데이터 사이언티스트란
-
명확한 정의는 없으니, 스스로를 잘 브랜딩 하자.
-
특성 기술을 할 줄 아는 사람으로 인지되는 걸 지양하자. 요새는 너무 많음.
-
스토리가 필요하다. 과거의 직무.
-
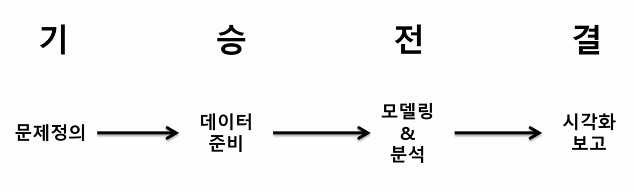
기승전결 중
기와결이 중요. 어떤 데이터를 분석했는지는 필요 없음. -
어떤 문제를 가졌고, 어떤 문제를 풀었고 어떤 결과를 만들어냈는가가 중요.
-
DS는
예측을 한다. -
과거의 데이터에 기초해서
예측을 한다. -
비슷한 데이터셋을 찾아서 했는데 진짜 없으면
상상한다. -
상상=가정을 구체화하는 것이모델링 -
모델링은 세계관을 만드는 과정. -
그
모델링에는 등장인물과(변수), 규칙(알고리즘)가 필요. -
근데 정규분포를 따른다는
근본 가정이 어차피 틀렸으니까, 얼마나 덜 틀리냐가 더 중요. 맞힌다기 보다 가까워지는 과정. -
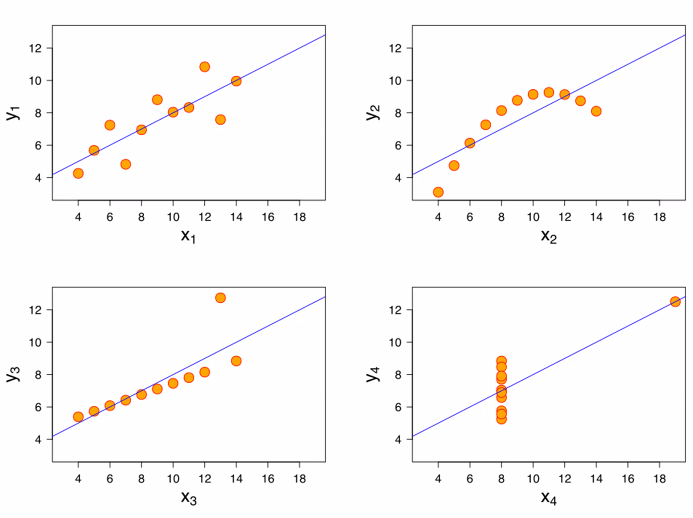
모든 재료를 다 넣는다고 맛있지 않은 것처럼, 변수가 많으면 모형의 설명력은 높아지지만 우리가 얻을 수 있는 인사이트는 감소. 보통 10개 미만이면 충분.
-
세상에는 white box(decision tree)와 black box(random forest)가 존재.
-
white box 모델은
해석이 중요. black box 모델은성능이 중요. -
최근 black box 모델을 해석하고 싶어하는 경향이 강해짐. -> XAI(설명가능한 인공지능)
-
XAI는 모델에게 질문을 해서 '어떤 변수가 제일 중요해?' 등, 모델로부터 얻은 답으로
해석을 하는 것. -
데이터 사이언티스트는 Analytics- 주/월/분기/연 단위 (레포트 보고)
- 계획, 전략, 고객
-
ML엔지니어는 Operation- 0.2초 안에 request/response (광고 추천 등)
- 광고추천, 객체인식, 음성인식
-
데이터 사이언티스트는 극단적으로 컨셉카 만드는 사람들.데이터 엔지니어는 엔진 만드는 사람들. 둘 다 잘 하면 유니콘🦄

-
Analytics에서 제일 중요한 건 reporting랑 visualizing reporting에서는 알고리즘/통계/ML 이런거 NO 필요. 아무도 관심 없음. -
대시보드는 지양하고 한 판에 그려라. 대시보드는 모니터링 할 때만 씀.
