학습 목표
- 흐름제어와 혼잡제어를 비교하여 설명할 수 있다.
- 흐름제어의 4가지 원칙을 설명할 수 있다.
- 혼합제어의 목적을 설명할 수 있다.
- 라우팅 방법(경로 배정)을 나열할 수 있다.
흐름제어, 혼잡제어, 라우팅의 개요
1. 내용, 정의 및 상호관계
정의
- 관련이 깊은 통신 기능
- 흐름제어(flow control)
- 혼잡제어[체증제어](congestion control)
- 경로선택(routing)
- 오류제어(error control; sliding window, stop-and-wait ARQ)
- 접근제어(access control)

- 많은 주체들이 서로 통신하면서, 오류없이 주어진 시간 내에 데이터 전송. 이를 위해 목록과 같은 통신 기능들이 요구된다.
- 목적
- 부 네트워크(subnetwork)의 내부환경에 관계없이 통신망의 성능을 유지
- => 성능 향상 및 혼합 방지
- 부 네트워크(subnetwork)의 내부환경에 관계없이 통신망의 성능을 유지
부 네트워크의 참조 모델
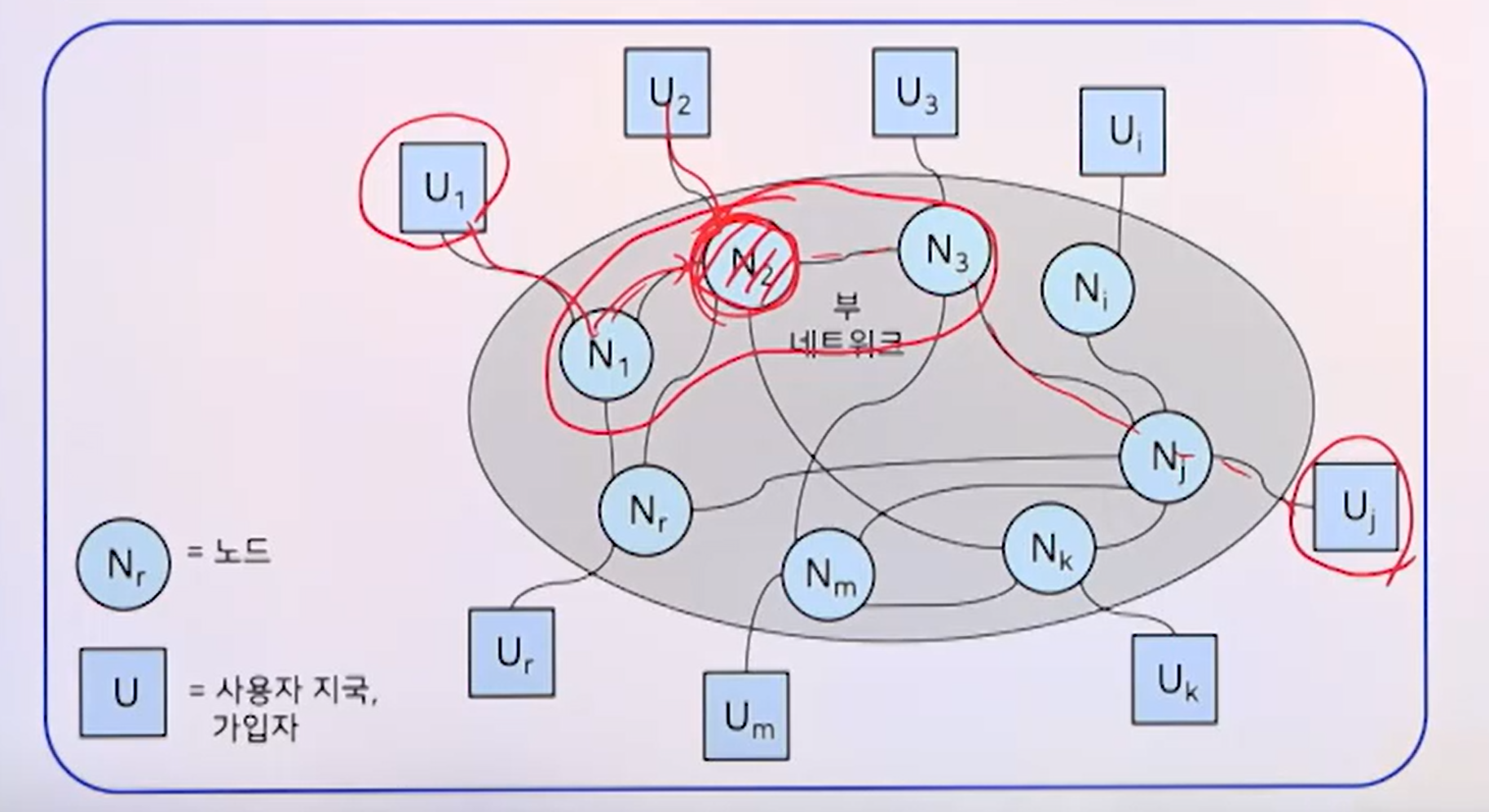
혼잡이라는 것은 어떻게 발생하는가? U1이 Uj로 데이터를 전송할 때, N2의 노드에서 U2에 의해 버퍼(잠깐 데이터를 저장하는 공간)에서 오버플로우가 발생하여 더 이상 데이터를 받지 못할 수 있다. 하나의 서브네트워크 안의 통신 노드안의 버퍼에 오버플로우가 발생하고, 이가 해당 노드 자체에 오버플로우(혼잡)이 발생하고, 그 국부적인 노드에서 혼잡이 번지면서 결과적으로 서브네트워크 전반에 혼잡이 번질 수 있다. 이번 장에서는 이와 같은 일을 예방하기 위해 어떤 통신 제어기능이 필요할까와 관련하여 혼잡제어 흐름제어 경로선택, 라우팅 등을 배우게 된다.
목적별 통신 기능의 구분
- 라우팅, 흐름제어 및 혼합제어의 구분
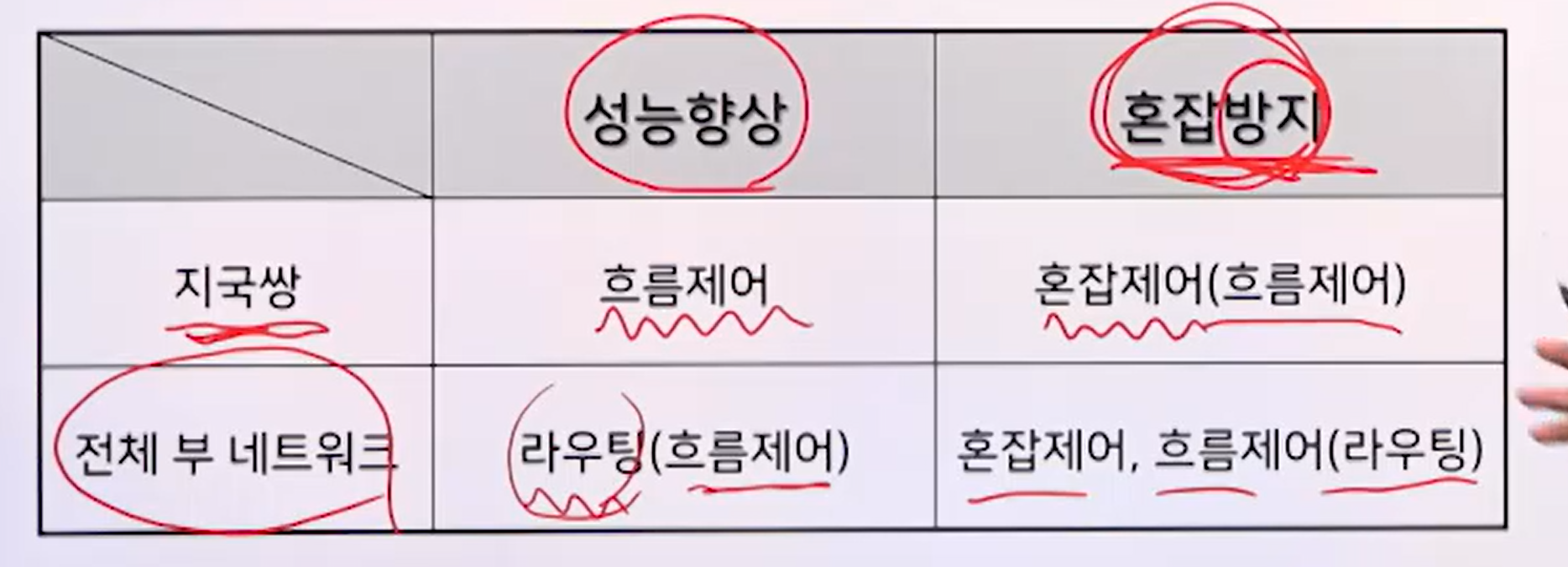
앞서 언급한 것 처럼 3가지(라우팅, 흐름제어, 혼잡제어)가 관련이 깊지만, 성능향상과 혼잡방지라는 2개의 목적에 비교해가며 살펴보면 위의 표와 같다.
