Segregated Free List란?
 [이미지 출처](https://slideplayer.com/slide/14732529/)
Segregated Free List는 가용 메모리 블록을 크기에 따라 분리하여 관리하는 기술입니다. 미리 정의된 크기 클래스(size class)에 따라 가용 블록을 분류하고, 각 크기 클래스는 해당 크기 범위의 블록을 연결 리스트로 관리합니다. 할당 요청이 들어오면 요청된 크기에 맞는 크기 클래스를 찾아 해당 리스트에서 적합한 블록을 할당하는 방식으로 동작합니다.
[이미지 출처](https://slideplayer.com/slide/14732529/)
Segregated Free List는 가용 메모리 블록을 크기에 따라 분리하여 관리하는 기술입니다. 미리 정의된 크기 클래스(size class)에 따라 가용 블록을 분류하고, 각 크기 클래스는 해당 크기 범위의 블록을 연결 리스트로 관리합니다. 할당 요청이 들어오면 요청된 크기에 맞는 크기 클래스를 찾아 해당 리스트에서 적합한 블록을 할당하는 방식으로 동작합니다.
구현 과정
1. 가용 블록 크기 클래스 정의
블록의 크기에 따라 크기 클래스를 정의하는 것은 Segregated Free List 구현에 있어 매우 중요한 부분입니다. 프로젝트에서는 블록의 크기를 2의 제곱 단위로 구분하여 클래스를 나누었습니다. 이는 비트 연산을 통해 빠르고 효율적으로 크기 클래스를 결정할 수 있기 때문입니다.
프로젝트에서 사용된 크기 클래스는 다음과 같습니다:
1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, ...
그러나 이 프로젝트에서는 더블 워드 크기인 16바이트를 기본 단위로 사용하고 있습니다. 따라서 16바이트 미만의 크기를 요청받더라도 16바이트로 할당해 주어야 합니다.
한편, 프로젝트에서는 CHUNKSIZE를 2의 12승인 4096바이트로 설정하고 있습니다. 이는 힙을 확장할 때 기본적으로 할당받는 메모리의 크기입니다.
#define CHUNKSIZE (1 << 12)이를 바탕으로 크기 클래스의 개수를 결정할 때, CHUNKSIZE가 2의 12승이므로 크기 클래스의 개수를 12에 맞춰 설정하고, 16바이트 미만의 클래스를 고려하여 4를 더해주었습니다. 따라서 LISTLIMIT를 16으로 선언하였습니다.
#define LISTLIMIT 16
static void *segregated_list[LISTLIMIT];이렇게 설정된 LISTLIMIT는 현재 테스트 케이스에서 충분한 크기이며, 더 큰 값으로 설정해도 무방할 것으로 보입니다.
크기 클래스를 적절히 정의하는 것은 메모리 할당의 효율성과 메모리 사용량 측면에서 중요한 역할을 합니다. 할당 요청의 크기 분포를 고려하여 크기 클래스를 조절함으로써 메모리 낭비를 최소화하고 할당 속도를 향상시킬 수 있습니다.
2. 분리 가용 리스트 init
각 크기 클래스마다 가용 블록을 저장할 연결 리스트를 생성했습니다. 이를 위해 segregated_list라는 전역 배열을 선언, init에서 각 리스트를 NULL로 초기화했습니다.
void *segregated_list[LISTLIMIT];
int mm_init(void) {
int list;
for (list = 0; list < LISTLIMIT; list++) {
segregated_list[list] = NULL;
}
}3. 할당 요청 시 탐색 로직:
find_fit함수
할당 요청이 들어왔을때 요청된 크기에 맞는 크기 클래스를 찾기위한 find_fit 함수
-
요청된 크기를 기준으로
searchsize를 설정하고,index를 0으로 초기화합니다. -
searchsize를>>1비트 연산을 통해 반으로 줄여가면서index를 증가시킵니다. 이 과정을searchsize가 1이 될 때까지 반복합니다. -
index가LISTLIMIT - 1이거나searchsize가 1 이하이고 해당 인덱스의segregated_list가 비어있지 않은 경우, 해당 크기 클래스의 리스트에서 적합한 블록을 찾습니다.static void *find_fit(size_t asize) { // 가용 리스트 탐색 void *bp; int index = 0; size_t searchsize = asize; while (index < LIST_LIMIT) { // LISTLIMIT까지 도달하기 전까지 if ((index == LIST_LIMIT - 1) || (searchsize <= 1) && (segregated_list[index] != NULL)) { // NOTE - index를 하나씩 올려주면서 절반으로 비트연산 해주기 때문에 searchsize가 1이 될때까지 계속 올라간다 limit이 bp = segregated_list[index]; // 분리 가용 리스트의 해당 클래스의 인덱스로 지정 while ((bp != NULL) && (asize > GET_SIZE(HDRP(bp)))) { bp = SUCC_FREE(bp); // 큰 범위로 클래스리스트를 구분해줄때는 필요하지만 사실 현재는 bp!=null일때만 판단해주고 맨앞 블록 넣어줄 것이다. 동일한 사이즈로만 들어가게끔 해줬기 때문 } if (bp != NULL) { return bp; } } searchsize = searchsize >> 1; index++; } return NULL; /* 못찾음 */ }index를 증가시키면서searchsize를 절반씩 줄여가는 방식으로, 요청된 크기에 해당하는 크기 클래스를 찾습니다.- 현재 구현에서는 동일한 크기의 블록만 각 크기 클래스에 들어가도록 했기 때문에,
bp != NULL조건만 확인하면 됩니다. - 적합한 블록을 찾으면 해당 블록의 포인터를 반환하고, 찾지 못하면 다음 크기 클래스로 이동합니다.
