1. 데이터베이스 기본 개념
데이터 베이스는 우리가 사용하는 정보의 총 집합
1-1. Database 기초 이해
-
데이터베이스의 정의(Oracle; 대표적 database 회사)
데이터베이스는 일반적으로 구조화된 information이나 데이터의 구조화된 컬렉션이며 이 정보와 데이터들은 컴퓨터 시스템에 의해 전자적으로 저장되었습니다. 데이터베이스는 보통 데이터베이스 매니지먼트 시스템(DBMS)에 의해서 제어됩니다. Data와 DBMS는 연관된 어플리케이션과 함께 '데이터베이스 시스템'으로 간주됩니다, 또한 이 둘은 총체적으로 'databases'라고 요약해서 간주됩니다. -
Data base

데이터 베이스는 이렇게 큰 부지에 데이터 센터를 말하기도 한다.
-
데이터베이스의 구조
아래 예시는 데이터베이스가 저장하고 있는 데이터를 보여준다.
엑셀표처럼 관리하고 아래 표 에서는 영화의 title, release-year, length, replacement.cost 등을 저장하고 있다.
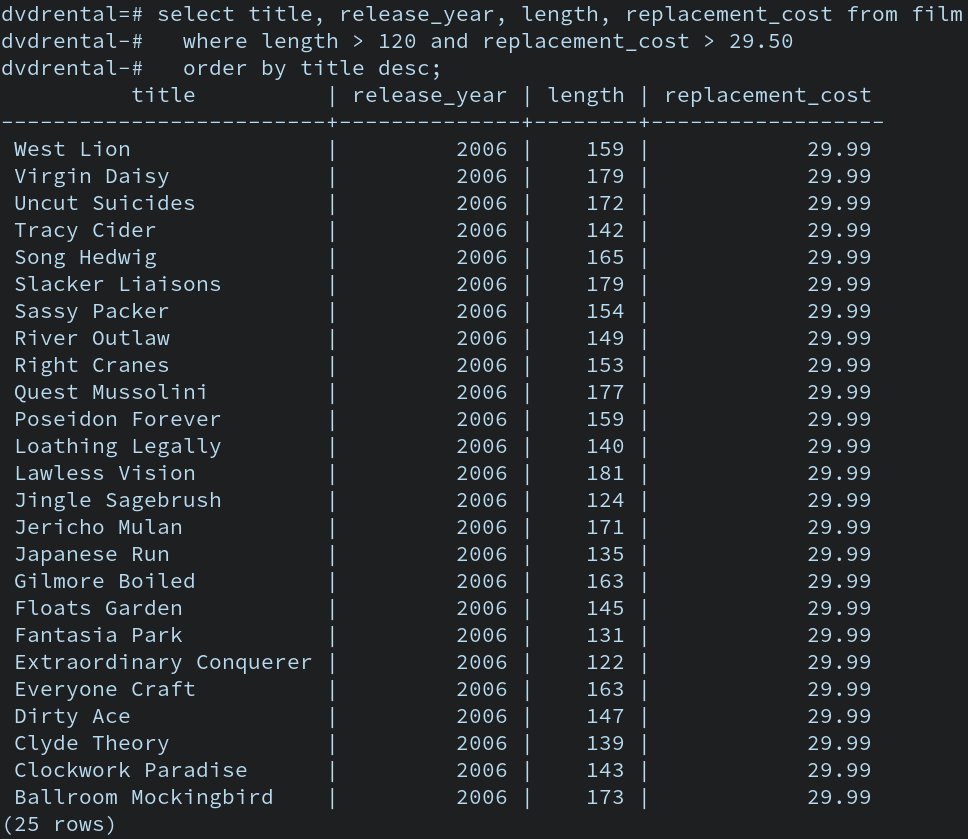
-
데이터베이스의 제어와 관리
data는 DBMS로 제어하고 관리한다. 데이터베이스의 정의에서 보았듯이 데이터 베이스 시스템은 데이터와 DBMS 그리고 관련 어플리케이션을 통틀어서 일컫는 것이고 짧게는 데이터베이스라고 부르기도 한다.
1-2. 데이터베이스를 사용하는 이유?
-
데이터를 오랜 기간 저장 & 보존하기 위함.
어플리케이션에서도 데이터를 임시로 저장할 수 있지만 우리가 저장하지 않은 데이터는 컴퓨터를 재부팅하면 사라진다. 따라서 필요한 자료를 보존하기 위해서 데이터베이스를 사용한다.
-
데이터를 체계적으로 보존하고 관리하기 위함.
데이터는 필요할 때 언제든 유저가 원하는 자료를 쉽게 읽어낼 수 있어야 의미 있는 정보라고 할 수 있다.