열의 주체와 행의 목적에 맞추어 각 요소들은 칸과 같다. 어떤 문맥에서는 흐름제어, 혼합제어, 라우팅 등이 더 적절하다. 전체적으로는 지국간의 혹은 서브네트워크 안의 성능을 유지시키거나 혼합을 방지하는 목적으로 기능들이 사용된다.
- 지국쌍: a와 b
- 전체 부 네트워크: 구름

흐름제어
1. 흐름제어 정의 및 목적
- 흐름제어 (flow control)
- 송신 블록 수, 수신 블록 수, 통신 매체의 조절
- 흐름제어의 목적
- 통신망 성능 최적화
- 혼잡 방지
2. 흐름제어의 네 가지 원칙
(1) 속도 조절
- 블록 간의 도착 간격 변경
- 예: 감속 방법 (choke packet 이용)
속도를 더 빨리 보내는 경우는 없고, 대부분의 경우에 지금 너무 혼잡하니 더 느리게 보내달라는 시그널로 사용됨
(2) 거부 (reject)
- 송신측에 대한 거부 상태 통지
- 제일 심플하게 수신측에서 너무 버거우니 받은 정보를 버려버리는 것. 수신측에서는 아무런 답변이 없으니 저쪽에서 못받았다고 판단, 다시 보내게 됨.
- 예
- 무시 방법 (송신측에 대한 거부)
- stop-and-go 방법 (송신 이전의 수신 거부)
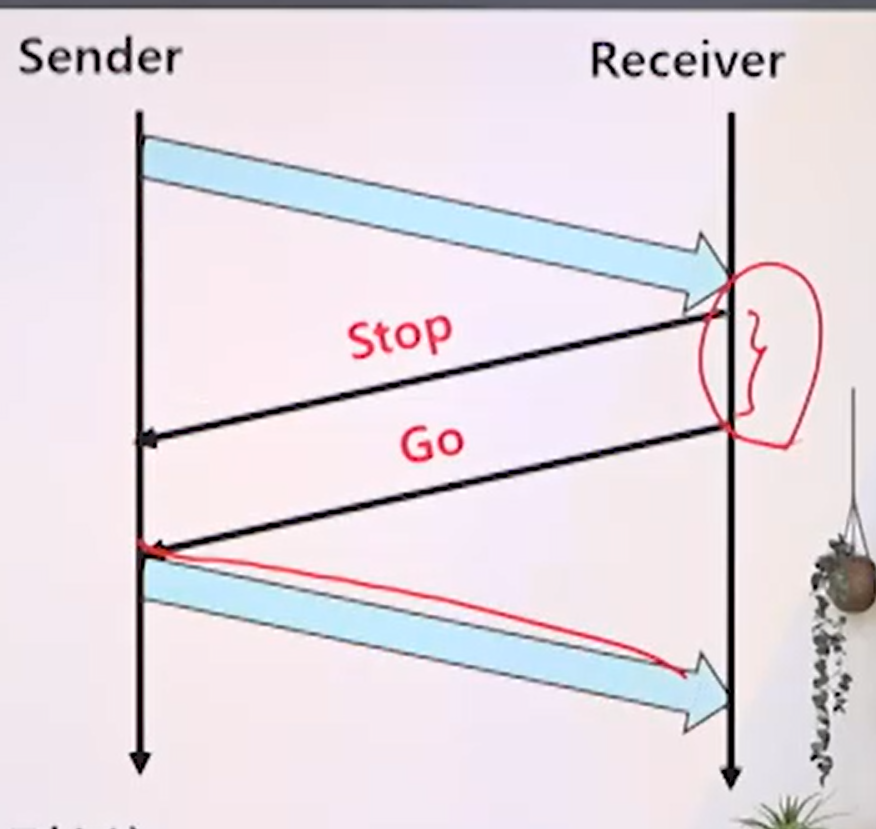
- receiver측에서 버거우면 Stop 신호를 보내서 재정립의 시간을 거치고, 다시 데이터를 받을 준비가 되었을 때 Go 시그널을 보내는 것.
