조건 1. n의 다음 큰 숫자는 n보다 큰 자연수 입니다.
조건 2. n의 다음 큰 숫자와 n은 2진수로 변환했을 때 1의 갯수가 같습니다.
조건 3. n의 다음 큰 숫자는 조건 1, 2를 만족하는 수 중 가장 작은 수 입니다.
SOLVE
당장은 그냥 n+1부터 반복문을 돌리면서 찾아주면 되겠다 라고 생각을 했다.
이걸 코드로 나타내면...
일단 전에 배웠던 이진수 변환 String(value,radix:2)를 사용해서 코드를 짜봤다.
import Foundation
func countBinaryOne(_ number: Int) -> Int {
return String(number, radix: 2).replacingOccurrences(of: "0", with: "").count
}
func solution(_ n: Int) -> Int {
var answer = 0
var cnt = 1
let oneCnt = countBinaryOne(n)
while true {
let newTarget: Int = n + cnt
if countBinaryOne(newTarget) == oneCnt {
answer = newTarget
break
}
cnt += 1
}
return answer
}
이전에 배웠던 replaceOccurrences를 활용해서 1의 갯수를 파악하는 함수를 만들고 이를 활용해서 while문으로 1씩 더해가면서 찾고자 했는데, 통과하는 듯 싶더니, 효율성테스트에서 빠그라졌다.
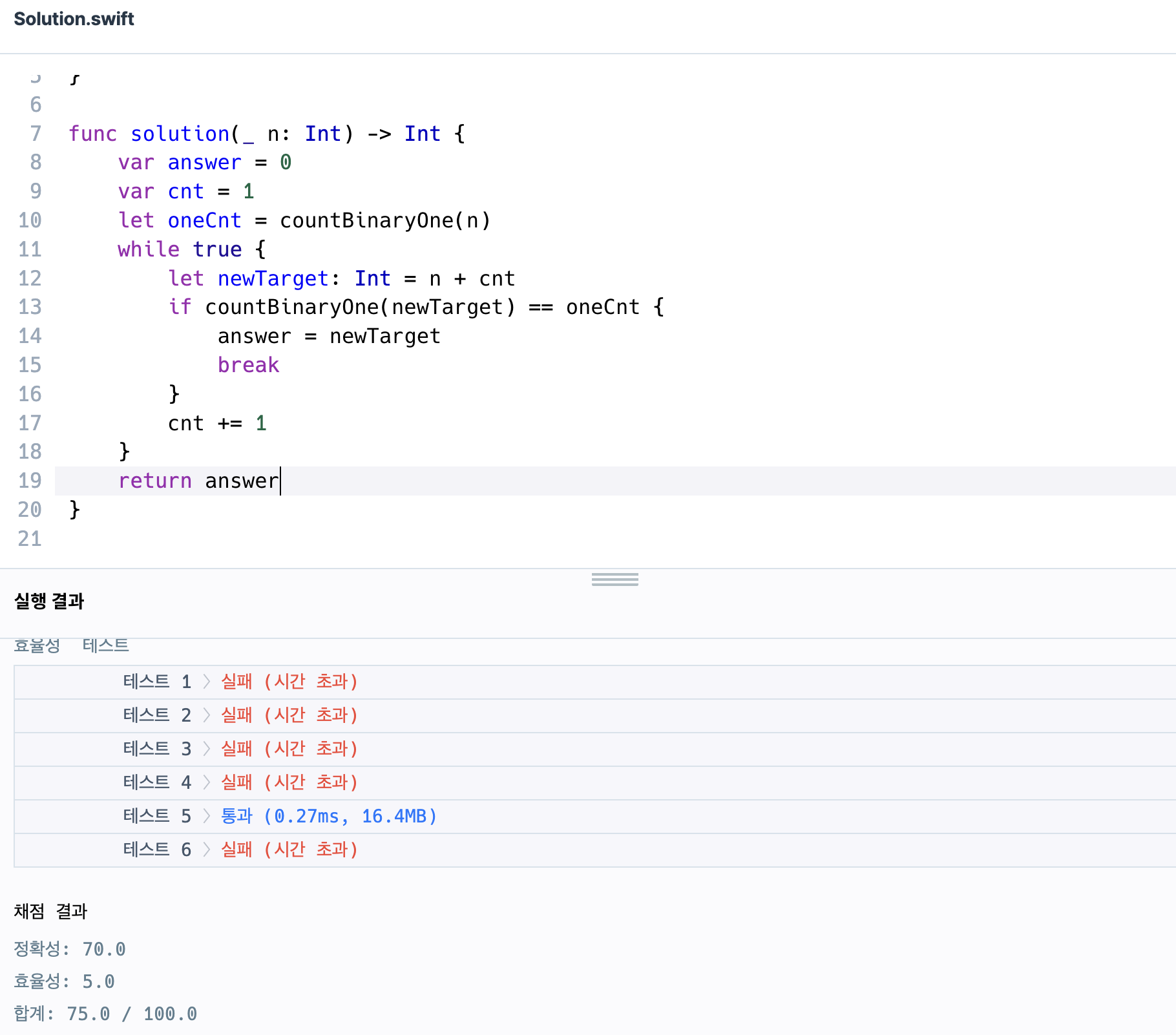
시간초과라고 떴으니, 이렇게 완전탐색 방식으로 찾지 않고 더 효율적인 방법을 찾아야했다.
시간초과
Q : 이진수 변환을 안하고도 알 수가 있나?