데이터베이스에 데이터를 체계적으로 정리, 입력해야 다시 찾을 때 쉽게 접근이 가능하다.1-3. 요약
데이터베이스는 의미 그대로 데이터들을 저장한 베이스이다. 즉 컴퓨터 시스템에 저장된 정보나 데이터를 모두 모아 놓은 집합을 의미한다.
데이터베이스의 사용 이유는 데이터를 오래 저장하고 체계적으로 보존하기 위함이다.
2. 관계형 Database
데이터베이스에는 크게 관계형 데이터베이스(RDBMS)와 "NoSQL"로 불리는 비관계형(Non-relational) 데이터베이스로 분류한다.
2-1. 관계형 데이터베이스
관계형 데이터베이스 : 데이터 간의 관계에 기초르 둔 DBMS.
관계형 DBMS의 모든 데이터는 2차원 table로 표현 가능.
-
2차원 테이블

Column은 테이블의 항목(id, 책 제목 등..)
row는 각 항목들의 실제 value.각 row는 자신만의 고유 키(primary key)가 있다.
(Id행의 1~5)이 고유 키를 통해서 특정 로우를 찾거나 인용(reference)할 수 있고 데이터베이스는 수천개의 테이블로 구성되어 있다.
관계형 데이터베이스는 각각의 테이블들이 서로 "상호관련성"을 가지고 연결되어 있다. 즉 각 테이블들은 완전히 독립된 대상이 아니라는 것이다.
2-2. 테이블 사이 관계의 종류
테이블 간의 연결에는 3가지 종류가 있다.
(중요!!) One to One(일대일), One to Many(일대다), Many to Many(다대다) 관계라고 부른다. RBDMS 내부에 테이블A와 B가 있으면 이 두 테이블은 무조건 위 세 종류의 관계 가운데 한가지 관계에 해당된다.
세가지 테이블 설명- 일대일

하나의 A 데이터는 하나의 B 데이터와 연결됩니다. 하나의 B 데이터 또한 하나의 A 데이터와 연결됩니다.
같은 이름들을 중복 저장하면 불필요한 메모리를 사용하기 때문에 user테이블에 이름을 저장하고 id number테이블에서는 이름을 또 저장하는게 아니라 해당 user_id 저장하는데 이를 "참조한다"라고 표현한다.
<Identification numbers 테이블의 user 컬럼은 users 테이블의 id(pk; primary key)를 참조한다>

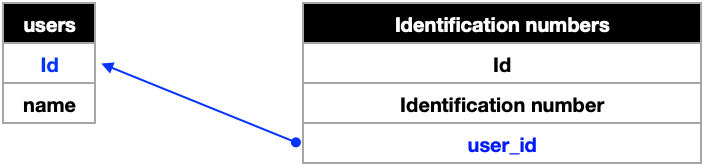
- 일대다
테이블 A의 로우가 테이블 B의 여러 로우와 연결이 되는 관계
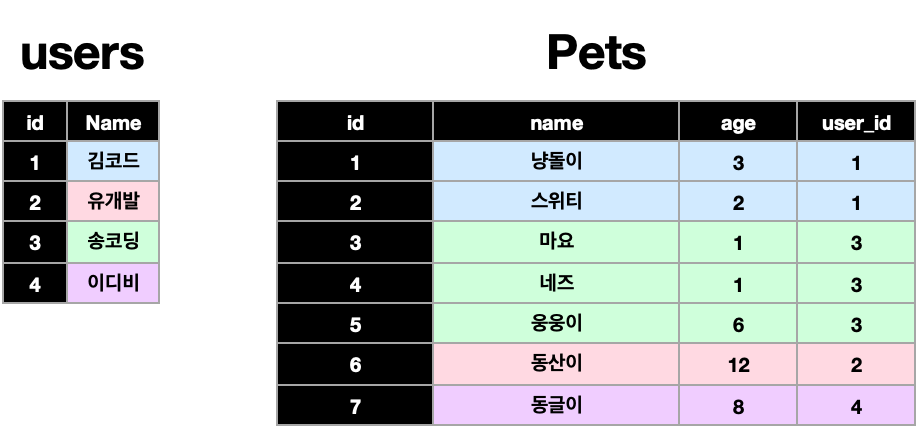 (가정 : 가족 x 동물한마리- 주인한마리)
(가정 : 가족 x 동물한마리- 주인한마리)
유저테이블의 하나의 로우가 pets테이블의 여러 로우와 연결되는 것을 One to Many관계라고 한다.