크기 클래스를 사용하여 탐색 범위를 좁히고, 동일한 크기의 블록만 관리하도록 하여 탐색 속도를 향상시켰습니다.
4. 블록 분할 및 병합
할당된 블록의 크기가 요청된 크기보다 클 경우, 블록을 분할하여 남은 부분을 가용 블록으로 만들어야 합니다. 반대로 인접한 가용 블록이 있을 경우 병합하여 더 큰 블록을 만들 수 있습니다. 이를 위해 place 함수와 coalesce 함수를 구현했습니다.
place함수
place 함수는 할당 요청에 대해 실제로 블록을 할당하고, 필요에 따라 블록을 분할하는 역할을 합니다.
-
현재 블록의 크기(
csize)가 요청된 크기(asize)보다 16바이트 이상 클 때만 블록을 분할합니다. 이는 헤더와 푸터를 포함한 최소 블록 크기가 16바이트이기 때문입니다. -
블록을 분할하는 경우, 할당된 블록의 헤더와 푸터를 설정하고
bp를 다음 블록으로 이동시킵니다. -
남은 부분을 가용 블록으로 만들기 위해 헤더와 푸터를 설정하고,
coalesce함수를 호출하여 인접한 가용 블록과 병합합니다.
static void place(void *bp, size_t asize) {
size_t csize = GET_SIZE(HDRP(bp)); // 현재 블록사이즈
remove_block(bp); // 블록 가용리스트에서 지우기
if ((csize - asize) >= (2 * DSIZE)) // 필요한 블록 이외에 남는게 16바이트 이상이면 분할
{
PUT(HDRP(bp), PACK(asize, 1)); // 일단 할당블록 처리
PUT(FTRP(bp), PACK(asize, 1));
bp = NEXT_BLKP(bp); // bp를 다음 블록으로 이동
// 나머지 사이즈를 free
PUT(HDRP(bp), PACK(csize - asize, 0));
PUT(FTRP(bp), PACK(csize - asize, 0));
coalesce(bp);
} else {
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
}
}
coalesce함수
coalesce 함수는 인접한 가용 블록들을 병합하여 더 큰 가용 블록을 만드는 역할을 합니다.
-
이전 블록과 다음 블록의 할당 여부를 확인합니다.
-
이전 블록과 다음 블록 모두 할당되어 있는 경우, 현재 블록을 가용 리스트에 삽입하고 반환합니다.
-
이전 블록은 할당되어 있고 다음 블록이 가용 상태인 경우, 다음 블록을 가용 리스트에서 제거하고 현재 블록과 병합합니다. 병합된 블록의 헤더와 푸터를 설정합니다.
-
이전 블록이 가용 상태이고 다음 블록은 할당되어 있는 경우, 이전 블록을 가용 리스트에서 제거하고 현재 블록과 병합합니다. 병합된 블록의 헤더와 푸터를 설정하고
bp를 이전 블록으로 이동시킵니다. -
이전 블록과 다음 블록 모두 가용 상태인 경우, 이전 블록과 다음 블록을 가용 리스트에서 제거하고 현재 블록과 병합합니다. 병합된 블록의 헤더와 푸터를 설정하고
bp를 이전 블록으로 이동시킵니다. -
병합된 블록을 가용 리스트에 삽입하고 반환합니다.