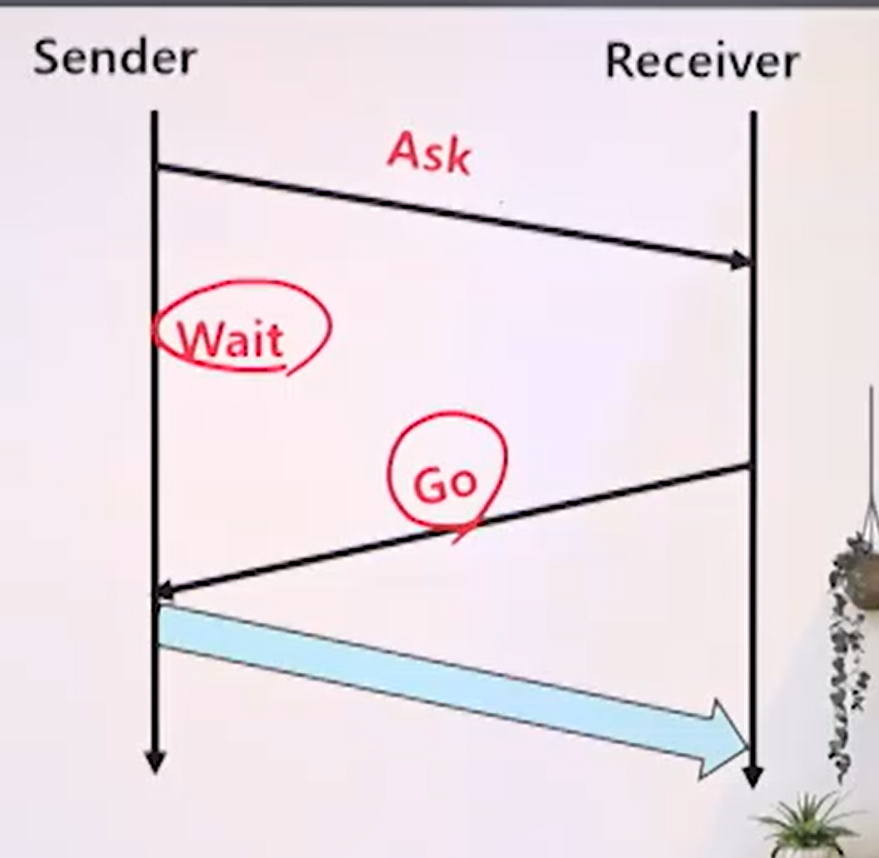
(3) 단일 승낙 (single permission)
- 매번 송신 허락을 받아야 함
- 보낼까? 어..조금기다려 보낼까? 어..조금기다려 보낼까? 어,지금보내
- 한번씩, 매번 송신을 할 때 마다 단일 허락을 구하는 방법
- 예:
- wait-before-go 방법
- ask-and-wait 방법
(4) 다중 승낙 (multiper permission)
- 정해진 개수의 블록만 송신 가능
- 미리 정해진 갯수의 데이터만 송신하고, 허락이 떨어질때까지 기다리는 것. 허락이 오면, 그만큼 움직여서 전송
- 예:
- sliding window 방법
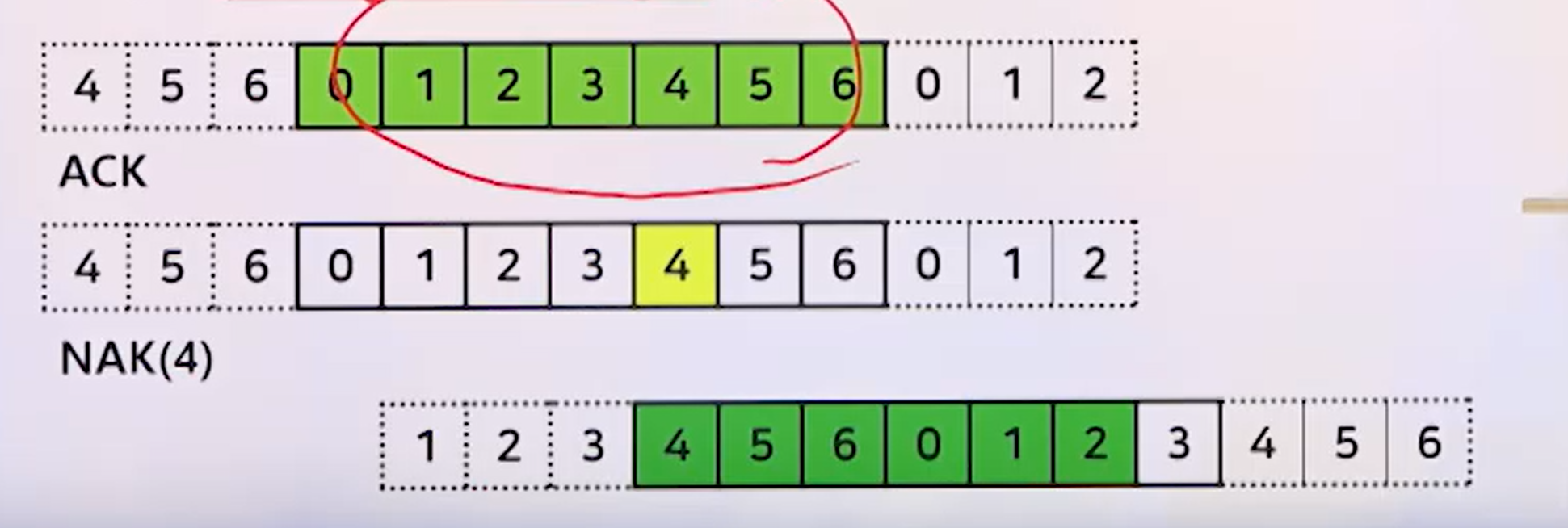