-
report에 인사이트가 부족하면?
드릴 다운= 데이터를 파본다. 우리가 받은 데이터는 평균 데이터가 많으니까 다시 원본으로 파고 들어간다.
-
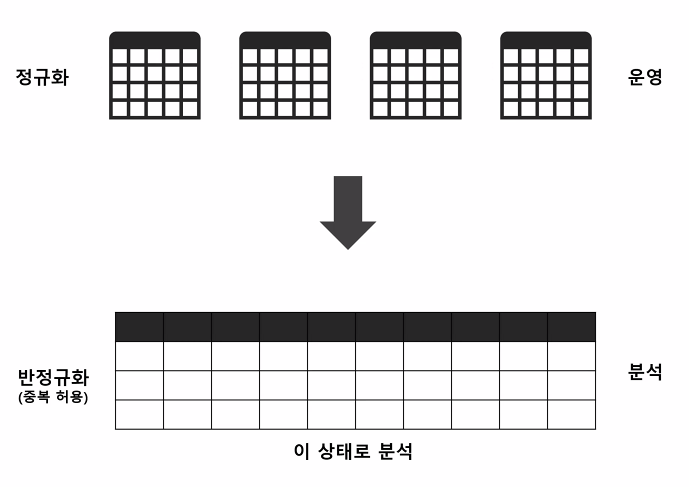
다차원분석이란? 여러 테이블을 한 번에 합쳐서 분석. 원래는 중복이 많아지고 느려지니까 안 썼는데 이젠 빅데이터 시대라 데이터가 워낙 중요하니까 다 때려박고 모든 걸 통합해서 본다. 대신 속도는 겁나 느려짐.
-
설명은 어떻게 해야할까? 설명은 무조건
인간적인 언어로. 쉬운 말로 안 나온다는 건 잘 모르니까
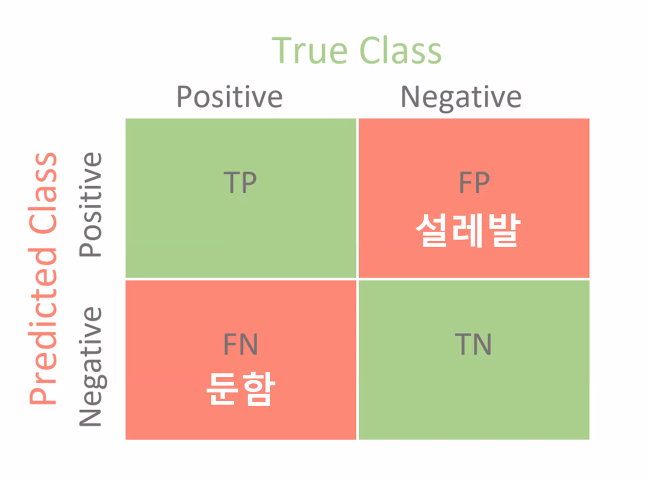
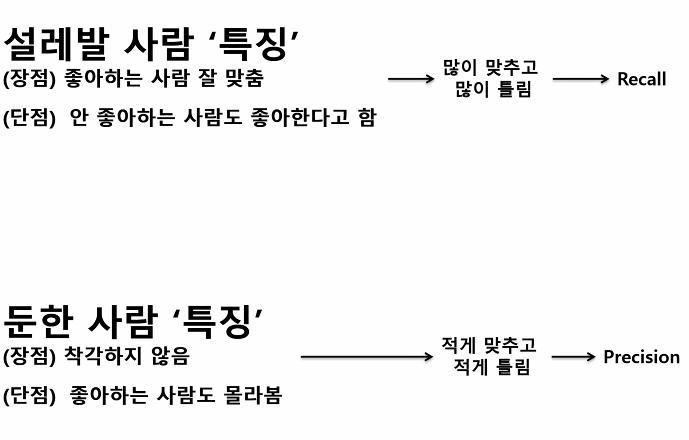
- reporting의 기본은
스토리life sycle, 기승전결 등

- 데이터 엔지니어가 하는 일이 제일 귀찮고 힘들어서 몸값이 제일
높음
QnA
IT기업들에 비해 컨설팅사에서 DS로 근무한다면 어떤 메리트가 있을까요?
