 0, 9, 14, 3, 2757, 8,
2, 2347, 1321, 365, 15, 184, 5, 2],
[ 108, 9, 26, 6, 1057, 10, 14, 30, 5, 55, 4218, 15,
3, 3561, 50, 9, 307, 6, 109, 11]])
잡부