01. 회복 시스템의 개념
회복의 역할
회복의 역할
- 예상치 못한 HS 고장 및 SW 오류가 발생
- 사용자의 작업에 대한 안정적 디스크 반영 여부 보장이 불가능
- 오류 발생 이전의 일관된 상태로 데이터베이스를 복원시키는 기법이 요구
- 시스템 내의 고장 원인 검출, DBMS의 안전성 및 신뢰성을 보장
- 데이터베이스는 데이터 복원 절차 내재화
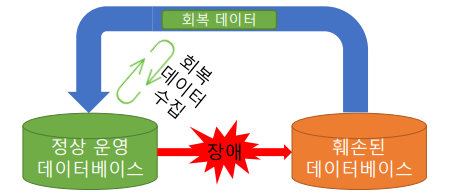
정상 운영 DBMS의 장애로 데이터의 일부가 훼손된 DBMS가 될 수 있음. 이 DBMS를 훼손 전으로 되돌리는 것 = 회복 시스템. 일정 부분 훼손되면 어느 부분의 데이터가 훼손되었는지 알 수 없어 모든 데이터를 신뢰할 수 없게 됨. 따라서 훼손된 데이터를 다시 되돌리기 위해 회복 데이터를 준비해둔다. 정상적으로 운영되고 있을때 때때로 회복 데이터를 마련해두고 문제 상황에 사용한다. 이처럼 DBMS는 회복 기능을 내제화하고 있는데, 어떤 방식으로 회복하는지 이번 강의에서 알아보자.
시스템 실패(system failure)의 유형
어떤 상황에 데이터베이스의 훼손이 발생할까?
- 트랜잭션 실패
- 논리적: 잘못된 데이터 입력, 부재, 버퍼 오버플로(메모리의 초과), 자원 초과 이용
- 시스템적: 운용 시스템의 교착 상태
- 시스템 장애
- 시스템의 하드웨어 고장, 소프트웨어의 오류
- 주기억장치와 같은 휘발성 저장장치의 내용 손실
- 디스크 실패
- 비휘발성 디스크 저장장치의 손상 및 고장으로 인한 데이터 손실
회복 데이터의 구성
정상 운영 데이터베이스. 하드디스크 내부에 파일의 형태로 데이터 저장. 일반적으로 바이너리 데이터를 가지고 있다. 1. 이 파일자체를 복사해서 다른 디스크에 복사해두는 것.(=백업) 2.트랜잭션 발생 시 마다 바뀐 수정사항을 장부처럼 기록해둔다.(=로그)
- 백업(backup): 데이터베이스의 일부 또는 전체를 주기적으로 복제하는 방식
- 로그(log): 데이터 변경 이전과 이후의 값을 별도의 파일에 기록하는 방식 (보안, 유출 등에도 활용된다.)
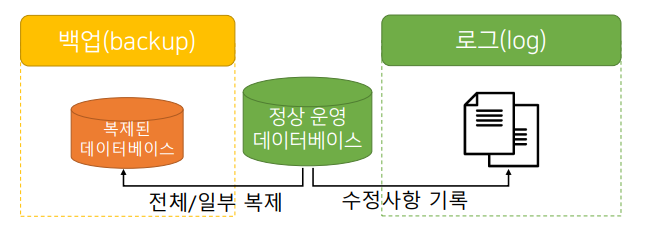
데이터 저장 구조
회복을 위해서는 장애 발생시 복구 데이터를 어디까지 확보하느냐를 정확히 판단해야 한다. 데이터가 어떤식으로 저장 절차를 거치는지. 어떤 과정에서 어떤 저장장치가 사용되는지 명확히 알 필요가 있다.
