시간복잡도와 Big-O
개발 공부를 하다 보면 좋은 코드라는 말을 자주 듣는다. 가독성이 좋은 코드, 유지보수가 좋은 코드 등 여러 기준이 있지만, 엔지니어링 관점에서 가장 핵심적인 기준은 바로 효율성이다.
내가 짠 코드에 데이터가 많아져도 끄떡없이 빠르게 돌아갈까? 아니면 데이터가 조금만 늘어도 멈춰버릴까? 이 질문에 대답하기 위해 우리는 시간복잡도 (Time Complexity)를 알아야한다. 오늘은 알고리즘의 기초이자 핵심인 시간 복잡도에 대해 쉽게 정리해보자!
1. 시간 복잡도란 무엇인가?
우리는 흔히 프로그램의 속도를 이야기할 때 "이 코드는 3초 걸려", "저 코드는 0.1초 걸려"라고 말하고 싶어한다. 하지만 초(Secod) 단위로 시간을 측정하는 것은 객관적인 기준이 될 수 없다.
왜냐하면 같은 코드라도:
- 슈퍼컴퓨터에서 돌리 때와 10년 된 노트북에서 돌릴 때 속도가 다르고,
- 컴퓨터가 현재 다른 작업을 얼마나 하고 있는지에 따라서도 달라지기 때문이다.
그래서 컴퓨터 과학에서는 절대적인 시간이 아니라, 입력값(N)이 커짐에 따라 연산 횟수가 얼마나 늘어나는가?를 기준으로 삼는다. 이것이 바로 시간 복잡도이다.
즉, 시간 복잡도는 알고리즘의 실행 시간이 입력 크기에 대해 어떻게 증가하는지 나타내는 지표라고 정의할 수 있다.
2. 알고리즘의 효율성 측정 기준 (Time vs Space)
알고리즘을 평가할 때는 크게 두 가지 자원을 본다.
- 시간 복잡도 (Time Compexity): 얼마나 빠르게 실행되는가? (CPU 사용량)
- 공간 복잡도 (Space Complexity): 얼마나 많은 메모리를 차지하는가? (RAM 사용량)
과거에는 메모리가 비싸서 공간 복잡도가 매우 중요했지만, 하드웨어가 발달한 요즘은 메모리보다는 빠른 실행속도 (시간 복잡도)를 우선시하는 경향이 크다. (물론, 불필요한 메모리 낭비는 피해야 한다.)
따라서 코딩 테스트나 실무 최적화에서도 주로 시간 복잡도를 줄이는 것이 핵심 목표가 된다.
3. Big-O (빅오) 표기법 이해하기
시간 복잡도를 표현하는 방법에는 크게 세 가지가 있다.
- (Big-Omega): 최상의 경우 (Best Case) - 운이 좋아서 1번 만에 찾았을 때
- (Big-Theta): 평균적인 경우 (Average Case)
- (Big-O): 최악의 경우 (Worst Case)
왜 Big-O를 사용할까?
개발자로서 우리는 항상 최악의 상황을 대비해야 한다. 운이 좋으면 1초만에 끝나라는 말보다는, "데이터가 아무리 꼬여 있어도, 적어도 이 시간 안에는 끝납니다"라는 보장이 훨씬 중요하기 때문이다. 그래서 우리는 시간 복잡도를 말할 때 주로 Big-O() 표기법을 사용한다.
Big-O 계산의 두 가지 핵심 규칙
Big-O는 정확한 연산 횟수보다는 증가 추세를 보는 것이 목적이므로, 복잡한 식을 단순화한다.
- 상수항은 무시한다.
- 입력 데이터가 개일 때 연산 횟수가 이라면?
- 그냥 으로 표기한다. 데이터가 무한대로 커지면 뒤에 붙은 이나 앞에 붙은 배는 의미가 없기 때문이다.
- 입력 데이터가 개일 때 연산 횟수가 이라면?
- 가장 높은 차수만 남긴다.
- 연산 횟수가 이라면?
- 이 커질수록 의 영향력이 압도적으로 커지므로, 작은 항인 을 버리고 으로 표기한다.
- 연산 횟수가 이라면?
4. 자주 보이는 시간 복잡도 종류와 예시
가장 빠른 것부터 느린 순서대로 살펴보자.
1) - 상수 시간 (Constant Time)
입력 크기에 상관없이, 언제나 즉시 끝난다.
- 상황: 책 펼치기
- 책의 두께()이 아무리 두꺼워져도 걸리는 시간이 변하지 않는다.