- 4번 부터 보내달라고 신호가 오면, 0번에서 기다리다가 4번까지 다시 땡겨서(window를 움직여서) 일정 데이터 재전송. 다중으로 보낸다는 의미에서 다중 승낙인듯?
- sliding window 방법
혼잡제어
1. 정의
- 혼잡(congestion) 현상
- 전송 데이터의 급격한 증가로 인하여 통신망에서 과부하가 발생하고 데이터 전송속도가 급감하거나 전송불가 상태가 되는 경우
- 단계적 발생 (과입력 전송지역 ==> 전체 부네트워크)
- 좁은 범위의 전송지역부터 단계적으로 전체로 까지 혼잡이 커지는 것.
- 버퍼 혼잡: 여러 버퍼들의 오버플로우
- 노드 혼잡: 한 노드
- 국부 혼잡: 특정 노드들
- 전체 혼잡: 전체 부네트워크
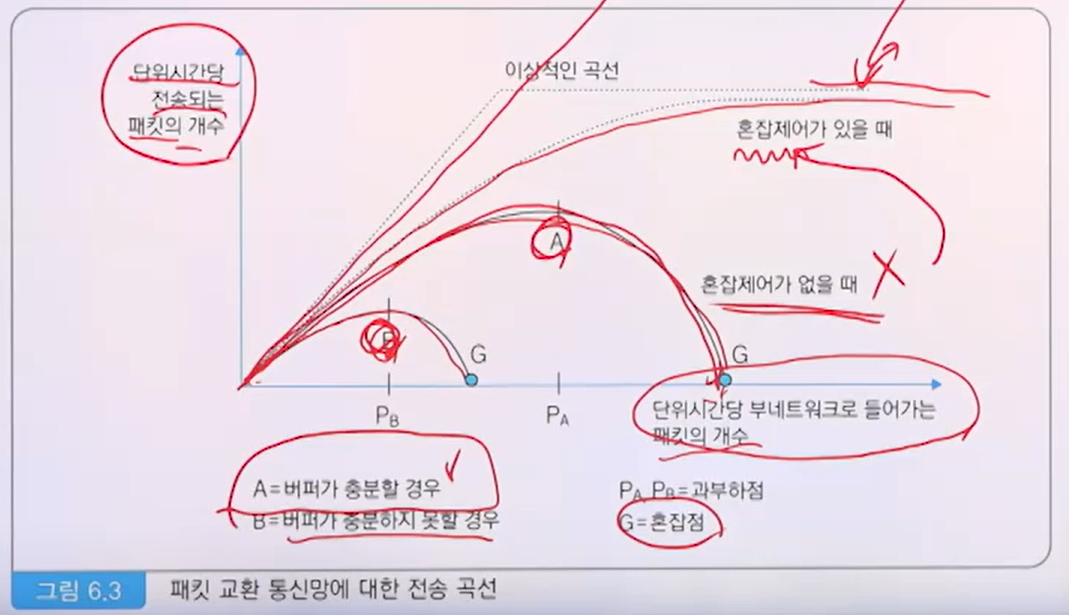
- 이상적으로는, 네트워크에 들어가는 데이터 양이 늘어날수록, 전송되는 패킷의 숫자도 직선으로 늘어나는게 맞다.