- 데이터는 디스크와 같은 비휘발성 저장장치에 저장되며, 전체 데이터의 일부만 주기억장치(휘발성)에 상주
- 데이터베이스는 데이터를 블럭(block) 단위로 전송하고 블럭 단위로 기억장소를 분할
- 트랜잭션은 디스크로부터 주기억장치로 데이터를 가져오며, 변경된 데이터는 다시 디스크에 반영
- 가져오기, 내보내기 연산은 블럭 단위로 실행
- 물리적 블록: 디스크 상의 블럭
- 버퍼 블록: 주기억장치에 임시적으로 상주하는 블럭
데이터베이스 연산
- 메인메모리와 디스크 사이의 연산
- Input(X): 물리적 블록 X를 메인 메모리에 적재
- Output(X): 버퍼 블록 X를 디스크에 저장
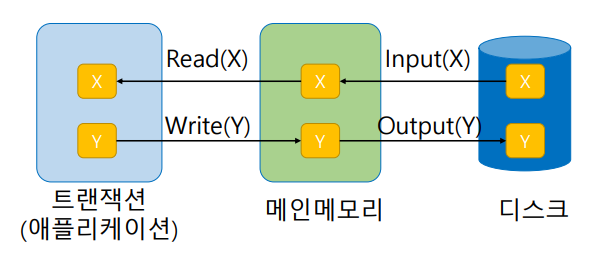
디스크 -(자료요청)-> 메인메모리(데이터 상주 = 버퍼블럭) -> 트랜잭션(메인메모리 내부에 각가의 트랜잭션이 자기가 사용하는 데이터를 보관하기 위한 공간이 구분되어 있음.)
우리가 이야기하는 "Read 연산"은 정확히는 메인메모리에 있는 데이터블럭이 트랜잭션이 사용하는 고유 영역으로 읽히는 것. "Write 연산"은 정확히는 트랜잭션이 사용하는 공간에서 메인메모리가 사용하는 공간으로 데이터가 기록되는 것.
디스크로 데이터를 가져오고 쓰는 것은 Input, Output연산을 통해 이루어진다.
만약 트랜잭션이 x데이터 요청하면 Read(X) -> 메인메모리가 자기안에 x가 있는지 찾아보고 있으면 알려줌. 만약 없으면 Input(X)함수를 요청해서 X의 물리적 블록을 올려놓고 Read(X)시행.
02. 로그 기반 회복
로그 기반 회복의 개념
- 데이터베이스가 수행한 모든 수정 작업을 기록한 여러 종류의 로그를 사용하여 회복하는 시스템
- 로그 레코드 (크게 4가지로 구분)
- < 𝑇𝑖, 𝑋𝑗, 𝑉1, 𝑉2 >: 데이터 변경시 사용하는 레코드. Ti가 데이터항목 변경 연산을 수행하여 Xj(트랜잭션 내부의 특정 데이터 항목)의 값을 V1에서 V2로 변경
- < 𝑇𝑖, 𝑠𝑡𝑎𝑟𝑡 >: Ti가 시작
- < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 >: Ti가 커밋
- < 𝑇𝑖, 𝑎𝑏𝑜𝑟𝑡 >: Ti가 취소
데이터 항목 변경 과정
- WAL(Write-Ahead Log) 쓰기에 앞서 로그하라
- 트랜잭션은 데이터베이스 수정 전, 로그 레코드를 생성하여 기록
(10만원 있는 계좌에 5만원을 입금하여 15만원이 되야함. 그런데 사고로 DBMS가 누락되어 5만원 입금에 관한 기록이 남지 않음. 회복을 시켜야 하는데, 작업을 하고나서 로그를 기록하는 경우, 데이터 원복을 위한 데이터가 남지 않는다. 따라서 로그를 "먼저" 기록한다. 15만원 입금됨을 로그에 기록하고 나서 10만원에서 15만원으로 금액을 올린다.)
- 데이터 항목 변경 과정
- 트랜잭션이 메인 메모리의 개인 영역에서 여러 연산을 수행
- 트랜잭션이 데이터 항목이 존재하는 메인 메모리에 위치한 버퍼 블럭의 데이터를 변경
- Output명령을 실행하여 버퍼 블럭을 디스크에 기록
최종적으로, 1. 로그 기록 -> 2. 트랜잭션 고유 영역의 데이터 수정 -> 3. 버퍼 블럭에 반영 -> 4. Output 명령으로 디스크에 기록 (4단계를 거침). 4단계중 어느 단계에서 복원하느냐에 따라 복원 방법이 달라진다!