- 메커니즘:
- 데이터에 접근하는 '공식'을 이미 알고 있어서, 탐색할 필요 없이 단 한번의 연산으로 위치를 찾아낸다.
- 배열의 인덱스 접근(
arr[5])이나 해시맵의 키 조회(map.get("key"))가 대표적
- 특징
- 가장 빠르고 이상적인 시간 복잡도
- 이든 이든 속도가 똑같다.
public class Main {
// 정수형 배열을 입력받아 첫 번째 요소를 반환하는 메서드
public static int getFirstElement(int[] arr) {
return arr[0]; // 배열의 크기가 10이든 100만이든, 첫 번째만 확인하면 됨
\
}2) - 로그 시간 (Logarithmic Time)
데이터가 2배로 늘어나도, 연산 횟수는 딱 1회만 증가
- 이진 탐색 (반토막 내기)
- 수학적으로 이 숫자를 1이 될 때까지 반으로 몇 번 쪼갤 수 있니?를 묻는 것.
- 상황: 업다운 게임. 1~100 사이 숫자를 맞출 때, 절반씩 뚝뚝 잘라내면 금방 찾을 수 있다.
- 메커니즘: 데이터가 개 일 때, 한 번 단계가 지날 때마다 데이터가 로 줄어든다.
- 수학적으로 "2를 몇 번() 곱해야 이 되나?" ()에서 k를 구하는 수식이 바로
- 직관적 수치:
- 데이터가 1,000개일 때 10번만 쪼개면 1이 됨 ()
- 데이터가 100만 개일 때 20번만 쪼개면 됨
- 데이터가 40억 개일 때 32번만 쪼개면 됨
- 결론: N이 미친 듯이 늘어도 은 거의 안 늘어난다. 그래서 엄청나게 빠르다.
public static int binarySearch(int[] arr, int target) {
int low = 0;
int hgih = arr.length - 1;
while (low <= high) {
int mid = (low + high) / 2; // 중간값
if (arr[mid] == target) {
return mid; // 찾았다!
} else if (arr[mid] < target) {
low = mid + 1; // UP (왼쪽 절반은 이제 볼 필요 없음)
} else {
high = mid - 1; // DOWN (오른쪽 절반은 이제 볼 필요 없음)
}
}
return -1; // 못 찾음
}3) - 선형 시간 (Linear Time)
데이터가 늘어난 만큼, 정확히 그만큼 더 일해야 하는 정직한 노동
- 탐색 (성실한 노동자)
- 입력 데이터의 크기에 비례해서 처리 시간이 증가하는 알고리즘.
- 상황: 100쪽짜리 책에서 특정 문장을 찾아야 하는데, 목차가 없어서 1페이지부터 끝까지 다 넘겨봐야하는 경우
- 행동: 100번 넘김
- 메커니즘: 입력()이 2배 늘어나면, 내가 할 일(Step)도 정확히 2배 늘어난다.
- 대표 알고리즘:
for문 한 번 돌기- 최댓값/최솟값 찾기 (전체 스캔)
def print_all(arr):
for num in arr: # 데이터가 10개면 10번, 100개면 100번 반복
print(num)public static void printAll(int[] arr) {
for (int num : arr) { // 데이터가 10개면 10번, 100개면 100번 반복
System.out.println(num);
}
}4) - 선형 로그 시간
반으로 쪼개며() 전체를 정리()하는, 대량 데이터를 위한 마지노선
- 효율적인 정렬 (쪼개고() 다시 합치기())
- 병합 정렬(Merge Sort)의 과정을 통해 정렬이 왜 인지 이해할 수 있다. 병합정렬은 "반으로 쪼갯다가 다시 합치는 과정"이다.
- 예시 상황: 병합 정렬(Merge Sort)
- 이 복잡도는 가로 x 세로 면적과 같다.
- 세로 높이 (): 정렬을 하려면 일단 다 쪼개야 한다. 8개의 숫자를 1개가 될 때까지 반으로 계속 쪼갠다.
- 8개 > 4개 > 2개 > 1개 (총 3번의 층 (())
- 데이터가 개라면 높이는 층이 된다.
- 가로 높이 (): 쪼개진 걸 다시 합치면서(Merge) 정렬을 수행한다.
- 각 층(Layer)마다 흩어진 숫자들을 비교해 자리를 잡아야 한다.
- 각 층에 있는 숫자의 총개수는 여전히 개
- 즉, 한 층에서 일어나는 비교 작업의 합은
- 총 작업량 ()
- 작업량 = (각 층에서 하는 일) * (층의 개수)
- 작업량
- 결론:
- 세로 높이 (): 정렬을 하려면 일단 다 쪼개야 한다. 8개의 숫자를 1개가 될 때까지 반으로 계속 쪼갠다.