static void *coalesce(void *bp) {
size_t is_prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); // 이전 블록의 할당 여부
size_t is_next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); // 다음 블록의 할당 여부
size_t size = GET_SIZE(HDRP(bp));
if (is_prev_alloc && is_next_alloc) { // 앞,뒤 모두 사용불가
insert_block(bp, size);
return bp;
} else if (is_prev_alloc && !is_next_alloc) // 뒤에만 쓸 수 있는 블록일 때
{
remove_block(NEXT_BLKP(bp)); // 뒤 블록 지우고 합친 사이트를 가용리스트에 넣을 준비( insert 함수 )
size += GET_SIZE(FTRP(NEXT_BLKP(bp))); // 합친 블록 사이즈
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
} else if (!is_prev_alloc && is_next_alloc) // 앞에만 쓸 수 있는 블록일 때
{
remove_block(PREV_BLKP(bp)); // 앞 블록 지우고 합친 사이트를 가용리스트에 넣을 준비( insert 함수 )
size += GET_SIZE(HDRP(PREV_BLKP(bp))); // 현재 블록 사이즈에 이전 블록 사이즈를 합침
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp); // 앞으로 bp 옮겨줘야함
} else if (!is_prev_alloc && !is_next_alloc) // 앞과 뒤 모두 free block일 경우
{
// NOTE 크게 합쳐줘야하니까 앞뒤 블록 다 지우기 (가용리스트에서 지운다는 뜻)
remove_block(PREV_BLKP(bp));
remove_block(NEXT_BLKP(bp));
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp))); // 둘다 합친 사이즈로 갱신
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp); // 앞으로 bp 옮겨줘야함
}
insert_block(bp, size); // 바뀐 사이즈 기반으로 insertblock 해줌
return bp;
place 함수와 coalesce 함수를 통해 블록의 분할과 병합을 효과적으로 처리할 수 있습니다. 이를 통해 메모리 할당의 효율성을 높이고 외부 단편화를 줄일 수 있습니다.
5. Segregated List 관련 함수
Segregated List를 효과적으로 관리하기 위해 remove_block과 insert_block 함수를 구현했습니다. 이 함수들은 가용 블록을 리스트에서 제거하고 삽입하는 역할을 합니다.
remove_block 함수
remove_block 함수는 특정 블록을 Segregated List에서 제거하는 역할을 합니다.
- 블록의 크기를 기준으로 해당 블록이 속한 리스트의 인덱스를 계산합니다.
- 블록의
SUCC_FREE와PRED_FREE를 확인하여 다음과 같이 처리합니다:SUCC_FREE가 NULL이 아닌 경우 (리스트의 마지막 블록이 아닌 경우):PRED_FREE가 NULL이 아니면 (리스트의 중간 블록인 경우), 이전 블록의SUCC_FREE와 다음 블록의PRED_FREE를 서로 연결합니다.PRED_FREE가 NULL이면 (리스트의 첫 번째 블록인 경우), 다음 블록의PRED_FREE를 NULL로 설정하고 리스트의 첫 번째 블록을 다음 블록으로 변경합니다.
SUCC_FREE가 NULL인 경우 (리스트의 마지막 블록인 경우):PRED_FREE가 NULL이 아니면 (리스트의 마지막 블록인 경우), 이전 블록의SUCC_FREE를 NULL로 설정합니다.PRED_FREE가 NULL이면 (리스트에 블록이 하나만 있는 경우), 리스트를 NULL로 초기화합니다.
insert_block 함수
insert_block 함수는 특정 블록을 Segregated List에 삽입하는 역할을 합니다.
- 블록의 크기를 기준으로 해당 블록이 속할 리스트의 인덱스를 계산합니다.
- 리스트를 탐색하면서 삽입할 위치를 찾습니다. 이때
insert_ptr은 삽입할 위치의 이전 블록을 가리키고,search_ptr은 삽입할 위치의 다음 블록을 가리킵니다. search_ptr이 NULL이 아닌 경우 (삽입할 위치가 리스트의 끝이 아닌 경우):insert_ptr이 NULL이 아니면 (리스트의 중간에 삽입하는 경우), 새로운 블록의SUCC_FREE와PRED_FREE를 적절히 설정하여 이전 블록과 다음 블록 사이에 삽입합니다.insert_ptr이 NULL이면 (리스트의 첫 번째 위치에 삽입하는 경우), 새로운 블록의SUCC_FREE를search_ptr로 설정하고,PRED_FREE를 NULL로 설정합니다. 그리고 리스트의 첫 번째 블록을 새로운 블록으로 변경합니다.
search_ptr이 NULL인 경우 (삽입할 위치가 리스트의 끝인 경우):insert_ptr이 NULL이 아니면 (리스트의 마지막에 삽입하는 경우), 새로운 블록의SUCC_FREE를 NULL로 설정하고,PRED_FREE를insert_ptr로 설정합니다. 그리고 이전 블록의SUCC_FREE를 새로운 블록으로 설정합니다.insert_ptr이 NULL이면 (리스트가 비어있는 경우), 새로운 블록의SUCC_FREE와PRED_FREE를 NULL로 설정하고, 리스트의 첫 번째 블록을 새로운 블록으로 변경합니다.
remove_block과 insert_block 함수를 통해 Segregated List에서 블록을 효과적으로 제거하고 삽입할 수 있습니다. 이를 통해 가용 블록을 관리하고 할당 및 해제 요청을 처리할 수 있습니다.