Redo와 Undo 연산
회복 방법 자체도 2개로 나뉨. 다시하거나redu, 되돌리거나undo
- 회복 기법은 로그에 대해 두 연산을 사용

- 시스템 장애 발생시
- 로그에 < 𝑇𝑖, 𝑠𝑡𝑎𝑟𝑡 > 가 있지만 < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 > 또는
< 𝑇𝑖, 𝑎𝑏𝑜𝑟𝑡 > 를 포함하지 않는 경우 𝑇𝑖는 Undo
프로그램 실행 도중에 DBMS가 망가진것. 사용자도 정상처리 통보를 받은적이 없음. 따라서 시작 전 상태로 되돌려야 한다.= Undo
- 로그에 < 𝑇𝑖, 𝑠𝑡𝑎𝑟𝑡 > 가 있지만 < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 > 또는
< 𝑇𝑖, 𝑎𝑏𝑜𝑟𝑡 >를 포함하는 경우 𝑇𝑖는 Redo
로그가 기록되었는데, 메모리에만 일어났고 디스크에 반영이 안 되었기 때문에 디스크 반영 과정에서 오류가 발생한 것. 사용자에게는 작업이 정상 완료되었다고 결과가 전달되었기 때문에, 로그를 사용해 다시 DBMS에 반영시켜야 한다! = Redo
데이터베이스 변경과 커밋
-
데이터베이스 변경 시 복구 알고리즘의 고려 사항
- 트랜잭션의 일부 변경 사항이 버퍼 블록에만 반영되고 물리 블록에 기록되지 않은 상태에서 트랜잭션이 커밋되는 상황
(메모리: 반영O, 디스크: 반영X) - 트랜잭션이 동작 상태에서 데이터베이스를 수정했으나 수정 후에 발생한 실패로 취소가 필요한 상황.
(메모리: 반영O, 디스크: 반영O)
- 트랜잭션의 일부 변경 사항이 버퍼 블록에만 반영되고 물리 블록에 기록되지 않은 상태에서 트랜잭션이 커밋되는 상황
-
트랜잭션 커밋 상황
트랜잭션의 커밋은 무엇을 의미할까? 뭘 기분으로 판단해야 할까? 로그 레코드로 판단한다. (<Ti, commit>)- < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 > 로그 레코드가 안정된 저장장치에 기록 완료 시 트랜잭션 커밋으로 간주
(디스크 기록 반영여부를 떠나서, 로그레코드만 있으면 커밋으로 간주) - < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 > 로그 레코드가 기록되기 전에 장애가 발생하면 롤백
(디스크에 데이터가 반영되었음에도 불구하고 커밋 레코드가 없다. = 커밋되지 않은 것으로 본다.)
- < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 > 로그 레코드가 안정된 저장장치에 기록 완료 시 트랜잭션 커밋으로 간주
디스크의 변경 여부로 따지지 않고, 커밋 레코드를 기준으로 따진다!
회복의 유형
- 회복은 트랜잭션에 의해 요청된 갱신 작업이 디스크에 반영되는 시점에 따라 구분
- 지연 갱신 회복(deferred update restore)
- 부분 커밋까지 디스크 반영을 지연시키고 로그에만 기록
- 실패 시, 별도의 작업 필요 없이 로그만 수정.
모든 작업은 메모리에 하고, 주기적으로 디비에 반영하는 DBMS. 디스크의 접근을 최소화하여 DBMS 전체 성능 향상. 이런 경우 디스크에 반영된것이 없으므로 회복작업 없이, 수정 로그 레코드만 반영하지 않으면 된다.
