1. Why Clean Code
- SW는 한번 작성되면 최소 10번 이상 읽힌다. 그래서 대충 돌아가게만 작성하면 안되고 읽기 편하게 작성해야 한다.
- 여러분들의 주 업무는 무엇인가? 매번 새로운 코드를 작성하나? 남이 작성한 코드를 읽고, 수정하고, 기능을 추가하는 일을 하는가?
- 기계가 이해할 수 있는 코드는 어느 바보도 작성할 수 있다. 하지만 인간이 이해할 수 있는 코드는 잘 훌련되 소프트웨어 엔지니어만이 작성할 수 있다.
2. Why OOP
구조적 프로그래밍
절차지향
- SW = Data + Data를 조작하는 Code
- 알아야할 것이 적어 초기 진입이 쉽다.
- Data 변경이 많은 영향을 미침
- Data 변경이 어려워짐
- 모든 프로시저가 데이터를 공유
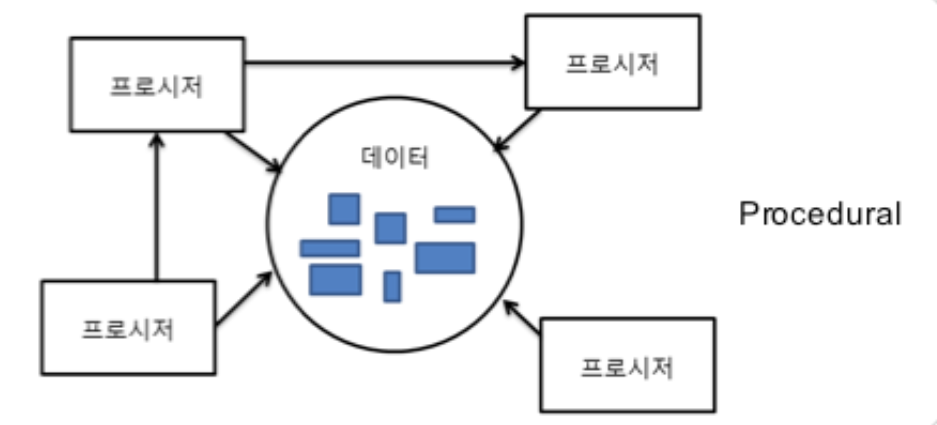
프로시저가 모든 데이터를 공유. 그 프로시저를 또 다른 프로시저가 참조.
데이터의 변경(혹은 그 데이터를 참조하는 프로시저의 변경)이 참조를 타고 시스템 전역으로 영향을 미친다.
데이터를 어떤 프로시저가 사용할지 예측할 수 없고, 그 프로시저를 어떤 프로시저에서 참조하고 있을지 알 수 없어, 사소한 변경도 프로그램 전역에 영향을 미친다.
따라서 기존의 코드를 변경하는 것이 거의 불가능해진다.
그래서 이걸 비슷한 기능을 수행하는 것을 복붙하고 이름을 바꿔서 사용한다.
해당 기능에 오류가 생겨서 디버깅을 하고 그 곳을 수정해 재배포했지만, 복붙한 곳의 수정을 빼먹게된다. 사용자 입장에서 개발자가 제대로 수정을 수행하지 못한 것으로 인해 신뢰를 잃을 수 있다.