근데 이거는 아닌거 같다 5->6만보더라도 1차이지만 101 110 으로 충족하기 때문에, 맘대로 간격을 두고 찾을 수는 없는 것같은데,
그래서 처음에는 이게 78이면 가장 큰 지수인 (이경우에는 64) 64를 빼주는 식의 연산을 통해서 숫자를 작게 해주기도 했었는데, 오히려 그나마 통과하던 하나마저 시간초과로 바뀌었다
replacingOccurrences vs Filter
혹시나해서 replacingOccurrences를 filter로 변환했더니 바로 통과했다 (?)
replacingOccurrences이 더 느린 이유 ?
replacingOccurents는 다음과 같은 과정으로 수행된다고 한다.
부분 문자열 탐색: 전체 문자열을 순회, 지정한 부분 문자열을 찾기
공식 문서에서 정확한 알고리즘을 명시하지 않기 때문에 최악의 경우를 생각해보면 O(n*m) (n: 전체 문자열 길이, m: 찾는 패턴의 길이)의 시간 복잡도를 가질 수도 있다고한다.(이 부분은 커뮤니티에 따라 의견이 좀 상의하다. 탐색작업 o(n)에 교체작업은 상수복잡도라서 o(n) 이라는 사람도 있고 그렇지 않다는 사람도 존재한다.)
치환(교체) 작업 수행: 찾은 부분 문자열을 새로운 문자열로 대체
새로운 메모리 할당, 문자열 복사, 인덱싱 비용이 발생
결론은 패턴 매칭 + 문자열 교체 라는 작업을 수행하는 것이다.
filter 원리
Returns a new collection of the same type containing, in order, the elements of the original collection that satisfy the given predicate.
filter는 문자열(정확히는 String이 Collection 프로토콜을 따르기 때문)에서 개별 문자를 순회하며, 주어진 조건에 맞는 문자들만 선별하는 방식
filter는 단순히 각 문자를 한 번씩 살펴보고 (O(n)) 조건에 맞으면 결과 버퍼에 추가하는 식으로 진행이 된다.
탐색 과정: 모든 문자를 순회 (O(n))
조건 검사: 각 문자에 대해 조건(Closure) 만족 여부 검사. 보통 상수시간(O(1))
결과 문자열 구성: 조건을 만족하는 문자를 바로바로 결과 버퍼에 append 하므로 추가적인 복잡한 문자열 재구성 과정이 적다.
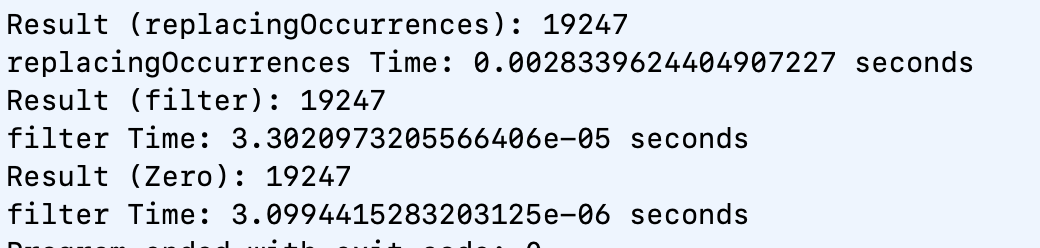
실제 시간 차이
CFAbsoluteTimeGetCurrent를 통해서 얼마나 차이가 나는지 한번 알아보았다.
// 기호 1번 replacingOccurrences
return String(number, radix: 2).replacingOccurrences(of: "0", with: "").count
// 기호2번 filter
return String(number, radix: 2).filter { $0 == "1" }.count
let start1 = CFAbsoluteTimeGetCurrent()
print("Result (replacingOccurrences):", solution(19231))
let end1 = CFAbsoluteTimeGetCurrent()
print("replacingOccurrences Time: \(end1 - start1) seconds")
let start2 = CFAbsoluteTimeGetCurrent()
print("Result (filter):", solutionFilter(19231))
let end2 = CFAbsoluteTimeGetCurrent()
print("filter Time: \(end2 - start2) seconds")
기호 1번(placingOccurrences)
0.0029180049896240234 seconds
기호 2번(filter)
2.7060508728027344e-05 seconds
처음에는 잉? filter가 더 느린가? 싶었는데, 뒤에 e-05같은 문자가 있길래 일반적인 초단위가 아니겠구나 해서 gpt에게 차이를 물어보았다.
엄청 간단히 그냥 '0'을 지우는 로직을 수행하고 있기때문에, filter와의 차이가 크다는 것을 알 수 있다.
결론
간단한 로직에는 filter를, 복잡한 문자열 작업이나 다양한 자료형을 다룰 때는 replacingOccurrences를 사용하는 것이 추천되는 것 같다. (각각의 용도의 맞게 !)
filter는 조건에 맞는 문자만 골라내는 데 특화되어 있고, replacingOccurrences는 복잡한 문자열 치환 작업을 위해 설계된 메소드라하니, 이렇게 그냥 0을 걸러내주면 될 때는 그냥 filter가 더 효율적인 것 같다 !
타인의 답
while true {
if n.nonzeroBitCount == answer.nonzeroBitCount {
break;
}
answer += 1
}nonzeroBitCount?
다음과 같은 신기한 메소드를 하나 더 배울 수 있었다.
이진수에서 1 개수를 카운팅해주는 친구이다

시간비교
결국 이진수로 String()을 통해서 변환해주지도 않고, nonzeroBitCount라는 메소드를 활용한다면 엄청 쉽게 수행할 수 있다는 것도 알아냈다. Bit