<pets 테이블의 user 컬럼은 users 테이블의 id(pk)를 참조한다>
1:1은 오직 로우 한개 : 로우 한개
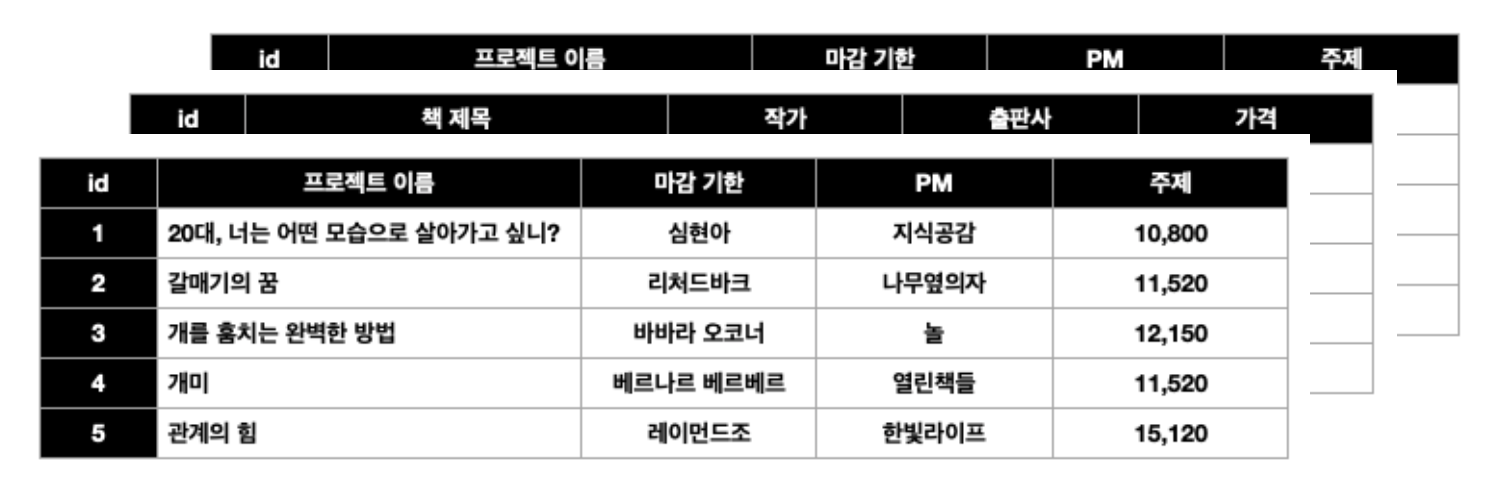
1:N은 로우한개 : 로우 여러개 - 다대다
한 작가 - 여러권 책
한 책 - 여러 작가
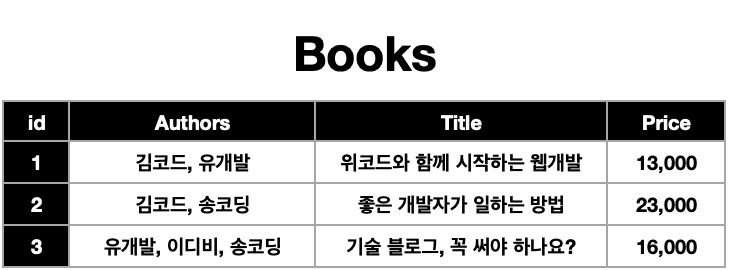 책이라는 테이블의 컬럼에 작가 타이틀 가격이 입력되어 있다. 작가컬럼에는 여러개의 데이터가 들어있는데 이는 정규화 제1법칙에 위반되는 것으로 이런 형식으로 저장할 수 없다. 테이블의 행 하나에는 딱 하나의 데이터만 들어갈 수 있음!
책이라는 테이블의 컬럼에 작가 타이틀 가격이 입력되어 있다. 작가컬럼에는 여러개의 데이터가 들어있는데 이는 정규화 제1법칙에 위반되는 것으로 이런 형식으로 저장할 수 없다. 테이블의 행 하나에는 딱 하나의 데이터만 들어갈 수 있음!
따라서 아래와 같이 풀어서 저장해야 한다.
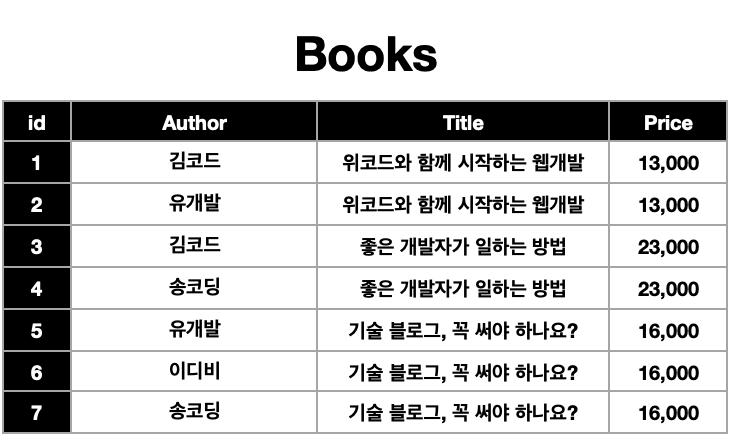 하지만 문제가 또 발생하는데 작가의 이름과 타이틀이 중복되어 저장되고 있다. 그 결과 책 한 권이 늘어날 때마다 작가의 수에 맞추어 똑같은 데이터를 또 여러번 저장해 주어야 하는 문제가 발생한다.