- 애널리스틱을 하기 때문에 이직이 쉽다. 대신 도메인이 없어짐.
- IT기업을 가면 한 분야만 파서 한 분야의 전문가가 될 수 있다.
- 안정적이고 하나를 깊게 하고 싶으면 IT를 가는 게 좋지만, 컨설팅을 하면 도메인은 얕아지고, 전문가를 만나면 깨지지만, 새로운 경험을 많이 할 수 있고, 컨설팅의 도메인은 로직이기 때문에 어떤 일을 만나도 다 할 수 있음.
- DS는 도메인으로부터 자유로운 게 좋기 때문에 어떤 현업이랑 만나도 잘 할 수 있다.
IT업계가 아닌 컨설팅사의 DS의 구체적인 업무 프로세스와 사내 문화가 궁금합니다.
- 주 52시간...? 말도 안 됨.
- 컨설턴트는 재택근무 X. 무조건 빡셈.
- 항상 평가를 받는 직업. 항상 현업(고객사)에게 평가를 받아야함. 대우가 안 좋을 때도 많음. 회의실을 안 주고 창고만 줄 수도....?😥
- 힘들고 빡세고. 정시퇴근? 웃기네.
- 사외에서는 DS로 불리지만, 사내에서는 업무 구분이 거의 없고 다 함.
- 업무 프로세스가 다 뒤집히는 경우도 다반사. 그냥 일상이기 때문에 고객사가 다 뒤집어도 어쩔 수 없음. 거기서 "억울합니다" 하면 "나가세요" 됨.
- 고객사가 원하면 뭐든 해야함.
- 이 일을 좋아하면 이 일 밖에 못 함.
- 누가 나한테 뭐 부탁하고 해달라는 게 좋으면 잘 맞음.
- 금전적이나 복지가 많음.
- 초봉은 높지 않으나, 연상승률이 높음. 보통 20년 걸리는 연봉 상승폭이 8~10년이면 됨. (대신 그 전에 과로사 할 수는 있음)
전략 컨설팅사에서 DS는 컨설턴트와의 협업은 어떻게 진행하나요?
- 전략은 정말 추상적인 이야기를 함. 뜬구름 잡는 소리이기도 함.
- 그걸 유일하게 구체화하는 건 회계.
- 전략 컨설팅사에서 DS가 협업 하는 경우는 거의 없고, 거의 operation 작업을 해주는 경우.
- 전략 컨설팅사에서 전략을 짜면 그를 위한 툴을 만들어주는 게 DS.
기존의 컨설팅 프로젝트와 데이터 기반 컨설팅 프로젝트의 가장 큰 차이점은 무엇이라고 생각하시나요?
- 요즘 현업들은 python을 알아서 excel로 하면 '쉽게 가네?' 이래서 요새는 python을 하는 게 대세.
- excel로 로직 짜가면 아니꼬워 함.
- NLP 기법이 유행함. 실제로 업무에 도움된다고는 말 못 하지만 요새 그냥 많이 함.
최근에 가장 많이 의뢰받고 있는 산업 or 직무의 문제는 무엇인지 궁금합니다.
- 컨설팅을 쓰는 회사는 거의 제조업. 돈이 무지하게 많은 회사.
- 구체적으로는 반도체, 석유, 정유, 화학, 자동차 등
- 코로나 뒤로 다 틀어지니까, 모든 회사가 '코로나 같은 걸(글로벌 이벤트) 예측해달라'라는 의뢰가 많음.
- 생산 계획 같은 게 중요한 회사들이기 때문에 글로벌 이벤트 같은 경우를 예측하고 싶어함. 원래는 산공에서 최적화로 풀었는데 이걸 요새는 데이터로 풀려는 시도를 많이 함.
최근 주목받고 사용량이 급증하는 시각화 툴은 무엇인지 궁금합니다.
- 국내에서는 태블로가 많이 사용됨.
- 원래 사용하던 툴(MSTR)을 사용하는 경우도 많아서 태블로가 압도적인 점유율은 아님.