객체지향
- 데이터와 코드가 Encapsulated
- 데이터와 그 데이터를 조작하는 코드의 변경은 외부에 영향을 안 미침
- 외부에 노출된 인터페이스만 변경되지 않는다면 프로시저를 실행하는데 필요한 만큼의 데이터만 가짐
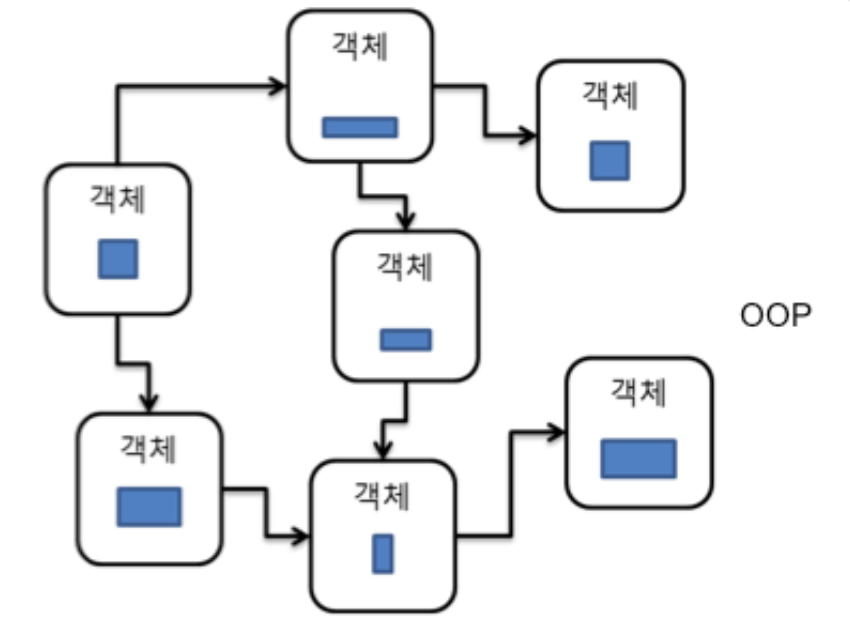
객체지향은 데이터를 공유해 사용하지 않는다.
그 데이터를 사용하는 기능들을 객체라는 이름으로 래핑을 해두고, 그 데이터에 변경이 생기면 해당 객체만 영향을 받는다.
또한 다른 객체를 사용할 때, 해당 객체의 인터페이스를 통해 의사소통해야하며, 해당 객체의 구체적인 내부 내용을 알아서는 안된다.
구체적으로 알 수록 많은 영향을 받게 되고, 변경이 힘들게 된다.
처음부터 객체지향적으로 설계하는 것은 쉽지 않다.
처음에는 절차지향적으로 코드를 분석하고, 이것을 객체지향적으로 변경하는 방식이 자주 사용된다. 이 과정을 리팩토링이라고 부른다. 일단 거지같이 만들고, 예쁘게 변경하는 것.
코드를 짤 때 내 코드를 다른 사람이 유지보수할 예정이고, 그 사람이 내 주소를 알고있으며 총을 가지고 있다는 생각으로 코드를 작성해야 한다.ㅋㅋㅋ
뭘 선택해야 할까?
- 단순하고 쉬운 시스템은 절차지향을 적용해도 된다.
- 개발진이 객체지향적인 준비가 되어있지 않은 경우
- 이벤트성으로 한번 사용되고 재사용할 일이 없는 코드인 경우
- 단순하고 쉬운 시스템이라는 것이 존재할까?
- 단순하고 쉬운 시스템은 학교 과제, 논문용 프로젝트 같은 것들을 말한다. 회사의 프로젝트를 단순하고 쉽다고 표현하기 힘들다. 변경되지 않는, 추가되지 않는 일은 없다고 봐도 된다.
- 복잡하거나 요구사항 변화가 발생할 시스템은 객체지향으로 설계해라.
- 데이터의 변경이 해당 객체로만 제한되고 다른 객체에 영향을 미치지 않으므로
- Encapsulation
- SW는 계속 사용된다면 요구사항은 계속 바뀐다.
- 절차지향이 처음에는 쉬울지 모르나 시간이 지나면 수정하기 어려운 구조가 된다.
3. Object/Role/Responsibility
- 게시글; Board =>
BoardController,BoardService,BoardRepository방식으로 사용- 이는 잘못된 네이밍.
writeBoard가 적절한 이름.
- 이는 잘못된 네이밍.
- 객체/클래스의 이름은
- 무엇으로 정의해야 한다.
RequestParser⭕️ - 어떻게로 정의하지말고.
JsonRequestParser❌- JOSN이 아니라 다른 방식으로 바뀌면 어떻게 할 것인가? 전부 다 다시 변경해야 한다. 어떻게 집중한 네이밍은 적절하지 않다.
- 무엇으로 정의해야 한다.
- 역할은 관련된 책임의 집합
- 역할(Role): 게시글 사용자, 댓글쓰기 사용자, 운영자, 비로그인 사용자, ...
- 사용하는 기능으로 그룹핑되는 주요한 유저의 그룹 등을 역할이라고 부른다.
- 책임(Responsiblitiy): 그 역할을 만족시키기 위해 시스템에서 제곧외어야 하는 연관있는 기능들을 책임이라고 부른다.