- 그러나 현실적으로는, QoS(Quality of Service)의 기준점을 맞춰 버퍼에 넣었다가 보내는 행위를 반복하면서, 서비스 수준에 맞추어 스트레스 홀드값 까지는 유지하도록 하는 것이 좋다.
- 혼잡제어 기능이 있어야 이것이 가능하다.
- A: 혼잡제어 기능이 없고, 버퍼가 충분할 경우, 일정 데이터를 전송하다 최종적으로는 단위시간당 패킷의 갯수가 0으로 수렴하며 통신이 마비된다.
- B: 혼합제어 기능이 없고, 버퍼 조차 부족한 경우, A보다 빠르게 혼잡지점에 도달해 데이터를 전송하지 못하게 된다.
결론: 이런 일이 생기지 않도록 혼잡제어를 잘 설정해두자.
2. 방법
- 전송량의 제한 (처음부터 들어오는 데이터의 양을 조절)
- 허가증(permit)을 이용하여 전송량을 일정 수준이하로 유지
- 예: Isarithmic 흐름제어 방법
- 부네트워크 내의 부하 감소
- 어떤 패킷을 버림
- 흐름제어(거부원칙) 방법 이용
- 국부적 전송량의 재분배 (몰리는 데이터가 다른 곳을 통해서 가도록 경로변경)
- 국부적인 체증 방지 및 국부적 과다 교통량 해소
- 경로선택 방법 이용 (라우팅)
라우팅
- a에서 b로 갈때, 노드 간의 경로 선택. 거리 자체보다 경우에 따라 돌아가는 것이 혼합제어, 흐름제어에 더 유리할 수 있다.
1. 개요
정의
데이터 블록이 목적 노드로 전달되도록 출발 노드에서 목적 노드까지의 경로를 결정하는 기능
목적
- 네트워크 성능 최적화
- 임계값(경계조건)의 유지
- 평균패킷전송시간의 최소화
- 네트워크 자원 활용도의 최대화 (비어있는 노드를 우선선택)
- 네트워크 전부 또는 일부의 혼합 방지
- 네트워크의 전송 신뢰도 증대
라우팅 테이블 구조
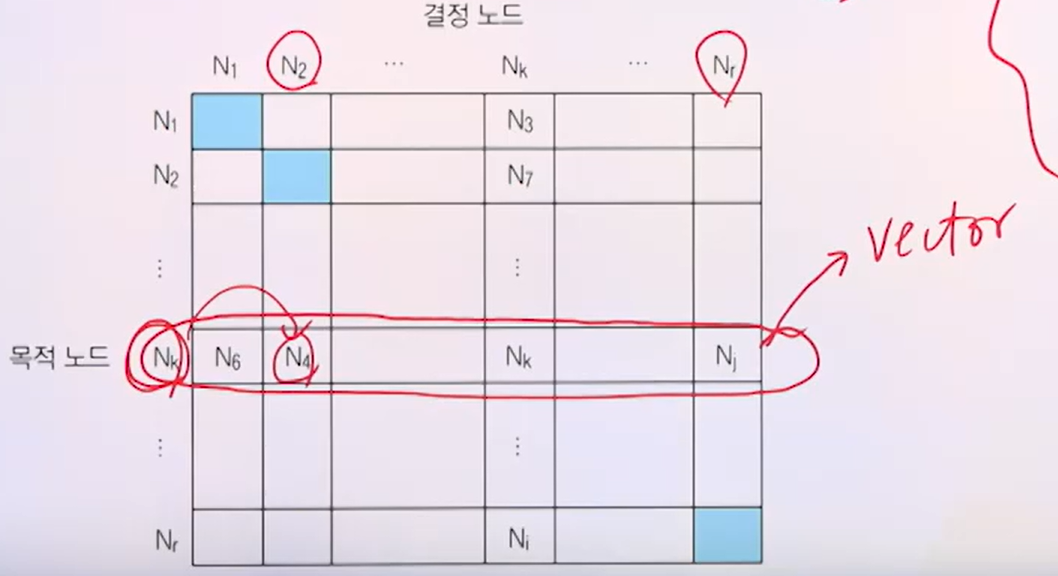
- 이 라우팅 테이블을 누가 유지하냐에 따라 라우팅 방법이 분류된다. 예시 에서는 Nk에서 N2로 보내려면 N4를 지나야한다. 한 행이 routing vector가 되어 다음번에 어디에 보내야 Nr에 데이터를 보내는 것이 가능한지 구할 수 있다.