- 태블로가 좋은 이유는, DS가 만든 툴이라, 굉장히 쓰기 편함(grammer of graphics).
- 4시간 정도 교육을 하면 대시보드 정도는 거의 다 만들 줄 알고, 3~7일 정도 교육을 하면 어려운 수준까지 다 만들 수 있음.
- 엑셀을 계속 쓰는 이유는 새로운 걸 배우기 싫어해서 그렇고, 컨설턴트 중에는 엑셀을 적.폐.로 보는 경우도 있지만, 뭐 딱히 그렇게까지는 아니라고 생각함.
- 그럼에도 태블로는 달랐음. 좋음.👊
업무적인 스킬 말고도 필요한 게 뭐가 있었는지, 그걸 얻기 위해 어떻게 했는지 궁금합니다.
- 업무적 스킬보다 커뮤니케이션 스킬이 더 중요함.
- 고객이 뭘 원하는지를 아는 게 제일 중요함.
- DS의 치명적 실수는 고객이 필요로 하지 않는 걸 가져가는 것.
- 오히려 하드 스킬은 대체할 수 있으니까 없어도 괜츈.
- DS는 고객의 만족이 중요하니까 고객이 원하는 걸 캐치할 수 있는 능력이 정말 중요함.
- 짬과 센스로 가능.
데이터 분석을 해오면서 가장 까다로운 케이스가 있었는지 궁금합니다. 그리고 그 사례를 어떻게 해결했나요?
- 분석해서 가져가면 항상 '정확도가 왜 이렇게 낮나요?'
- 근데 애초에 한계가 있는 데이터는 아무리 고성능의 알고리즘 써도 안 올라감. 이걸 고객한테 어떻게 설명하는지가 중요함.
- 그러니까 너무 잘 된 결과를 가져가지 말고 2~3번 쿠사리 먹고 좋은 걸 가져가야 함.
- 과녁을 늘리는 것도 할 수 있음.
- 10개로 분류할 걸 7개로 분류하도록 소통해서 풀어내는 것도 능력.
- 정확도만 주구장창 걸고 넘어지는 고객도 많음.
- 정확도만 올려놓고 해석이 어려운 경우도 많은데, 그런 건 윤리적으로 지양해야 함.
데이터 직군의 사람들이 일하는 데 있어서 공통으로 가장 빈번히 불편해하는 부분이 무엇인가요?
- 현업에서는 주피터, 코랩 못 씀.
- 넘파이, 판다스도 못 씀.
- 개발 환경 구축하는 게 힘듬.
- 보안이 중요한 데이터가 많아서 라이브러리를 쉽게 쓸 수가 없음.
- 라이브러리를 못 쓰면 DS가 할 일을 다 못 할 수도 있으나 짬으로 해결 가능.
- 분석 환경을 구축하는 게 어려움.
DS의 제일 중요한 역량/능력은 무엇인가요?
- 많이 몰라도 되니까 본인들이 사용한 것은 확실히 알았으면 좋겠음.
- 커리큘럼을 그대로 복붙한 거 말고, 내가 한 분석에 대한 스토리를 읽어봄.
- 현업에서도 그렇게 어려운 모델을 안 쓰기 때문에(한정된 상황에서만 사용) 어려운 거 썼다는 것을 자랑하기보다 자기가 사용한 모델을 정확히 설명하고 분석 예제를 설명하는 게 좋음.
- 인사권자는 아저씨들이기 때문에 깃랩, 블로그 첨부해도 안 봄. 문서화해서 프린트 해서 볼 수 있도록 하는 게 좋음.
- 보고를 잘 해야 함. 시각화가 중요.
포트폴리오에서 가장 중요하게 보는 것이 있다면 어떤 것이 있을까요? 기능구현과 고민의 흔적 중 어떤 게 더 중요할까요?
- 논리의 비약이 있는 순간 정뚝떨.
- 본인이 쓴 내용에 대해서는 신뢰가 있어야 함.
- 진짜 본인이 이해해서 쓴 거여야 정감 감.
- 컨텐츠가 똑같아도 잘 읽히는 글들이 있음. 맞춤법이나 형식이 잘 맞는 경우.