- SRP에서 Responsiblity는 특정 유저를 만족시키기 위한 일련의 행위.
- 역할(Role): 게시글 사용자, 댓글쓰기 사용자, 운영자, 비로그인 사용자, ...
- 객체는 역할을 갖는다.
4. 객체지향 설계 과정
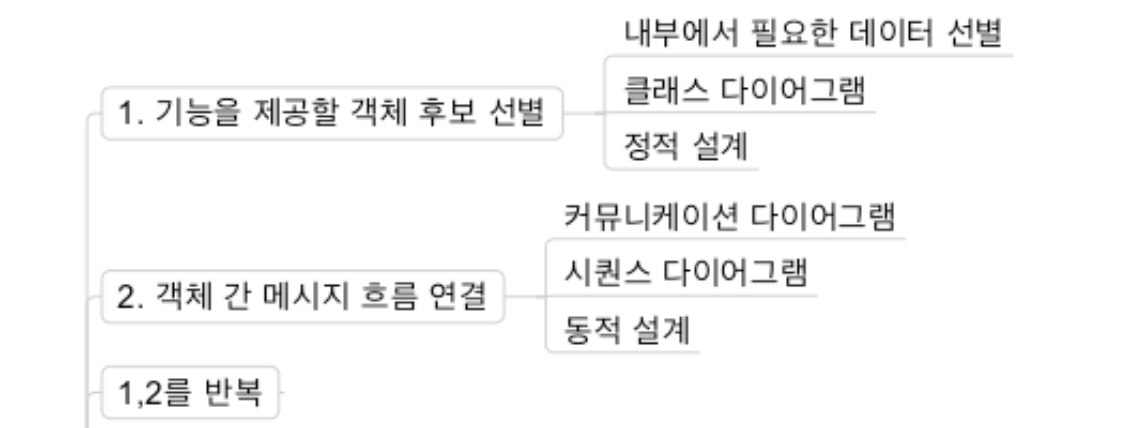
1) 기능을 제공할 객체 후보 선별
- 내부에서 필요한 데이터 선별
- 클래스 다이어그램
- 정적 설계
- erd같은 것들을 그려, 존재하는 상태를 선별한다.
- 파일암호화 예시
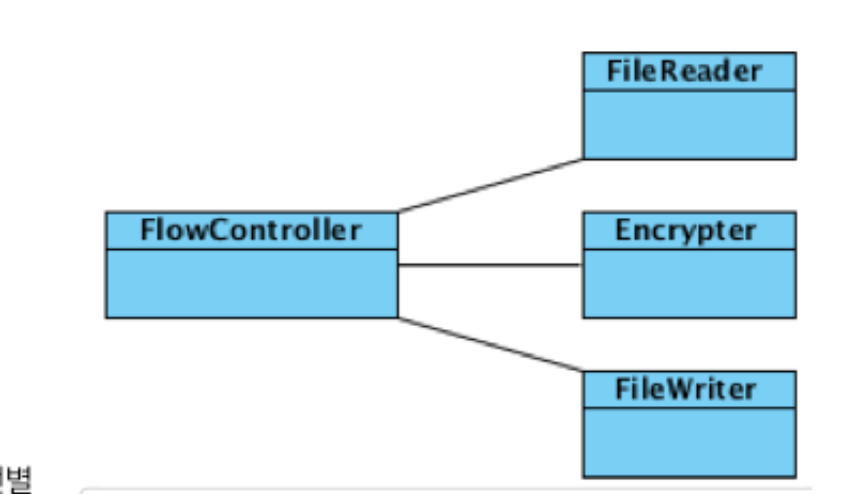
- 보통 FlowController에서 쭉 스파게티 코드로 코드를 작성하지, 역할을 식별해 다른 클래스로 기능을 빼는것이 잘 안된다. 여기서 특수한 역할들을 먼저 파악하고 클래스로 빼는 것이 쉽지 않다. 한 번에 이 구조가 완성되기 보다는 몇 번 코드가 수행된 이후에 클래스를 분리 결정이 이뤄졌을 것이다.