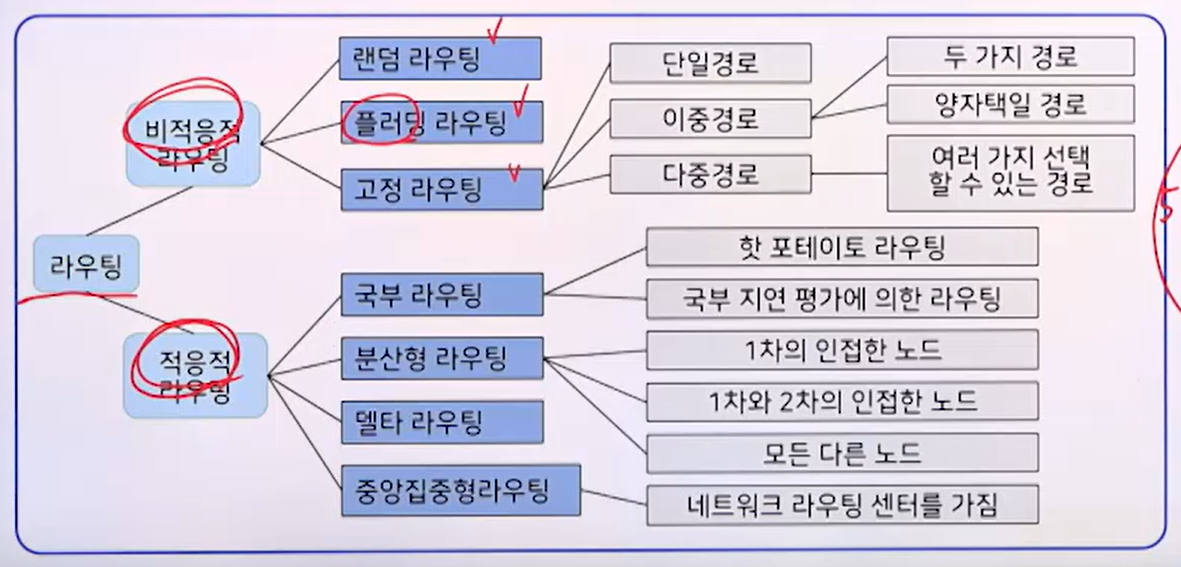
라우팅 방법의 분류
- 이산수학의 인접행렬이 Graph를 표현하는 용도로 사용된다. 연결선이 있으면 1, 없으면 0으로 표현되며 특정 노드간의 이동 횟수를 인접행렬을 통해 구할 수 있다.
- 이와 같은 이산수학의 행렬이 라우팅 테이블과 유사하다고 생각하면 된다.
