
크롤링 Crawling
- Web상에 존재하는 Contents를 수집하는 작업 ( 프로그래밍으로 자동화 가능)
-HTML 페이지를 가져와서, HTML/CSS 등을 파싱하고, 필요한 데이터만 추출
-Open API (Rest API) 를 제공하는 서비스에 Open API를 호출해서, 받은 데이터 중 필요한 데이터만 추출
-Selenium등 브라우저를 프로그래밍으로 조작해서 필요한 데이터만 추출
크롬웹브라우저와 Selenium을 사용하여 Python으로 간단한 웹 크롤링을 해보려 합니다.
chromedriver 에서 Chrome 버전과 맞는 ChromeDriver 을 받아줍니다.
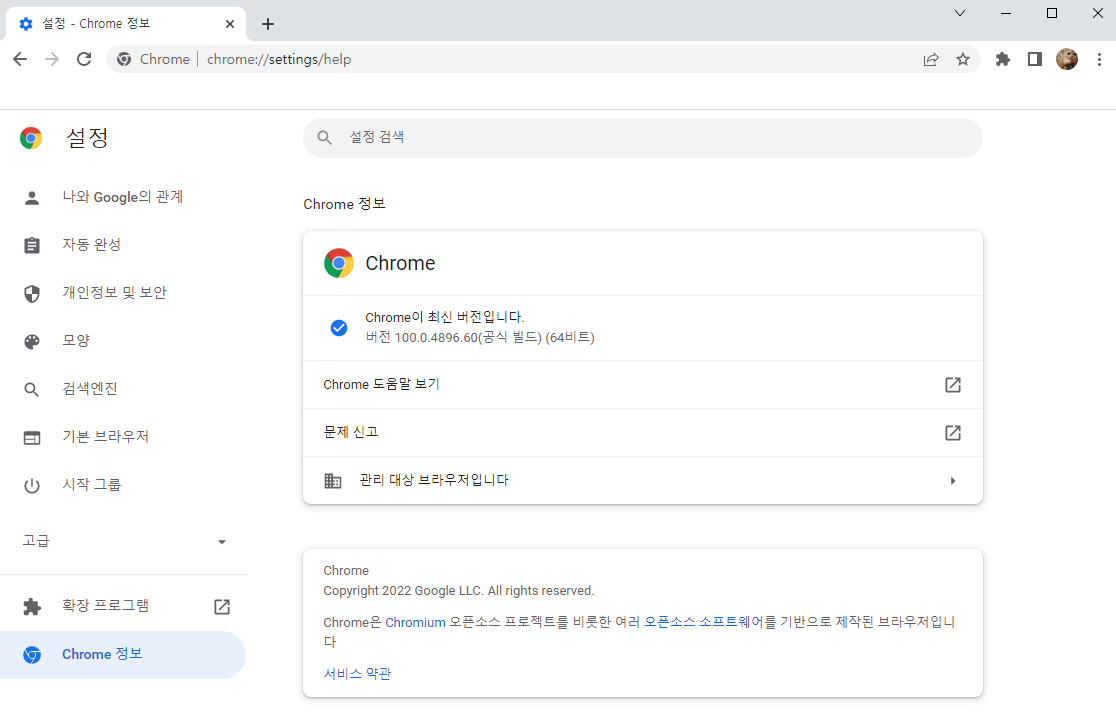
Chrome 버전 100.0.4898.60 을 확인해 줍니다.
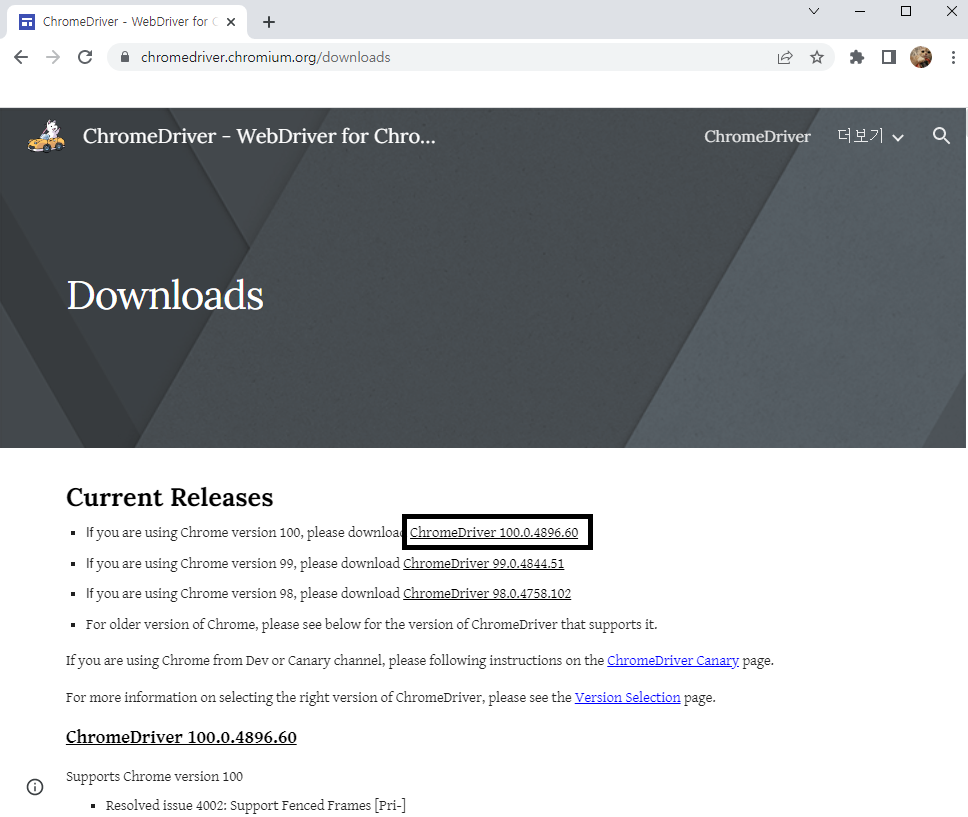
동일한 버전을 받아줍니다.
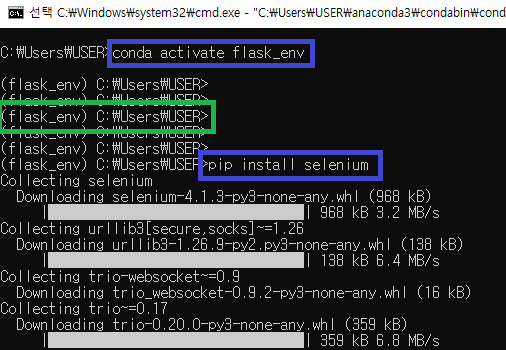
flask_env 가상환경을 활성화 시켜준 후 pip install selenuim 셀레니움을 설치해줍니다.
필요한 라이브러리를 import 합니다.
import selenium from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException import time
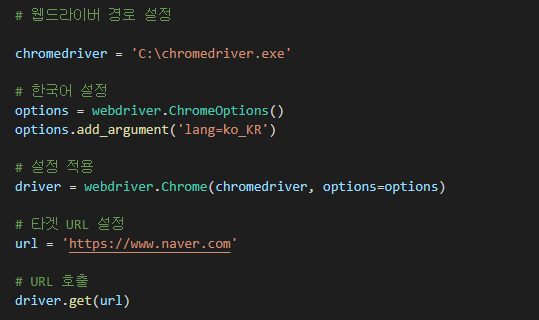
웹드라이버 경로를 설정하고, 한국어로 설정한 후 설정을 적용해주는 코드와,
타겟 URL을 설정한 후 URL을 호출하는 코드 입니다.