2) 객체 간 메시지 흐름 연결
- 커뮤니케이션 다이어그램
- 시퀀스 다이어그램
- 동적 설계
- 이후 그 데이트를 가지고 있는 클래스간에 어떤 메시지를 주고받아야 내가 원하는 기능이 나오는지를 설계한다. (커뮤니케이션 다이어그램, 시퀀스 다이어그램을 통해)
- 파일암호화 예시
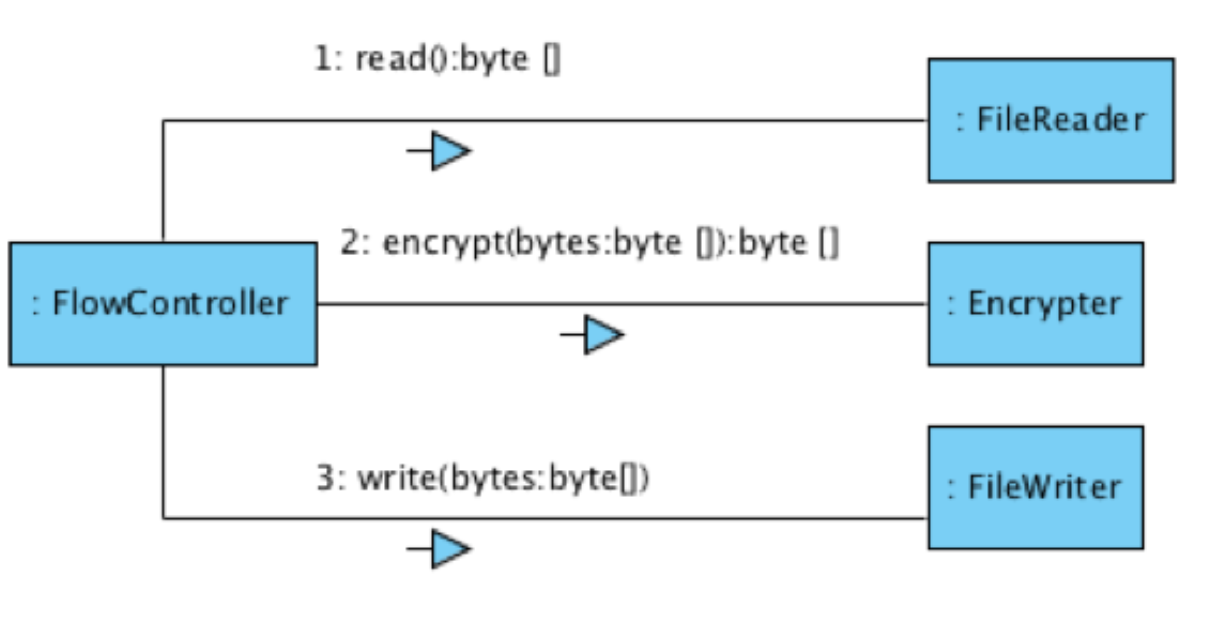
- 처음부터 나오기 보다는, 여러번 리팩토링을 거친 결과물에 가까울 것.
- 기능별로 인터페이스로 분리되어 있어 Unit Test가 용이하다.
- 만약 File이 아니라 다른 것으로 변경되더라도 (네트워크나 디비로 변경되더라도) FlowController는 변경되지 않는다. 비즈니스 로직은 Flowcontroller에 존재한다. FileReader는 라이브러리 같은 존재.
- 1번과 2번을 반복한다.
5. Encapsulation
- 내부적으로 어떻게 구현했는지를 감춰 내부의 변경(데이터, 코드)이 client가 변경되지 않도록 코드를 구현하는 것. 코드 변경에 따른 비용을 최소화한다.