- 즉시 갱신회복(immediate update restore)
- 갱신 요청을 곧바로 디스크에 반영
- 실패 시, 디스크에 반영된 갱신 내용을 로그를 바탕으로 회복
데이터 갱신할 때 마다 버퍼블럭을 곧바로 디스크에 output. 성능은 떨어지나 데이터의 안정성이 높아짐. 디스크에 모든 작업이 갱신되므로 반드시 로그레코드를 일일이 따져 이전 상태로 회복시켜야 한다.
은행 시스템의 트랜잭션의 예
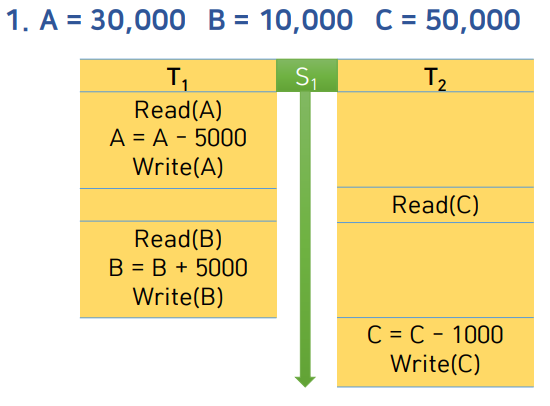
두 개의 트랜잭션이 실행되면서 s1이라는 스케줄이 만들어짐.
로그와 데이터베이스 상태
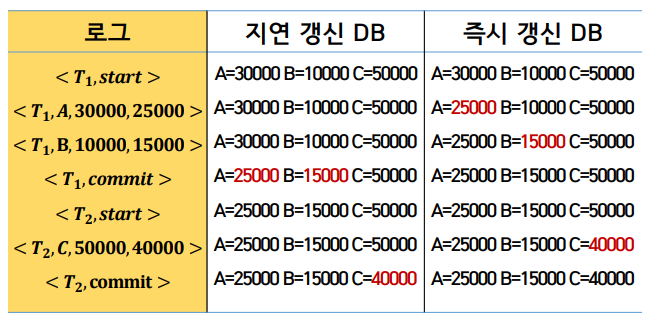
스케줄을 토대로 로그가 만들어짐. 지연 갱신 DB의 경우 commit되고 나서야 값이 디스크에 반영된다. 즉시 갱신 DB는 수정 로그가 있을때마다 디스크에 바로 값이 반영된다. 디스크에 값 저장 시점이 다르다.
시스템 장애 발생 상황
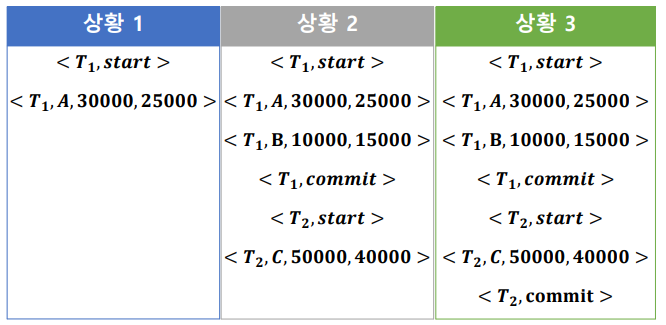
상황1: T1작업 중 commit되지 않고 에러.
- 지연갱신DB: 디스크에 반영된 값이 없음. 해당 로그 레코드만 삭제하면 됨.
- 즉시갱신DB: 디스크에 값이 반영되었을 가능성이 있음. A의 값이 3만이면 내버려두고, 2만5천이면 다시 3만으로 되돌려야 한다.
상황2: T2작업 중 commit되지 않고 에러.
- 지연갱신DB: T2는 로그만 지우면 됨. T1는 반응이 되었을 것임. A,B 값은 복원시켜야 함.
- 즉시갱신DB: A,B,C 모두 반영됐을 가능성이 있음. T1, T2모두 원복
상황3: T1, T2모두 commit된 상태에서 에러.
