1. 기본 세팅
우선 Chromedriver을 사용할 때 크롬 브라우저 화면을 띄우지 않기 위해 Headless Chrome을 사용해 주었습니다.

그리고 DataFrame을 만들고 csv 형태의 파일로 저장하는데 유용한 Pandas를 설치하겠습니다.

lxml도 다운받아 줍니다!
2. 페이지 분석하기
저의 크롤링 타겟은 포우 입니다.
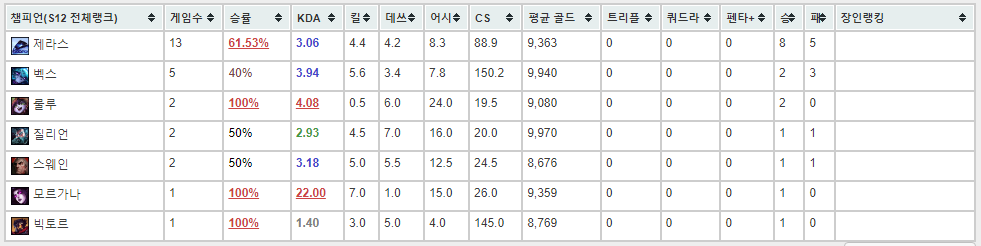
전적을 검색했을때 나오는 통계 표를 csv 형태로 저장해보려 합니다.
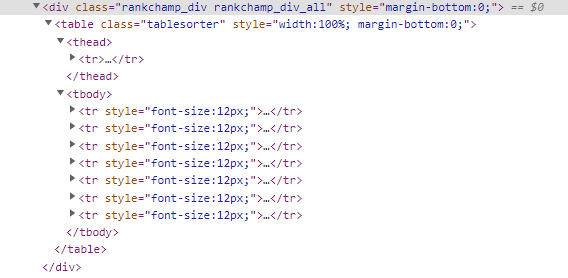
개발자 모드를 켜서 검사를 해 보면 위와 같이 나옵니다.
3. 코드 작성
사용할 라이브러리 import 하기
import selenium
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common import keys
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import WebDriverWait
import time # sleep
import pandas as pd # csv
import base64 # encoder
# Global Variable --> chromedriver
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')위에 설치한 pandas와 sleep을 사용하기 위한 time , encoder을 위한 base64까지 import 해 주었습니다.
타겟 지정
def run(nickname):
# target variables
target_url = 'https://fow.kr/'
search_box_xpath = '/html/body/div[1]/div[1]/form/div/input[2]'
search_btn_xpath = '/html/body/div[1]/div[1]/form/div/input[3]'
season12_table = '/html/body/div[5]/div[1]/div[1]/div[8]/table'-
target_url = 'https://fow.kr/'타겟 url인 fow URL을 넣어줍니다. -
search_box_xpath = '/html/body/div[1]/div[1]/form/div/input[2]
닉네임을 검색할 란의 xpath를 가져옵니다. -
search_btn_xpath = '/html/body/div[1]/div[1]/form/div/input[3]'검색버튼의 xpath 입니다. -
season12_table = '/html/body/div[5]/div[1]/div[1]/div[8]/table
크롤링해올 데이터를 갖고있는 테이블 xpath 입니다.
크롬드라이버와 셀레니움을 이용한 크롤러
# chromedriver on
driver.get(url=target_url)
# id search
explict_id(search_box_xpath, 3)
xpath_send_key(search_box_xpath, str(nickname))
xpath_click(search_btn_xpath)
# table download
explict_id(season12_table, 3)
table_to_csv(season12_table, 's12')-
driver.get(url=target_url)크롬드라이버에서 타켓 url을 받아와 실행시켜 줍니다. -
id search 코드
explict_id(search_box_xpath, 3)아래 선언 되어 있는 explict_id 함수를 실행합니다.
xpath_send_key(search_box_xpath, str(nickname))
마찬가지로 xpath_send_key 함수를 실행합니다.
xpath_click(search_btn_xpath)
xpath_click 함수를 실행하고, 위에 선언해 둔 search_btn_xpath. 즉, 검색버튼이 클릭됩니다. -
table download 코드
explict_id(season12_table, 3)explict_id 함수 실행
table_to_csv(season12_table, 's12')table_to_csv 실행
함수
explict_id 함수
def explict_id(element_id, time):
WebDriverWait(driver, int(time)).until(
EC.presence_of_element_located( (By.XPATH, str(element_id) ) )
)WebDriverWait(driver, int(time))
WebDriverWait을 사용해 driver를 최대 time초 동안 기다린다.
[time초를 넘기게 되면 NoSuchElementException, ElementNotVisibleException과 같은 에러가 발생.]
.until(EC.presence_of_element_located((By.XPATH, srt(element_id)))
XPATH가 element_id 인 엘리먼트가 나올 때 까지
explict_id(search_box_xpath, 3)search_box_xpath인 엘리먼트가 나올때까지 최대 3초동안 기다립니다.
xpath_send_key 함수
def xpath_send_key(xpath, key):
driver.find_element_by_xpath(xpath).send_keys(key)
time.sleep(0.15)driver.find_element_by_xpath(xpath).send_keys(key)
타겟페이지에서 xpath를 이용해 원하는 key에 해당하는 값을 가져온다
time.sleep(0.15)
0.15초 동안 대기
xpath_send_key(search_box_xpath, str(nickname))
html에서 xpath를 이용해 nickname에 해당하는 값을 가져온 후 0.15초 동안 대기
table_to_csv 함수
def table_to_csv(xpath, filename):
df = pd.read_html(driver.find_element_by_xpath(xpath).get_attribute('outerHTML'))[0]
df.to_csv('{}.csv'.format(filename)) pd.read_html pandas의 read_html을 이용하여 html에 있는 table속성에 해당하는 값을 가져옵니다.
get_attribute('outerHTML') outerHTML에 해당하는 속성 값을 추출합니다.
df.to_csv('{}.csv'.format(filename)) df의 값을 csv파일로 저장합니다.
table_to_csv(season12_table, 's12')
season12_table의 outerHTML에 해당하는 속성값의 table을 가져와 csv 파일로 저장하고, 파일 이름은 s12 입니다.
season12_table크롤링해올 테이블의 xpath
file name function
def convert_base64(nickname):
#preprocessing
pre_nickname = nickname.replace(" ", "")
ascii_nickname = pre_nickname.encode('ascii')
return base64.b64encode(ascii_nickname)base64를 이용하여 nickname을 ASCII 값으로 변경시켜주고,
공백이 들어가도 인식하게 인코딩 해주는 함수 입니다.
if __name__ == "__main__":
run('아먼찐다같은게')run('') 에서 입력받는 닉네임으로
def run(nickname): 함수를 실행시켜줍니다.
전체 코드
def run(nickname):
# target variables
target_url = 'https://fow.kr/'
search_box_xpath = '/html/body/div[1]/div[1]/form/div/input[2]'
search_btn_xpath = '/html/body/div[1]/div[1]/form/div/input[3]'
season12_table = '/html/body/div[5]/div[1]/div[1]/div[8]/table'
# chromedriver on
driver.get(url=target_url)
# id search
explict_id(search_box_xpath, 3)
xpath_send_key(search_box_xpath, str(nickname))
xpath_click(search_btn_xpath)
# table download
explict_id(season12_table, 3)
table_to_csv(season12_table, 's12')
# Crawler Function
def explict_id(element_id, time):
WebDriverWait(driver, int(time)).until(
EC.presence_of_element_located( (By.XPATH, str(element_id) ) )
)
def xpath_send_key(xpath, key):
driver.find_element_by_xpath(xpath).send_keys(key)
time.sleep(0.15)
def table_to_csv(xpath, filename):
df = pd.read_html(driver.find_element_by_xpath(xpath).get_attribute('outerHTML'))[0]
df.to_csv('{}.csv'.format(filename))
# file name function
def convert_base64(nickname):
#preprocessing
pre_nickname = nickname.replace(" ", "")
ascii_nickname = pre_nickname.encode('ascii')
return base64.b64encode(ascii_nickname)
if __name__ == "__main__":
# target_nickname = input('사용자 ID >')
run('아먼찐다같은게') 4. 실행 결과