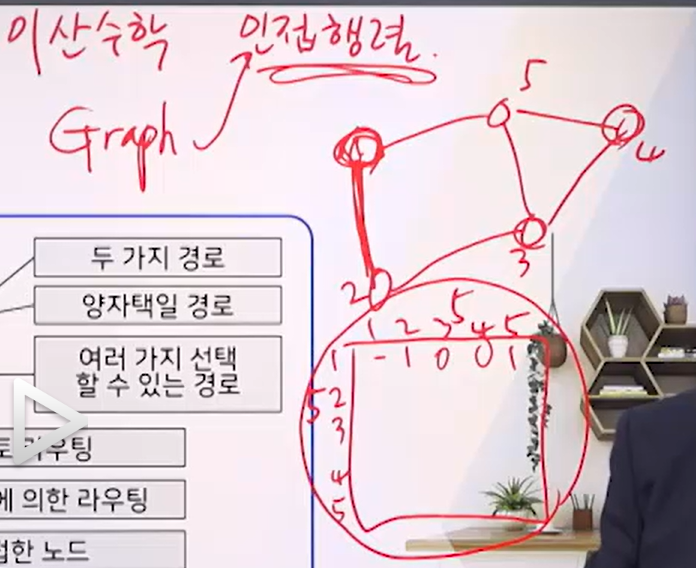
3. 방법
비적응적 라우팅
비적응적 라우팅: 정적으로 결정된 것을 따르는 경우
- 랜덤 라우팅 (random routing)
- 다음 노드를 임의로 결정함
- 모든 경로는 동일한 확률로 선택 가능
- 루프(loop)는 허용되지 않음
- 플로딩 경로선택 (flooding routing)
- 블록이 들어온 노드만 제외한 모든 노드에 전송
- 매우 큰 트래픽 형성 가능
- 빠르게 혼잡해질 가능성이 높음
- 고정 경로선택 (fixed routing)
- 다음 노드가 일단 정해지면 환경이 변해도 유지
- 대표적 비적응적 경로선택
- 고정 단일 경로선택
- 다음 노드가 오직 하나 고정된 경우
- 범람 경로선택(flooding routing)과 정반대
- 모두 전송하는 flooding 방식과달리, 하나만 보내고 다른건 전혀 보내지 않는다는 점에서 정반대. 다만 이 하나의 경로가 모든 트래픽을 감당할 수 있으면 문제가 되지 않지만, 감당하지 못하면 그럼에도 불구하고 fixed되어 하나의 경로로만 전송해야 해 문제가 생김.
- 노드나 선로 고장의 경우 경로가 완전 차단
- 고정 이중[다중] 경로선택
- ==> by-pass link 첨가
적응적 라우팅
적응적 라우팅: 라우팅 테이블 수정 가능. 라우팅 테이블, 라우팅 벡터를 공유하는지 혼자 사용하는지에 따라 구분이 된다.
- 국부 경로 선택 (local routing)
- 라우팅 정보를 한 노드에서만 활용
- 다음 노드의 결정은 해당 노드에서 수행
- hot potato 경로선택 (=shortest queue routing method)
- 가장 짧은 큐를 가진 출력 선로를 선택하여 데이터 전송
- 국부지연평가(local delay estimate)에 의한 경로 선택
- 과거의 정보를 이용하는 방식
- 데이터를 반대 방향으로 전송하는데 걸리는 시간을 계산하여 다음 노드를 결정 (backword routing)
- hot potato 경로선택 (=shortest queue routing method)
- 분산형 경로선택 (distributed routing)
- 라우팅 정보를 인접 노드에서만 교환
- 라우팅 정보를 인접 노드끼리 분산해서 공유. 공유하는 노드의 갯수에 따라 종류가 구별
- 각 노드에서는 제한된 크기의 전송지연표를 이용하여, 목적 노드까지의 최소 지연의 다음 노드를 결정
- 최소 지연 벡터는 주기적으로 갱신되며 인접 노드끼리 공유
- 종류:
- 1차 인접 노드
- 1차, 2차 인접 노드
- 모든 다른 노드
- 라우팅 정보를 인접 노드에서만 교환
- 중앙집중형 경로선택 (centralized routing)
- Network Routing Center(NRC)
- 중앙집중형으로, 중앙에서 라우팅정보를 모두 수립하고, 다음 노드 선택을 지휘
- 모든 노드는 경로선택에 관련 정보를 NRC에 제공
- NRC는 라우팅 벡터를 갱신하여 각 노드에게 제공
- 분산형 경로선택과 정반대
- 각 노드는 편리하나, NRC는 복잡함
- Network Routing Center(NRC)
- 델타 경로선택 (delta routing)
- 분산형(2) 경로선택과 중앙집중형(3) 경로선택의 결합
- 인접 노드사이의 경로 선택 -> 분산형 경로선택
- 통신망 전체의 경로 선택 -> 중앙집중형 경로 선택
- 인접한 노드끼리는 자기들끼리 정보를 공유해서 혼합도 지식을 공유, 그러나 인접하지 않은 노드까지는 알 수 없으므로 다른 노드집합은 중앙집중형으로 관리
- 분산형(2) 경로선택과 중앙집중형(3) 경로선택의 결합
Reference
- 한국방송통신대학: 정보통신망 - 손진곤