- 지연갱신DB: A,B,C 모두 디스크에 반영됐을 것. 모두 복원
- 즉시갱신DB: 이하동문
체크포인트의 필요
체크포인트: 중간정산. 주기적으로 방점을 찍는 것. "여기까진 우리가 완료했어!"
디비가 아주 오랜시간 데이터를 관리해왔을것. 현재 오류가 발생했다면, DBMS시작 시점부터 이어진 모든 기록들을 다시 검토할 필요 없이, 안정적으로 디스크에 정상 처리된 트랜잭션은 제외하고 실행 도중에 있던 로그레코드만 검토해보면 된다!
- 로그 기반 회복 시스템의 한계
- 로그의 크기는 시간이 지남에 따라 계속 증가하므로 대용량 로그의 탐색 비용이 매우 커짐
- Redo를 해야 하는 트랜잭션 중 대부분은 이미 데이터베이스에 반영
- 반영된 트랜잭션의 재실행은 시스템 자원의 낭비
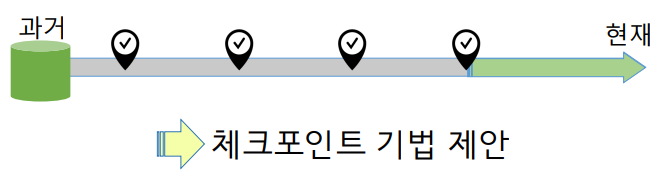
체크포인트 기법
- 현재 시점에 메인 메모리의 버퍼 블록에 존재하는 모든 로그 레코드를 안정 저장장치로 기록
(체크포인트가 발생하는 순간, 버퍼 블럭을 모두 output하고 일단 디스크에 저장)
- 수정된 모든 버퍼 블럭을 디스크에 반영
- 로그레코드
<checkpoint ListT>를 안정한 저장장치에 기록- ListT는 체크포인트 시점에서 실행중이 트랜잭션 목록
체크포인트 발생 시점에 시행되고 있던 모든 트랜잭션을 ListT라는 트랜잭션 집합에 포함시켜 처리된 트랜잭션과 처리 도중인 트랜잭션을 구분. 그리고 회복시킬 때 처리중이던 트랜잭션만 회복시킨다.
체크포인트를 이용한 회복
- 체크포인트 기법을 이용한 회복과정
- 로그의 마지막(가장 최근것)부터 역방향으로 탐색하여
<checkpoint ListT>레코드를 찾음 - ListT에 존재하는
<checkpoint ListT>이후에 실행된 트랜잭션에 대하여 Redo와 Undo 연산만 수행- 로그에 < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 > 또는 < 𝑇𝑖, 𝑎𝑏𝑜𝑟𝑡 >가 없는 𝐿𝑖𝑠𝑡𝑇안의 모든 트랜잭션을 Undo (체크포인트 시점에 실행중이었음을 의미)
- 로그에 < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 > 또는 < 𝑇𝑖, 𝑎𝑏𝑜𝑟𝑡 >가 있는 𝐿𝑖𝑠𝑡𝑇안의 모든 트랜잭션을 Redo (체크포인트 시점에 완료되어 기록(commit), 사용자가 인위적으로 트랜잭션 취소(abort)함을 의미)
- 로그의 마지막(가장 최근것)부터 역방향으로 탐색하여
원칙적인 회복 시스템은 동일. 다만, 체크포인트 시점 이후 것만 검토하여 검토량 축소가 차이점!
03. 회복 알고리즘
그래서 그 Redo, Undo는 어떻게 하는건데??
트랜잭션 롤백 알고리즘
트랜잭션 Ti의 롤백 알고리즘
1단계: 로그를 역방향으로 탐색
2단계: Ti의 로그 레코드 < 𝑇𝑖, 𝑋𝑗, 𝑉1, 𝑉2 >에 대하여
- 데이터항목 Xj에 V1을 기록
- 로그 레코드< 𝑇𝑖, 𝑋𝑗, 𝑉1 >을 로그에 기록.(원복시켰음을 의미하는 로그) (가장 기본적인 Undo과정.)