위 코드를 실행시켜 줍니다!
무사히 s12.csv 파일이 다운로드된 모습입니다.
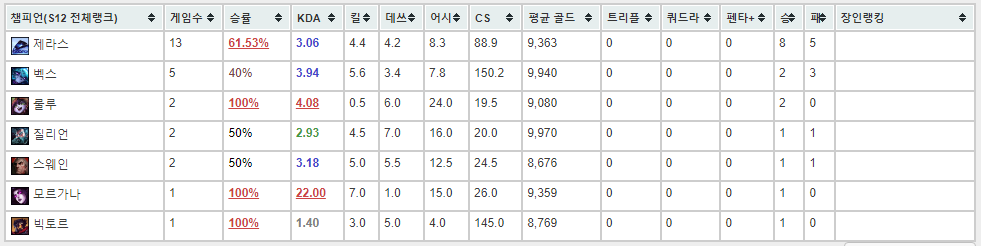
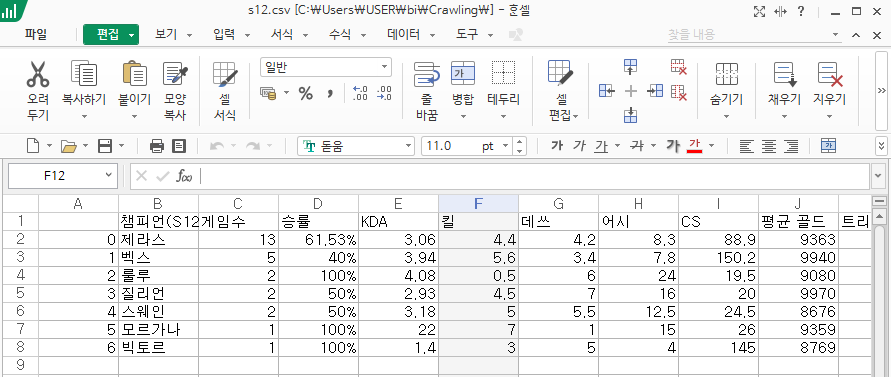
타겟이 csv 파일로 저장된 모습입니다.