- 이 복잡도는 가로 x 세로 면적과 같다.
- 데이터가 많아질때 보다는 느리지만, 보다는 훨씬 빠르다.
- 코딩 테스트에서 N이 10만 ~ 100만 단위라면, 으로는 풀 수 없고 반드시 알고리즘을 써야한다.
5) - 이차 시간 (Quadratic Time)
모두가 모두와 악수를 해야 하는 상황.
- 상황 (악수회)
- 교실에 학생이 명 있다. 모든 학생이 서로 빠짐없이 한 번씩 악수를 하라고 시킨다.
- 첫 번째 학생이 나머지 명과 악수, 두 번째 학생도 나머지들과 악수 ...
- 학생이 2배로 늘어나면, 악수 횟수는 2배가 아니라 4배로 폭증한다.
- 메커니즘 (이중 루프의 함정)
- 반복문 안에 또 반복문이 있는 경우(Nested Loops)
- 번 반복하는 일을 번 또 해야하니 총 연산횟수는 이 된다.
- 직관적 수치 (재앙의 시작)
- 데이터가 10배 늘어나면 (10 -> 100), 시간은 100배 늘어난다.
- 데이터가 10,000개만 되어도 연산 횟수는 1억번()이 된다.
- 코딩 테스트에서 통상 1억 번 연산을 1초로 잡으므로, 이 넘어가면 시간 초과가 날 확률이 매우 높다.)
- 대표 알고리즘
- 버블 정렬(Bubble Sort), 선택 정렬(Selection Sort), 완전 탐색(Brute Force) 중 2개를 고르는 경우
def bubble_sort(arr):
for i in range(len(arr)): # N번 반복
for j in range(len(arr)): # 그 안에서 또 N번 반복
$ ... (총 N * N = n^2회 연산)public static void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length; i++) { // N번 반복
for (int j = 0; j < arr.length; j++) { // 그 안에서 또 N번 반복
// ... (총 N * N = N^2회 연산)
}
}
}6) - 지수 시간 (Exponential Time)
감당할 수 없는 폭발, 피해야 할 최악의 시나리오
- 상황 (아메바 증식 / 비밀번호 해킹)
- 아메바: 1마리가 1분 뒤 2마리, 2분 뒤 4마리, 3분 뒤 8마리... 로 분열한다.
- 비밀번호: 비밀번호가 한 자리 늘어날 때마다, 해커가 시도해야 할 경우의 수는 2배(혹은 그 이상)로 늘어난다
- 메커니즘:
- 데이터()가 하나 추가될 때마다 연산량이 2배씩 곱절로 늘어난다.
- 그래프가 하늘을 뚫고 올라간다.
- 직관적 수치 (기하급수적 증가):
- 번
- 만 번
- 억 번
- 조 번 (이미 슈퍼컴퓨터도 힘들어짐)
- 결론: 코딩테스트에서 N이 40을 넘어가는데 이 알고리즘을 썼다면 무조건 오답이다.
- 대표 알고리즘: 피보나치 수열(재귀 단순 구현), 모든 부분집합(Subset) 구하기.
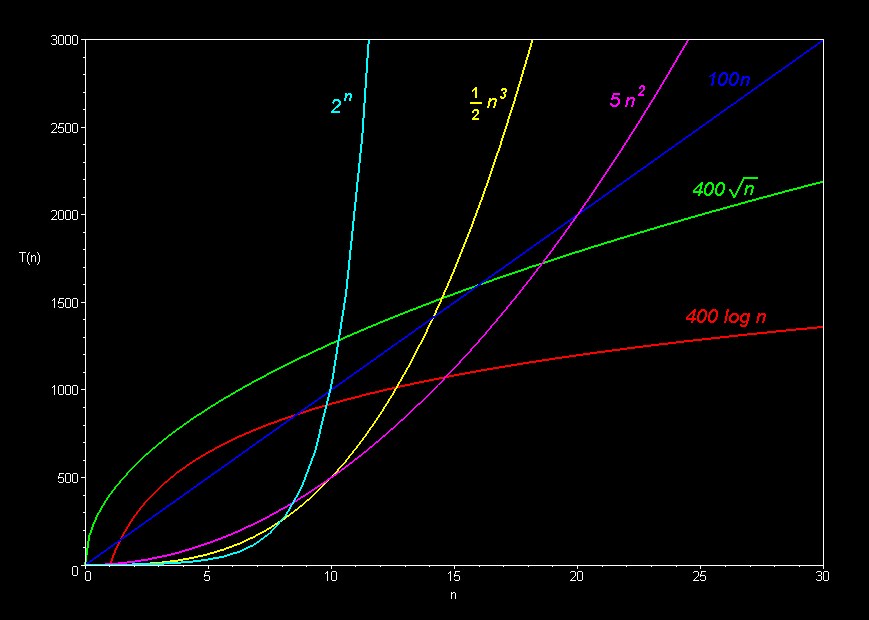
5. 시간 복잡도 그래프 비교
그래프로 보면 확연히 차이를 느낄 수 있다.