3단계: < 𝑇𝑖, 𝑠𝑡𝑎𝑟𝑡 >를 찾은 이후 - 역방향 탐색을 중단 (더이상 Ti가 없을테니 거슬러 올라갈 필요 없음)
- 로그레코드 < 𝑇𝑖, 𝑎𝑏𝑜𝑟𝑡 >를 로그에 기록 (롤백함을 의미)
트랜잭션 롤백 알고리즘
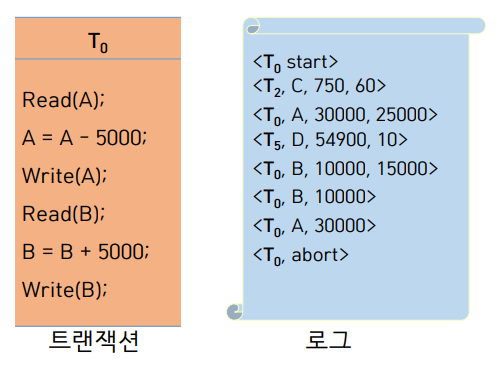
로그 6번째 줄부터 롤백을 하고 있음.
시스템 장애 후 회복 알고리즘
특정 트랜잭션 하나가 아니라 시스템 장애로 전체 회복 시스템이 어떤식으로 작동할까?
=> 먼저 요약하자면, 처음에는 역방향↑으로 쭉 타고 올라가면서 체크포인트를 찾고, 순방향↓으로 내려오면서 Redo하고, 가장 최근 로그에 도달하면 다시 타고 올라가면서↑ Undo를 시행한다.
- 시스템 장애 이후 재시작 시 다음 두 단계를 거침
- Redo, Undo 단계
- Redo 단계
- 최근의 체크포인트에서부터 순방향 로그 탐색
- 롤백 대상할 트랜잭션 Undo 리스트인 ListofUndo를 ListT로 초기화
- < 𝑇𝑖, 𝑋𝑗, 𝑉1, 𝑉2 >,< 𝑇𝑖, 𝑋𝑗, 𝑉1 >형태의 모든 레코드를 재실행
- < 𝑇𝑖, 𝑠𝑡𝑎𝑟𝑡 > 발견 시 Ti를 ListofUndo에 추가
- < 𝑇𝑖, 𝑎𝑏𝑜𝑟𝑡 >, < 𝑇𝑖, 𝑐𝑜𝑚𝑚𝑖𝑡 > 발견 시 Ti를 Undo리스트에서 제거
일단 로그들을 쭉 거슬러 올라가면서 체크포인트를 찾음. 그리고 체크포인트부터 다시 최근 기록으로 내려옴. 그러면서 Undo할 트랜잭션을 먼저 찾음. ListofUndo 리스트를 만들어서 가장 최근에 실행되고 있었던 트랜잭션을 담아두고 Undo 준비. 변경사항, 기록사항 있을 때마다 모두 재시행(Redo). Ti start 발견시, Undo에 추가. 만약 중간중간 abort, commit 기록이 있으면 정상 작동이 사용자에게 통보되었으며 모든 기록사항이 실제 디스크에 반영이 되어야 함을 의미. 따라서 ListofUndo에서 제거한다.
- Undo 단계 (역방향 로그 탐색)
- ListofUndo의 트랜잭션의 로그레코드를 찾으면 트랜잭션 롤백 알고리즘 1단계 수행
- ListofUndo의 트랜잭션 Ti에 대해 < 𝑇𝑖, 𝑠𝑡𝑎𝑟𝑡 >를 만나면 로그에 < 𝑇𝑖, 𝑎𝑏𝑜𝑟𝑡 >를 기록하고 ListofUndo에서 제거
- ListofUndo에 트랜잭션이 존재하지 않는 상태가 되면 Undo단계를 종료
가장 최근 로그부터 역방향으로 타고 올라가면서 디스크의 수정된 값을하나하나 이전으로 되돌리고 Ti의 start를 만나면 abort를 기록하고 ListofUndo에서 제거한다. 역방향으로 타고 올라가면서 ListofUndo가 남아있지 않으면 회복시스템을 종료한다.
