1️⃣ 첫 번째 아키텍처
처음 프로젝트에 합류했을 때, 처음 전달받은 데이터 아키텍처는 단순했다.

취업 전 프로젝트들을 Postgresql로 진행하고 회사에서도 Postgresql이었기 때문에 같은 RDB를 진행하기 좋은 기회라고 생각하여 크롤링 코드만 좀 잘 배워서 DB 성능 개선같은 걸 할 수 있지 않을까 해서 프로젝트에 참여하기로 했다.
실제로 DB 스키마도 어느정도 짜여 있었고 백엔드도 합의. 데이터팀도 합의 한 상태였다. 하지만 문제는 서비스 기획 단계에서 점점 프로젝트 사이즈가 커져가는 것이었다. 크롤링 해야하는 데이터의 개수가 많아질 수록 RDB가 이것을 다 감당할 수 있을까? 싶었고 결국 DB를 바꾸기로 한 것이 2023년 1월이었다.
결과적으로 2022년 12월에는 크롤링 공부와 SQLAlchemy나 pymysql을 공부했고, ORM이 흥미롭다는 수확을 얻고 아키텍처의 변경에도 수긍했다.
2️⃣ 두 번째 아키텍처
변경하기로 한 DB는 Elasticsearch였다.
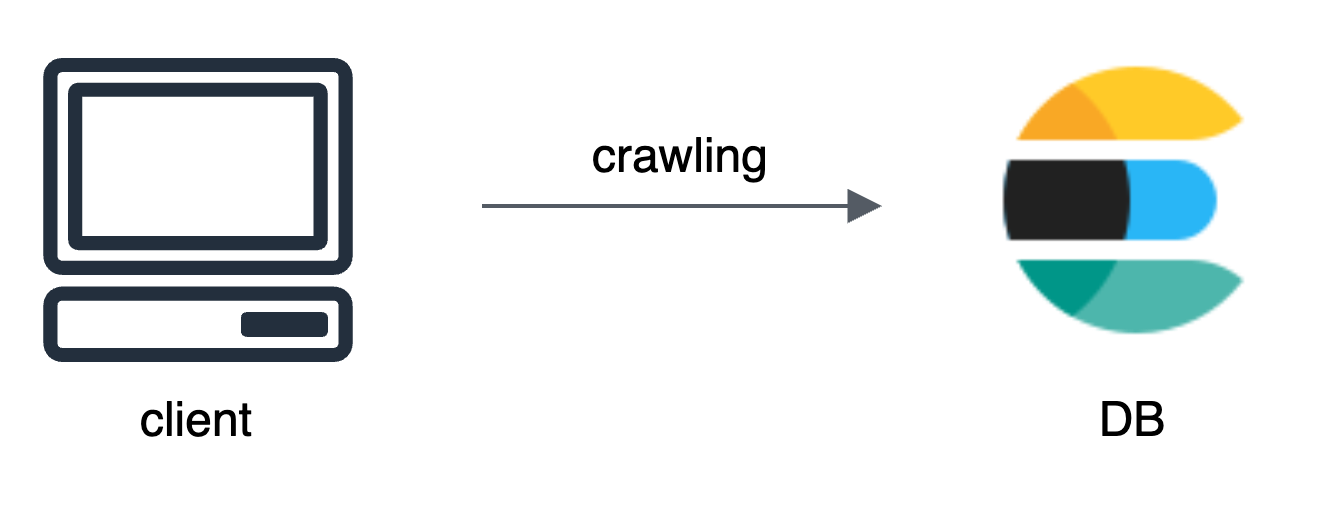
이번에도 구조는 간단했다. ELK 스택을 이용한다면 시각화나 로그 수집도 쉽지 않을까 해서 선택을 했고, 다행히 개발팀 모두 es에 대해 입문은 해봤다는 긍정적인 환경도 있어서 es 도입이 시작되었다.
데이터팀은 총 두 명인데, 나는 주로 es에 데이터를 어떻게 잘 저장할까, 백엔드에서 가져갈 때 어떤 구조로 짜야 쉽고 빠르게 가져갈까를 담당했고, 다른 한 분은 ec2위에서 es를 구성하는 작업을 담당했다.
ELK 스택은 워낙 다양한 기업에서 사용되고 있기 때문에 얕게나마 es나 kibana를 공부하는 좋은 경험이었다.
하지만, 백엔드단에서 모든 데이터를 es에서 가져가면 서버가 금방 죽을 것 같다는 의견을 제시하였고, 실제로 업데이트도 많고 데이터의 양도 하루에 최소 몇백만건이 늘어날거라 ec2가 죽을까 걱정이 되어 다시 한 번 아키텍처를 변경했다.
3️⃣ 세 번째 아키텍처
세 번째 아키텍처를 짤 때부터는 슬슬 "데이터 양이 많으니 Data Lake나 Data Warehouse를 만드는 건 어때?" 라는 이야기가 나왔고, 처음으로 S3와 Athena를 도입했다.
기존에 더미데이터로 쌓아놓은 데이터들은 aws RDS MySQL에 있었기 때문에 Parquet로 변환하면서 Migration 하고, S3-> 그 다음 Athena로 넘겨주었다.