- 객체지향의 기본
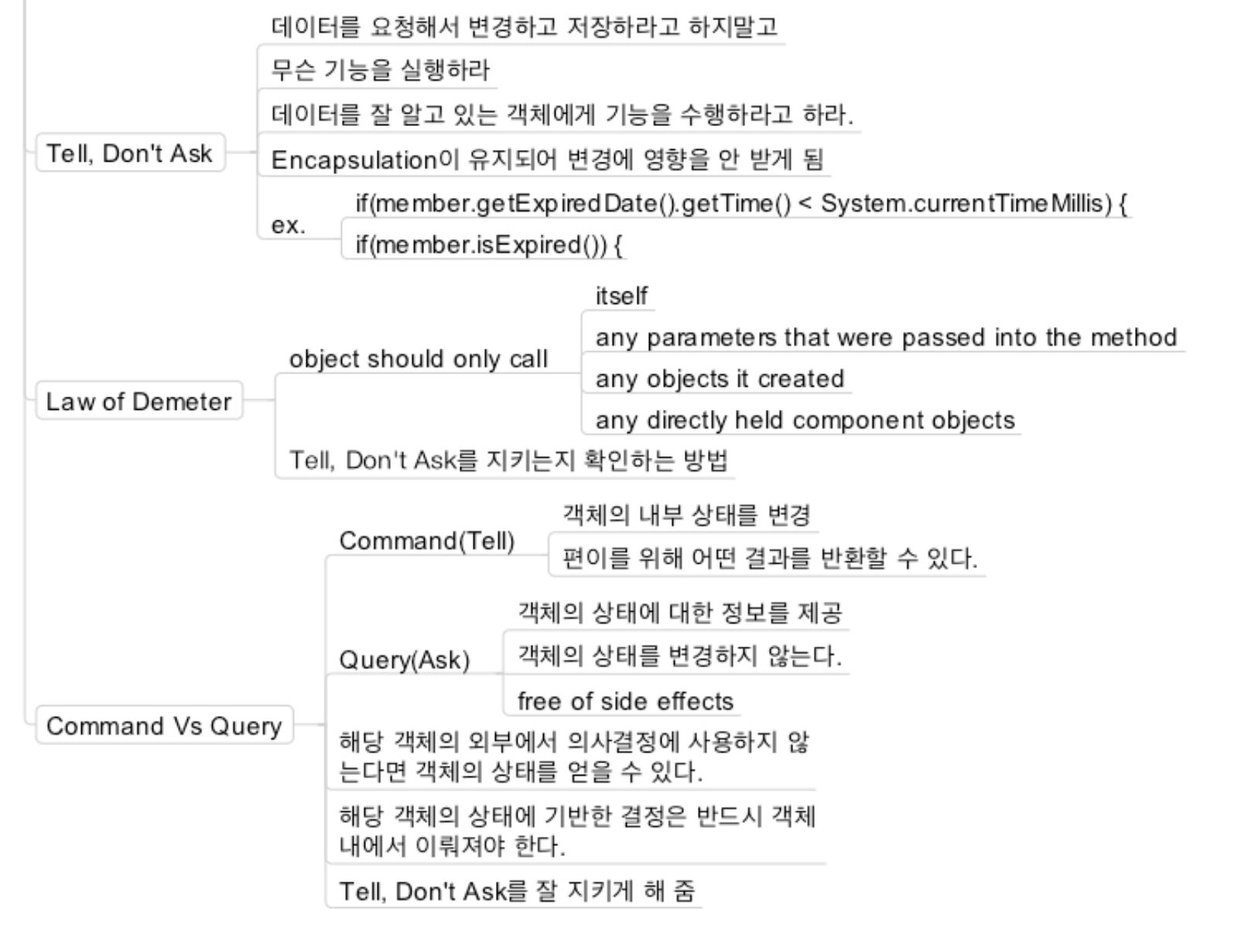
Tell, Don't Ask
- 데이터를 요청해서 변경하고 저장하라고 하지말고, 무슨 기능을 실행해라
- 데이터를 잘 알고 있는 객체에게 기능을 수행하라고 해라.
- Encapsulation이 유지되어 변경에 영향을 안 받게 된다.
if(member.getExpiredDate().getTime() < System.currentTimeMillis){❌if(member.isExpired()) {⭕️isExpired()가 변경되어도 클라이언트 코드는 영향을 받지 않는다.
Law of Demeter
- object should only call
- itself
- any parameters that were passed into the method
- any objects it created
- any directly held component objects
- Tell, Don't Ask를 지키는지 확인하는 방법
CQS; Command vs Query
- Command(Tell)
- 객체의 내부 상태를 변경
- 편이를 위해 어떤 결과를 반환할 수 있다.
- Query(Ask)
- 객체의 상태에 대한 정보를 제공
- 객체의 상태를 변경하지 않는다.
- free of side effects
- 해당 객체의 외부에서 의사결정에 사용하지 않는다면 객체의 상태를 얻을 수 있다.
- 해당 객체의 상태에 기반한 결정은 반드시 객체 내에서 이뤄져야 한다.
- Tell, Don't Ask를 잘 지키게 해줌
하나의 메서드가 상태를 2개 이상 변경하는 경우 곤혹스러울 수 있다.