재할당 로직 개선
초기 구현에서는 재할당 요청 시 무조건 새로운 메모리를 할당받고, 기존 데이터를 복사한 후 이전 메모리를 해제하는 방식으로 처리했습니다. 그러나 이 방식은 불필요한 메모리 할당과 복사 연산으로 인해 효율성이 떨어질 수 있습니다.
이를 개선하기 위해 mm_realloc 함수에서 이전 블록과 다음 블록을 활용하여 블록 확장을 시도하도록 수정했습니다. 개선된 로직은 다음과 같이 동작합니다:
-
재할당 요청 시 요청된 크기(
size)를 정렬하여asize로 계산합니다. -
현재 블록의 크기(
copySize)와asize를 비교합니다.asize가copySize보다 작거나 같으면 현재 블록을 그대로 사용합니다.asize가copySize보다 크면 블록 확장을 시도합니다.
-
블록 확장을 시도할 때는 다음 블록과 이전 블록을 확인합니다.
- 다음 블록이 가용 상태이고, 다음 블록의 크기와 현재 블록의 크기를 합쳐서
asize보다 크거나 같으면 다음 블록과 병합하여 현재 블록을 확장합니다. - 이전 블록이 가용 상태이고, 이전 블록의 크기와 현재 블록의 크기를 합쳐서
asize보다 크거나 같으면 이전 블록과 병합하여 현재 블록을 확장합니다.
- 다음 블록이 가용 상태이고, 다음 블록의 크기와 현재 블록의 크기를 합쳐서
-
블록 확장이 가능한 경우, 해당 블록을 가용 리스트에서 제거하고 병합된 블록의 헤더와 푸터를 업데이트합니다. 이때
memmove함수를 사용하여 데이터를 복사합니다. memmove 공식문서 -
블록 확장이 불가능한 경우, 새로운 메모리를 할당받고 기존 데이터를 복사한 후 이전 메모리를 해제하는 기존 로직을 수행합니다.
개선된 mm_realloc 함수의 코드는 다음과 같습니다:
void *mm_realloc(void *ptr, size_t size) {
void *oldptr = ptr;
int asize = ALIGN(size + SIZE_T_SIZE);
size_t copySize = GET_SIZE(HDRP(oldptr));
if (ptr == NULL) {
return mm_malloc(asize);
}
if (size == 0) {
mm_free(ptr);
return NULL;
}
if (asize <= copySize) {
return oldptr;
} else { // 기존 블럭보다 필요한 size가 더 클 때
if (GET_ALLOC(HDRP(NEXT_BLKP(oldptr))) == 0 && (GET_SIZE(HDRP(NEXT_BLKP(oldptr))) + copySize) >= asize) {
size_t nextSize = GET_SIZE(HDRP(NEXT_BLKP(oldptr)));
remove_block(NEXT_BLKP(oldptr));
PUT(HDRP(oldptr), PACK(copySize + nextSize, 1));
PUT(FTRP(oldptr), PACK(copySize + nextSize, 1));
return oldptr;
} else if (GET_ALLOC(FTRP(PREV_BLKP(oldptr))) == 0 && (GET_SIZE(FTRP(PREV_BLKP(oldptr))) + copySize) >= asize) {
size_t prevSize = GET_SIZE(FTRP(PREV_BLKP(oldptr)));
remove_block(PREV_BLKP(oldptr)); // 이전 블록을 제거
void *newptr = PREV_BLKP(oldptr);
memmove(newptr, oldptr, copySize); // mecpy랑 비슷! 데이터를 임시로 저장한 다음에 데이터 복사 / 겹치는 것 방지
PUT(HDRP(newptr), PACK(copySize + prevSize, 1));
PUT(FTRP(newptr), PACK(copySize + prevSize, 1));
return newptr;
} else {
void *newptr = mm_malloc(asize);
if (newptr == NULL) {
return NULL;
}
memcpy(newptr, oldptr, copySize);
mm_free(oldptr);
return newptr;
}
}
}이러한 개선을 통해 불필요한 메모리 할당과 복사 연산을 줄일 수 있었습니다. 인접한 가용 블록을 활용하여 블록을 확장함으로써 메모리 사용 효율성을 높이고 성능을 향상시킬 수 있었습니다.