하지만 문제가 또 발생하는데 작가의 이름과 타이틀이 중복되어 저장되고 있다. 그 결과 책 한 권이 늘어날 때마다 작가의 수에 맞추어 똑같은 데이터를 또 여러번 저장해 주어야 하는 문제가 발생한다.
이는 Foreign Key를 사용하여 해결할 수 있고 데이터베이스에서 FK를 사용하는 가장 큰 이유 중 하나이다.
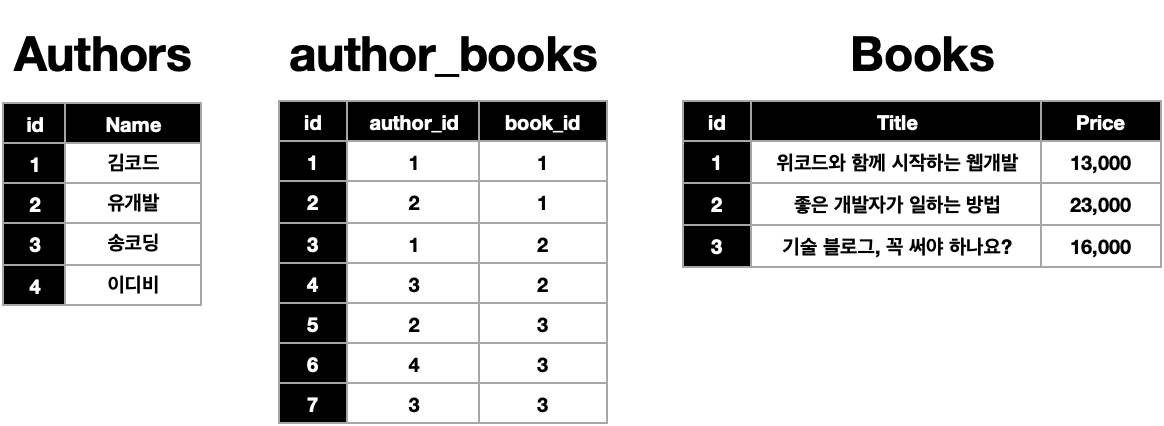 Authors 테이블의 로우 하나는 Books 테이블의 여러 로우와 연결됩니다. Books 테이블의 로우 하나 또한 Authors 테이블의 여러 로우와 연결
Authors 테이블의 로우 하나는 Books 테이블의 여러 로우와 연결됩니다. Books 테이블의 로우 하나 또한 Authors 테이블의 여러 로우와 연결 테이블 authors와 테이블 books는 서로 다대다 관계
테이블 authors와 테이블 books는 서로 다대다 관계
- 일대일
2-3. 테이블 사이 관계의 종류
-
Foreign key(외부키)라는 개념을 사용하여 주로 연결
-
아래의 일대일 예에서 user_profiles 테이블의 user_id컬럼은 users 테이블에 걸려있는 외부 키라고 지정

-
즉 데이터 베이스에게 user_id 값은 users 테이블의 id값이고 user 테이블의 id컬럼에 존재하는 값만 생성 가능
-
만약 users 테이블에 없는 id값이 user_id에 지정되면 error가 발생한다.
2-4 왜 테이블을 연결하냐 ?
왜 정보를 여러 테이블에 나누어 저장할까?
하나의 테이블에 모든 정보를 넣게 되면 동일 정보가 불필요하게 중복 저장이 된다. 더 많은 디스크를 사용하게 되고 잘못된 데이터가 저장 될 가능성이 높아진다.
예를 들어 고객 아이디는 동일하지만 이름이 서로 다른 로우들이 있다면 무엇이 정확한 이름일까?
이런 문제는 여러 테이블에 정보를 나누어 저장하고 필요한 테이블끼리 연결하게 되면 문제가 해결된다. 중복 데이터를 저장하지 않아 디스크의 효율성이 증가하고 서로 같은 데이터이지만 부분적으로만 내용이 다른 데이터가 생기는 문제를 없앤다.
이를 "normalization(정규화)"라고 한다.
2-5 요약
관계형 데이터베이스(RDBMS)는 모든 데이터를 2차원 테이블에 저장한다. 타입은 3가지 종류가 있다. (일대일, 일대다, 다대다)