1. instance variable이면 크게 문제가 안될수도 있다.
2. return variable이 있는 상황에서 필드가 2개 이상 변경되는 경우. 리팩토링이 거의 불가능하다.
메서드가 Command면 내부상태가 변경되고 리턴값이 없을 것이라고 기대한다.
메서드 이름이 Query처럼 생기면 내부상태를 변경하지 않을 것이라고 기대한다.
남들이 기대하는대로 개발하는게 맞다.
6. Polymorphism
다형성: 다양한 형을 갖는다.
- 객체지향의 다형성 구현 방법
Inheritance; 구현상속Implements; 인터페이스 상속
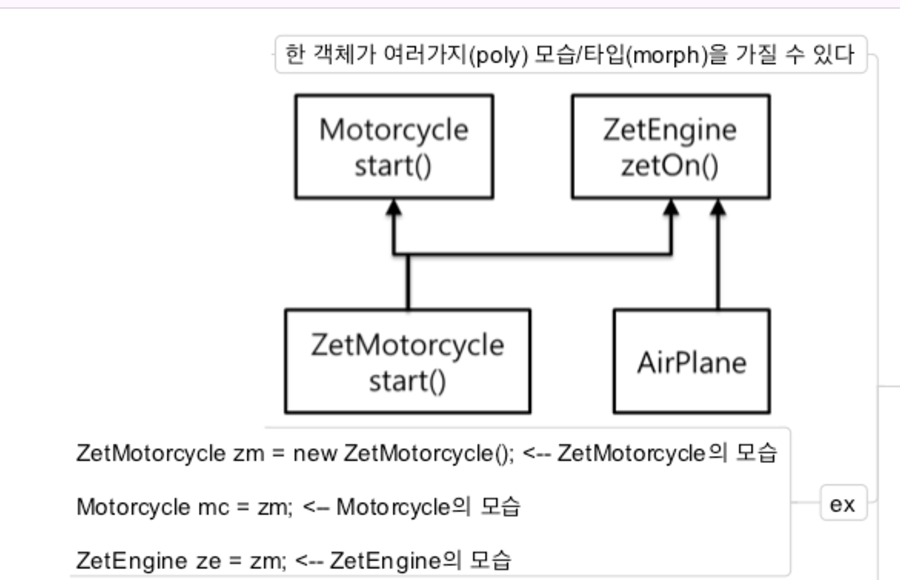
인터페이스해봐야 구현해야 할 메서드만 늘어나고, 슈퍼클래스 상속받으면 그거 쓸 수 있으니까, 그게 상속 아니야? >> 아님 ❌
그렇게 해놓으면 나중에 못고친다. 복잡한 상속 관계로 엮여있는 클래스 호출해서 사용 못한다. 그렇게 해놓으면 움직일 수 없는 상태에 빠진다. 인터페이스를 사용하는 부분을 재사용하는 것이 목적. 내 로직에서 변경 가능한 부분, 이 로직과 상관없는 부분을 외부에 구현한다. 그 외부를 바라볼 때, 인터페이스를 통해서 바라보는 것.
스프링에서 왜 인터페이스를를 사용해야 할까? 어차피 구현체 하나밖에 없는데?
- 코드는 무조건 변경된다.
- 클라이언트가 추상화된 인터페이스를 바라보고 있으면, 구현은 매번 다르게 변경가능하다.
- 인터페이스 사용하면 테스트하기 쉽다.
- 부가적인 기능을 넣기가 쉽다.
- 인터페이스가 존재하면 앞뒤에 기능을추가하기(decorator)가 되게 쉬워짐.
인터페이스를 사용하는 코드는 재사용된다.
인터페이스 구현체 a, 그리고 새로운 구현체 b가 존재해도, 그 인터페이스를 사용하는 코드는 그대로 유지 가능하다. 이게 재사용. 라이브러리처럼 만들어놓고, 저수준의 로직이 아무리 추가되더라도 내가 만들어놓은 비즈니스 로직은 영향을 받지 않는다.