결과 및 성능 향상
realloc 개선결과 84점에서 -> 90점으로 util부분의 점수가 개선되었습니다.

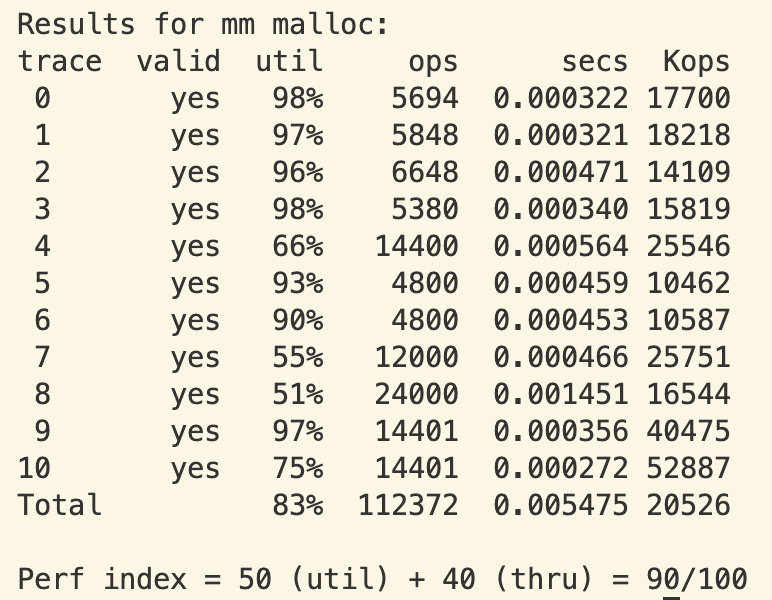
Segregated Free List를 활용한 동적 메모리 할당 최적화를 통해 다음과 같은 성능 향상을 얻을 수 있었습니다.
- 빠른 할당 및 해제: 크기 클래스별로 가용 블록을 관리하므로 적합한 블록을 빠르게 찾을 수 있었습니다.
- 메모리 사용 효율성 향상: 블록의 크기에 따라 적절한 크기 클래스를 사용하여 메모리 낭비를 줄일 수 있었습니다.
- 외부 단편화 감소: 블록을 크기별로 분리하여 관리함으로써 외부 단편화를 줄일 수 있었습니다.
앞 혹은 뒤의 할당가능한 블록과 합친 뒤에 또 16바이트가 넘게 남으면 분할을 해주는 로직을 추가했었는데, 오히려 점수가 88점으로 낮아지는것을보고 잠시 지웠습니다..
마치면서
Segregated Free List를 사용할 때는 블록의 크기에 따라 적절한 크기 클래스를 사용하는 것이 중요한 것 같습니다. 크기 클래스를 정하는게 좀 자율적이라서, 크기 클래스를 어떻게 설정하느냐에 따라 할당 효율과 메모리 사용량이 크게 달라질 것입니다. 아마 테스트케이스에서 실제 할당 요청되는 데이터의 크기 분포를 파악하고, 이에 맞게 크기 클래스를 조절하면 점수가 더 높게 나올 것입니다!
특징으로, Segregated List는 메모리 오버헤드와 내부 단편화가 심해질 수 있습니다. 만약 할당 요청의 크기 분포에 맞지 않게 크기 클래스를 설계하면, 클래스를 탐색하는 시간이 늘어나거나 새로운 힙 메모리를 자주 할당받게 되어 단편화 문제가 심각해질 수 있습니다. 이러한 단점을 최소화하기 위해서는 또 다시 언급하지만, 메모리 사용 패턴을 면밀히 분석하고, 적절한 크기 클래스를 설계하는 것이 중요합니다.
이번 프로젝트를 진행하면서 초반에는 C언어 사용법을 익히는 데 시간을 많이 할애했고, 프로젝트 시작 시에는 구현 방법에 대한 감을 잡기 어려워 시간을 허비하기도 했습니다. 하지만 블로그를 참고하고 로직을 수정해가면서 점수를 높이는 과정에서, 전체적인 코드의 흐름을 이해할 수 있게 되었습니다.
아무것도 모르는 상태에서 무언가를 이렇게 구현한 경험은, 앞으로의 공부 방식에 있어서도 도움이 될 것 같았습니다.