로그에 기록된 회복 작업 예
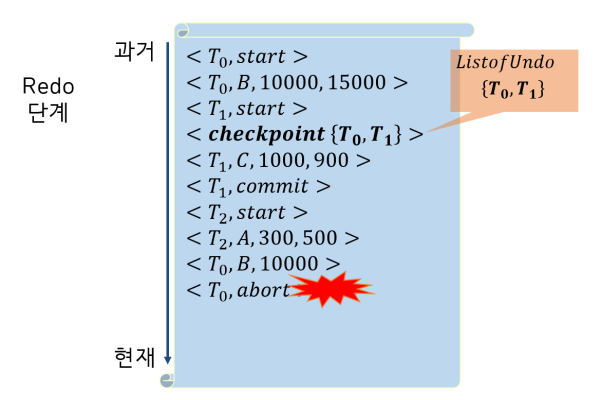
- Redo 단계
1) 올라가면서 체크포인트를 찾음.
2) 체크포인트 과정에서 이미 시작되었던 트랜잭션들을 ListofUndo로 만듦.
(그 이전것들은 이미 디스크에 저장되었을 것이고, 체크포인트 시점에 실행중이었던 트랜잭션은 undo의 가능성이 있으므로 일단 List에 후보군으로 담아둔다!)
3) 하나씩 내려가다 보니 T1 commit이 있음. T1은 List에서 뺌
4) 도중에 T2가 start되므로 list T2를 추가함.
5) To가 abort 되었으므로 list에서 제거함.
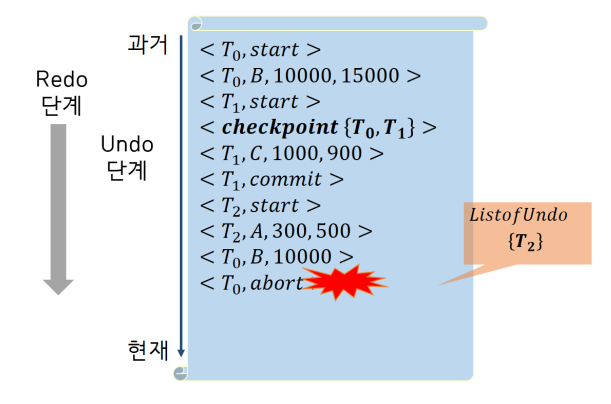
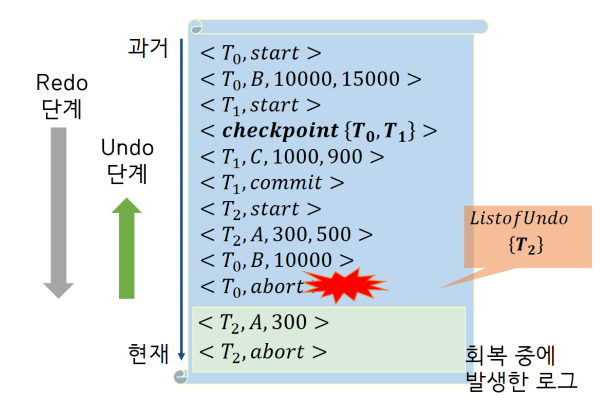
- Undo 단계
1) 다시 올라가면서 Undo 시작.
2) T2의 값 원복 <T2, A, 3000>
3) T2 start가 나왔으므로 abort 로그를 추가 <T2, abort>
4) <T2, satrt>가 나오면 List에서 T2 제거.
5) ListofUndo에 남아있는 트랜잭션이 없으므로 여기서 회복 시스템 종료.
참 사람들 꼼꼼하고 세심하게 복구 시스템 갖췄구나. 맞다... 나도 참 이 분야 공부하면서 하나하나 골똘히 고민했을 개발자들이 보이는것만 같다...