7. Abstraction
타입추상화
- 공통된 데이터나 프로세스를 제공하는 객체들을 하나의 타입(인터페이스)으로 추상화하는 것
- 데이터/프로세스 등을 의미가 비슷한 개념/표현으로 정의하는 과정
- 상세한 구현으로부터 개념을 도출하는 과정
- 예시
- 추상화
- 로그수집
- 구현
- 원격 서버 파일을 FTP로 다운로드
- 원격 서버 파일을 SCP로 복사
- DB 서버 로그 테이블을 조회
- 추상화
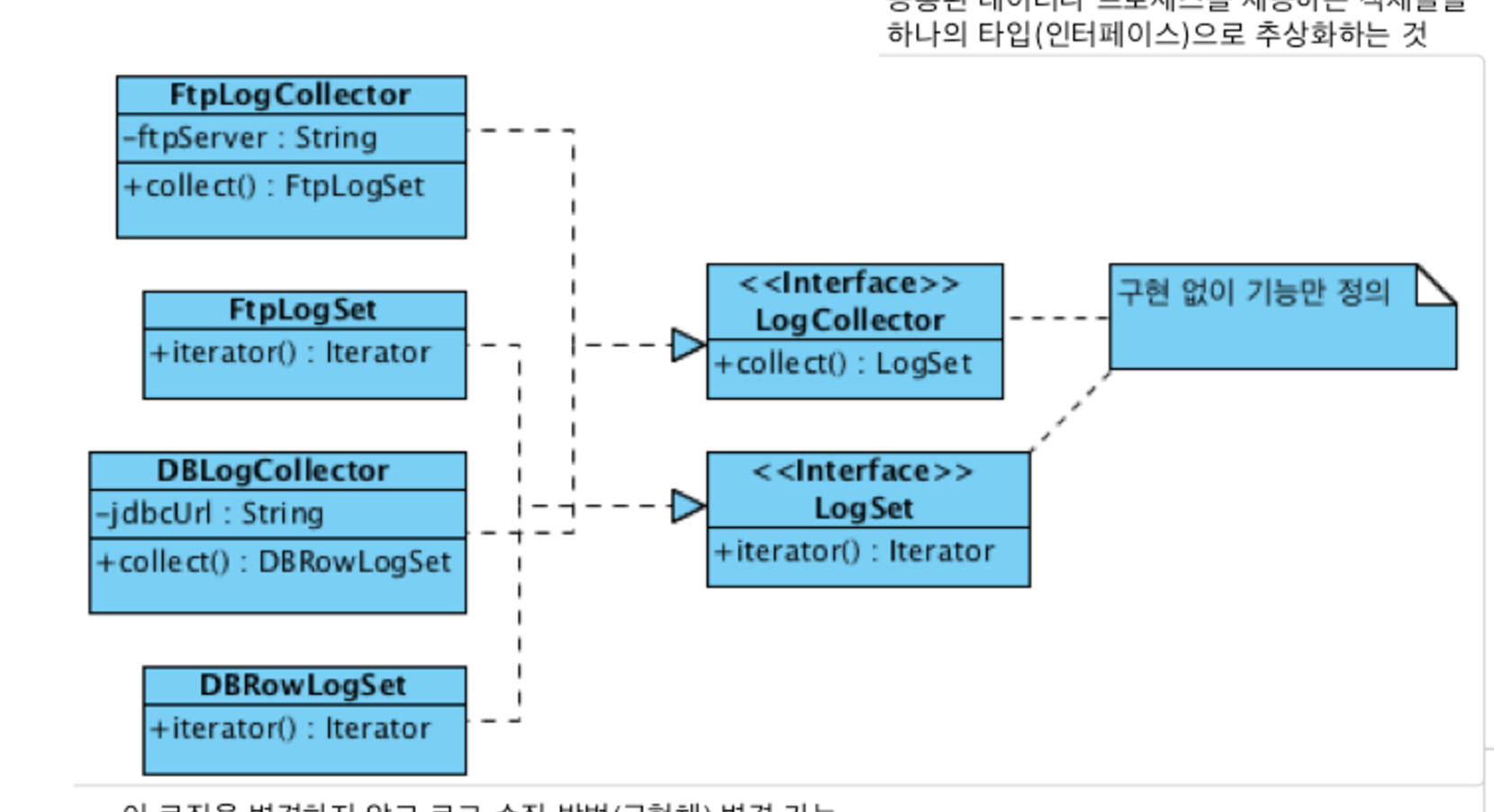
Ftp에서 가져오는 FtpLogCollector, DB에서 가져오는 DBLogCollector가 존재해야 한다. 처음부터 LogCollecotr라는 추상화 인터페이스를 생각해낼 수 있으면 좋고, 아니라면 ftp에서 db가 추가될 때 인터페이스를 추가할 수 있으면 된다.