타겟 URL 화면에서 원하는 부분 우클릭 후 검사를 클릭합니다.

타켓 URL 에서
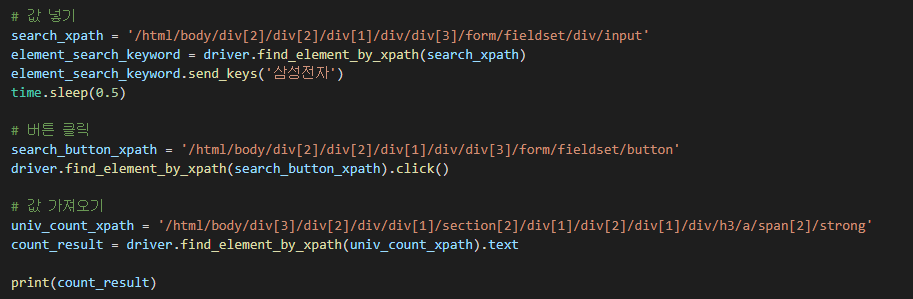
Copy full XPath 를 클릭 후 붙여넣기 하여 값을 넣어주었습니다.
입력값은 삼성전자를 입력하여, 네이버에 삼성전자가 검색되도록 합니다.
마찬가지로 버튼부분도 검사를 통해 Copy full XPath 하여 넣어줍니다.

삼성전자가 검색된 창에서 현재 주식가를 선택하여 Copy full XPath 하여 값을 가져와 출력하겠습니다.

data.py파일을 실행하니 크롬브라우저가 자동으로 켜지며 네이버 URL을 로딩했고 삼성전자를 검색합니다.

터미널 창에는 현재 주식가인 69,600 이 출력되는 모습입니다.
Chromedriver.exe 는 창을 끈다고 종료되지 않습니다.
cmd 창에서 taskkill -f -pid chrome.exe 를 입력하여 종료후 마무리 해줍니다.

https://li-yo.tistory.com/ 티스토리 블로그 이전 하였습니다.