- 단정하고 깔끔한 게 최고.
DS가 기업조직에서 어느 정도 유동성과 책임을 지고 자신의 업무에 임할 수 있는지 궁금합니다.
- DS에게 유동성과 책임을 요구하면 결과를 끼워맞추게 되는 경우가 있기 때문에, 많이 안 갈궈야 함.
- 로직대로는 좋은 결과가 나와야 하는데 안 나와서 '누가 그랬어!'하면 DS가 튀어나오는데, 그 때 항변 할 수 있어야 함.
- 미래는 예측은 못 하지만, 미래를 조각내서 보는 것은 가능하다고 얘기할 수 있어야 함.
DS는 어떻게 팀이 꾸려져서 컨설팅 업무를 진행하는지 궁금합니다.
- 단독은 거의 없고, 모델링 역량이 없는 회사에는 나홀로 프로젝트를 하는 경우도 있지만, 대부분 DE, DA랑 같이 들어감.
데이터로 트렌드를 읽는 법이 궁금합니다.
- DS가 하는 건 예측인데,
요즘데이터를 찾는 게 어려움. 그래서 어떻게요즘데이터를 확보하는지가 관건. - 그래서 DE나 웹크롤링이 중요함.
- 트렌드를 빨리 읽어내기 위해서
데이터 파이프라인이 주목을 받고 있음. - NLP(자연어 분석)이 그래서 인기.
- 핫하나 아직 성숙하지 않은 분야.
도메인 지식이 부족한 경우, 어떠한 방법으로 데이터 분석을 하는지 궁금합니다.
- 고객사가 '암것도 모르면서 왜 전문가 행세?'라고 까는 경우가 많음.
- 그래서 공부를 많이 함. 책도 많이 읽고 유튜브도 많이 봄.
- 어차피 현업도 도메인이 깊지 않음.
- 테크니컬한게 아니라 용어나 표현, 프레임 같은 걸 익숙해지면 금방금방 하게 됨.
어떻게 데이터를 수집하는지 궁금합니다.
- 컨설팅에서는 내부 데이터를 많이 씀.
- 웹 상에서 긁어오는 건 마케팅에서 많이 쓰이는데 신뢰성에 유의해야 함.
- 웹에서 긁어보면 1회성이 아니라 구축을 하고 싶어하는 경우가 많음.
기타 질문 사항
DS가 되기 위해서는 석박이 필수인가요?
- 솔직히 말해서, 석사가 정말 많음. 석사를 안 한 분들에 대한 제한이라기 보다 업무에서 DS가 유행한게 3~4년밖에 안 됐는데, 대학원에서는 전부터 있었기 때문에 그 분들이 물을 만난 것.
- 옛날에는 석사들 그냥 쭉 다 데려감.
- 근데, 1~2년 이내에는 학위 보다는 커리어가 더 중요해질 듯.
- 프리랜서도 많아질 것 같음. 어떤 일을 했는지가 더 중요해 질 것 같음.
- 석사가 너무 많음.
컨설턴트는 근속연수는 길지 않은데, DS의 근속연수는 어떠한가요? 컨설팅사를 거친 DS의 다음 커리어로는 어떤 것들이 있을까요?
- 컨설턴트들은 이직이 쉬워서 짧고, DS는 더 짧음. 더 이직이 쉬워서.
- 1~2년 하고 나가는 분도 많음.
- DS는 3년은 커녕 1년 채워도 충분.
- IT회사들은 DS는 선호하지 않음. 보통 뽑는다면 전략이나 IT스럽지 않은 직무를 뽑을 때 좋아함.
- 보통 DS 좋아하는 회사는 제조업. 매출은 높고 돈은 잘 버는데 고학력 인재가 부족한 곳에서 선호함.
- 재벌 위주의 회사에서 DS를 선호함.
DE 없이는 업무가 힘든데 DE가 없다면 어떻게 하나요?
- DE는 시스템을 짤 때 필요한 거지, 분석을 할 떄 꼭 필요한 것은 아님.
- DE 능력이 없다고 꼭 문제가 있는 것은 아님.


정리 감사합니다~!