이후 ftp나 db로그 콜렉터가 변경되더라도, 이 로그 컬렉터를 사용하는 인터페이스는 영향을 받지 않게된다. 이같은 재사용이 옳은 재사용. 상속을 받아서 부모의 코드를 재사용하는 것은 의존성이 강해졌다고 표현하는게 맞다.
클라이언트 코드의 재사용
LogCollector collector = createCollector();
LogSet logSet = collector.collect();
Iterator it = logSet.iterator();위의 로직을 변경하지 않고 로그 수집 방법(구현체)를 변경할 수 있다.
객체지향의 핵심은 의존성 관리를 통해 High Level Logic을 Low Level Detail로부터 보호하는 것.
Log Level Detail(로그 수집 방법)의 변경이 발생해도 High Level Logic(Collector collect 하고 iterate 하며 처리하는)는 보호된다.
Programming to Itnerface
인터페이스에다 대고 코딩을 해라, 구체적은 클래스를 보지말고 꼭 인터페이스를 보고 개발을 해라.
- Client Code가 항상 Inteface에 대한 레퍼런스를 사용해야 한다는 의미.
- Client는 구현 변경에 대해서 영향을 받지 않는다
- Interface Signature가 사용 가능한 모든 행위를 보여줌
- 추상화를 통해 유연함을 얻기 위한 규칙
- 사용 이유
- 런타임에 프로그램의 행위를 변경하기 위해
- 유지보수 측면에서 보다 나은 프로그램을 작성할 수 있게 함
추상화와 개발자의 습성
개발작 특성상 코딩을 하다보면 깊숙히 들어가서 쫙 구현하고, 이후에는 뭘 만들었는지 이해하기도 설명하기도 힘들어한다. 그런 경우 살짝 빗겨나서 하는 행위가 적절한지, 말이 되는지, 좋은지 점검해보면 좋다.
- 개발자들은 습성상 상세한 구현에 빠지다보면 상위 수준의 설계를 놓치기 쉬운데,
- 디렉토리에서 파일을 읽어와 메모리에 저장하고
- 한 줄 한 줄을 정규 표현식으로 파싱하고
- 그 결과를 DB에 일단 저장한 다음에
- ...
- 추상화를 통해서 상위 수준에서의 설계를 하는데 도움을 어등ㄹ 수 있다.
- 로그 수집
- 로그 분석
- 결과 저장
팩토리는 재사용 안되고 지저분해도 괜찮다.
하지만 비즈니스 로직은 깔끔하고 재사용 가능해야 한다.
스프링 사용의 강점: 스프링의 생각대로 개발을 하다보면 DI를 따르게 되어있다.
이는 내가 기능을 큰 클래스의 function으로 사용하는 것이 아닌, 역할이 다른 기능을 별도의 클래스로 빼고 인터페이스로 추상화한다음에 기능단위로 구현하고, 얘들을 실제로 j-unit에서 바로바로 테스트 해 볼 수 있다. 이 부분이 스프링의 가장 큰 강점.
8. Composition over Inheritance
상속을 통한 재사용 및 추가 기능을 통한 확장
- 서브클래스는 슈퍼 클래스의 기능을 재사용하면서 추가적인 기능을 제공
- 사용이 쉽다
- 유연한 변경 뒤 치명적 단점
- 슈퍼 클래스의 변경이 다수의 서브 클래스에 영향을 미침
- 유사한 기능의 확장에서 클래스의 개수가 불필요하게 증가할 수 있다
- 2개 이상의 슈퍼 클래스의 기능이 팔요한 경우 다중상속 불가
- 1개는 상속받고, 다른 한개는 따로 구현해야 한다.
- 상속 자체를 잘못 사용할 수 있다.
composition(delegation)
- 유연성 (변경 용이성) 증대
- polymorphism + composition으로 인해
- unit test(mock) 용이
- TDD에 용이
- Interface의 중요성
public class Calculator {
private PriceStrategy strategy;
public Calculator(PriceStrategy strategy) {
this.trategy = strategy;
}
public void calculate(...) {
this.strategy.apply(price);
}
}Reference
