데이터베이스
- 데이터베이스 : 여러 사람에 의해 공유되어 사용될 목적으로 통합하여 관리되는 데이터의 집합
엑셀, 스프레드 시트같은 프로그램과의 차이점은, 먼저 컴퓨터 언어로 제어할 수 있다는 특징이 있으며, 다른 사람들과 공유가 더 쉽고 사용자에 따라서 권한을 부여할 수 있다는 점 등 다양한 장점을 가지고 있는 데이터 저장 매체가 데이터 베이스이다.
다양한 데이터베이스가 존재하고 각각의 데이터베이스마다 데이터를 저장하고 수정하는 매커니즘이 다르다. 그 중에서 가장 많이 사용되는 데이터베이스 중 하나인 MySQL을 다뤄보는 강의였다.
MySQL 은 크게 3가지 구조로 구분돼있다.
1. DB server
2. 스키마(database)
3. table
이렇게 세분화 돼있는 건 방대한 양의 데이터를 다룰 때 더 효율적으로 데이터를 처리하기 위함이다.
SQL = Structured Query Language
즉 데이터를 다루는 언어, 많은 컴퓨터 언어들 중 가장 쉬운편에 속하지만 매우 중요하다.
모든 데이터베이스를 다루는 기본 언어가 되기 때문이다.
SQL의 가장 큰 틀은 CRUD 이다.
C: Create
R: Read
U: Update
D: Delete
관계형 데이터베이스
관계형 데이터베이스를 이루는 가장 기본적인 단위는 TABLE이다. TABLE 이 모여서 스키마(DATABASE) 를 이루고 스키마가 모여 DB 서버를 형성한다.
TABLE의 구조
가로 : column (열) , 데이터의 타입을 결정
세로 : row,record(행) , 각각의 데이터
TABLE은 각각 PK(primary key)를 가지고 있어 이 키 값을 통해 다른 테이블과 관계를 맺을 수 있다. 또 PK가 존재하기 때문에 각각의 데이터는 데이터의 값들이 중복되더라도 서로 다른 데이터임을 구분할 수 있게 된다.
EX) PK=1 인 21세 철수/ PK=199 인 21세 철수
RDB는 중복되는 데이터를 최소화하기 위해 데이터들을 속성에 따라 분류하고 테이블에 저장함으로써, 중복 DATA를 최소화 한다. 덕분에 데이터 수정이 용이해지며, 중복되는 데이터로 발생하는 낭비를 없앤다.
하지만 테이블로 분류되면서 데이터가 분산되므로 직관적이지 않다는 단점이 있다.
이 단점을 해결하기 위해 JOIN이라는 기능이 있다.
JOIN
JOIN이란 RDB에서 분리된 테이블들을 PK값에 따라서 하나로 합치는 과정을 뜻한다.

예를들어 위 두 테이블을 하나로 합칠 때 author_id 와 author의 aid를 통해 서로 관계를 맺는다고 하면,
SELECT * FROM topic LEFT JOIN author ON topic.author_id = author.aid

위와 같은 SQL 명령어를 사용해서 두 테이블을 JOIN 할 수 있다.
JOIN에는 LEFT,RIGHT,INNER,OUTER 이렇게 네 종류의 JOIN 이 있다.
간단히 분류하자면
A TABLE / B TABLE 이 있으면
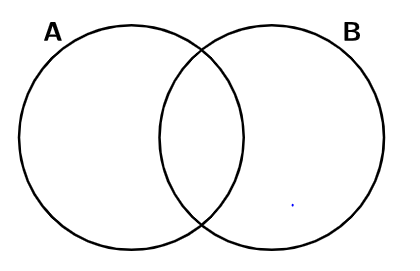
* A 기준
LEFT JOIN : A
RIGHT JOIN : B
INNER JOIN : A - (A와B의 교집합)
OUTER JOIN : A+B - (A와B의 교집합)
RIGHT는 LEFT의 반대이고 OUTER은 거의 쓸 일이 없다.
따라서 조건에 따라 LEFT와 INNER를 선택적으로 잘 활용한다. 성능적인 측면에서는 INNER가 더 효율적이라고 한다.
JOIN 과 같은 데이터베이스의 기능을 구현해둔 방법이 데이터베이스마다 다르고 그에 따라 성능향상을 위해 고려해야되는 부분들도 각각 다르다.