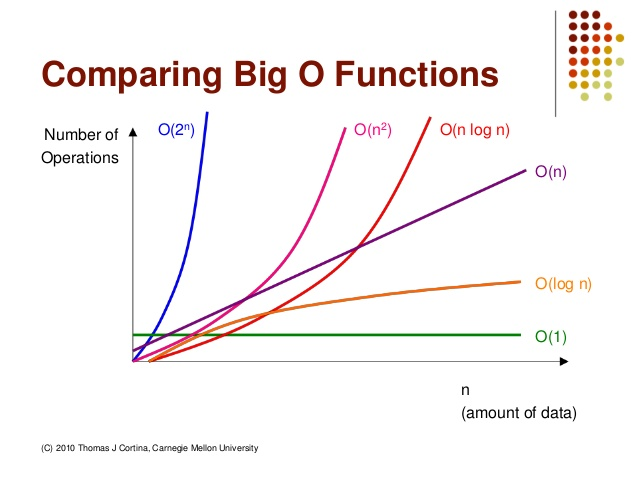
- 가로축(x): 입력 데이터의 크기 (Element)
- 세로축(y): 연산 횟수/ 소요시간 (operations)
그래프를 보면 과 은 바닥에 붙어서 기어가는 반면, 이나 은 하늘 높은 줄 모르고 치솟는 것을 볼 수 있다. 이것이 우리가 효율적인 알고리즘(가급적 그래프 아래쪽에 위치한 것)을 선택해야 하는 이유이다.
6. 결론
시간복잡도를 공부하는 이유는 단순히 이론적인 지식을 쌓기 위함이 아니다. 내 코드가 감당할 수 있는 데이터의 한계를 알기 위해서다.
시간 복잡도를 줄인다는 것은 문제 해결의 차원을 낮추는 행위이다.
- : 면적(2차원) 단위로 탐색하던 것을, 선(1차원)에 가깝게 최적화하는 것
- : 선형(Linear)으로 훑어야했던 문제를, 트리(Tree) 구조나 인덱싱을 통해 건너뛰며 접근하는 구조적 혁신
결국 시간 복잡도에 대한 이해는 단순히 코테 통과용 계산법이 아니라, "데이터를 다루는 구조를 어떻게 설계해야 비효율적인 연산을 제거할 수 있는가?"에 대한 구조적 사고력의 핵심이다. 즉, "내 코드가 감당할 수 있는 데이터의 한계"를 알기 위해서다.
앞으로 코드를 작성할 때 다음 두가지를 의식하는 습관을 들여보자.
- 이 코드는 N이 커지면 얼마나 느려질까? (반복문이 몇 번 중첩되었나?)
- 더 효율적인 자료구조(Map, Set 등)나 알고리즘(이진 탐색 등)으로 시간복잡도를 낮출 수 없을까?
Java 개발자 꿀팁
1. String 연결 연산(+)
- String에 + 연산을 루프 안에서 하면 매번 새로운 객체르 만들기 때문에 이 되어버린다.
- 해결: 무조건 StringBuilder를 써야 으로 끝난다.
2. Arrays.contains() vs HashSet.contains()
ArrayList에서 값을 찾으려면 처음부터 끝까지 뒤져야 해서 이다.HashSet은 해시 키로 바로 찾으므로 이다.- 인사이트: 중복 검사나 존재여부 확인이 빈번하다면 무조건
Set이나Map으로 데이터를 옮겨라.
3. 배열 정렬(Arrays.sort)
- N이 100만 개인데 정렬을 시도하면? 만 번 연산
- 1초 안에 충분히 들어온다. 100만개까지는 정렬해도 안전하다.
요약: 3초 룰
문제를 읽고 N을 본다.
- N이 작다(1,000 이하)?
- "아, 완전 탐색이나 DFS/BFS 돌려도 되겠네" (맘 편하게)
- N이 중간이다(10만)?
- "이중 FOR문 돌리면 망한다. 정렬하거나 스택/큐 써야지"
- N이 엄청 크다(10억)?
- "무조건 이진 탐색이네."
Reference