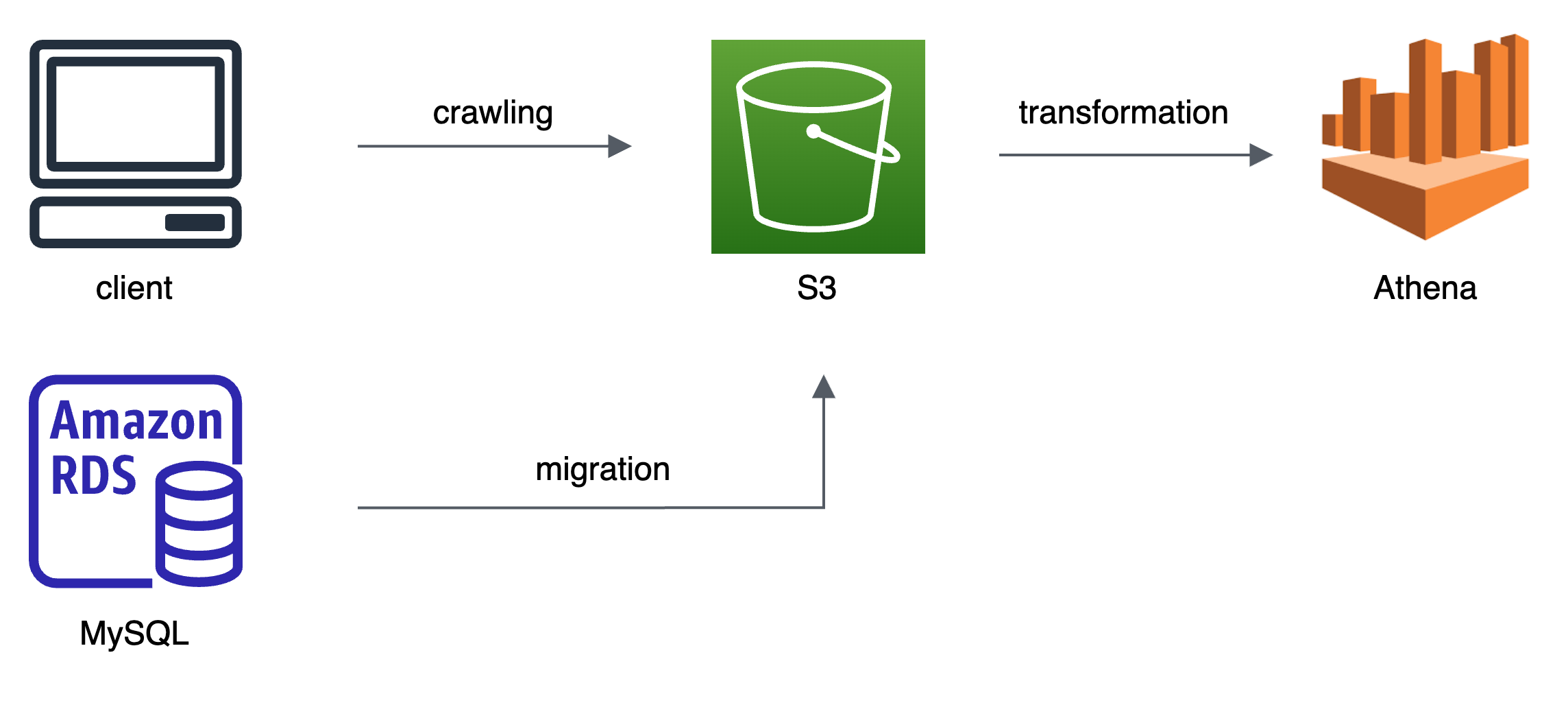
migration도 잘 했고 크롤링 코드로 s3에 parquet 형태로 들어가는 것도 잘 되는 것을 확인했다. 하지만 athena가 생각보다 쿼리 속도가 잘 안 나와서 백엔드단에서 다시 한 번 방법을 찾아야 한다는 이야기가 나왔다.
당시, s3에는 파일 압축과 해제에 빠른 parquet 형태로 저장되어있었고, 날짜별로 파티셔닝도 되어있었다. 하지만, athena 자체가 DB가 아니기 때문에 분석용으로는 속도가 걸려도 상관없지만 서비스 운영적으로 사용하기에는 무리가 있다는 것을 간과했다.
데이터팀인 내가 그것을 먼저 인지하고 도입 전에 말했어야 했는데 그것을 하지 못 해 조금 아쉬웠다.
서비스단에서 "%초등영어%"가 들어간 쿼리를 날려 데이터를 띄우는데 2-30초가 걸렸다. 파티셔닝이나 쿼리 개선 등의 방법도 있었을 수 있지만, 우리는 좀 더 근본적인데 문제가 있다고 판단했고 athena를 버리고 실제 DB를 이용해야 한다고 다시 얘기되었다.
거기서, 나는 다시 한 번 es의 도입을 건의했다. 결국 백엔드에서 키워드를 검색했을 때 데이터베이스에서 빨리 가져가야 한다면 결국 "검색" 속도만 빠르면 되지 않을까 싶어서 이번에는 ec2상에서 es를 돌리는 것이 아니라 아예 aws에서 제공하는 Opensearch를 도입하자고 건의하였다.
4️⃣ 네 번째 아키텍처
이번에 아키텍처를 짤 때는 좀 더 전문적으로 접근하고 싶었다. 그래서 우리는 aws startup support 팀에게 도움을 청했고, 기존 아키텍처의 문제점과 개선 가능성 등을 들을 수 있었다.
갑자기 훅 전문적어져서 여러 공부와 시도가 필요했다. 가장 기본적인 흐름은 아래와 같다.
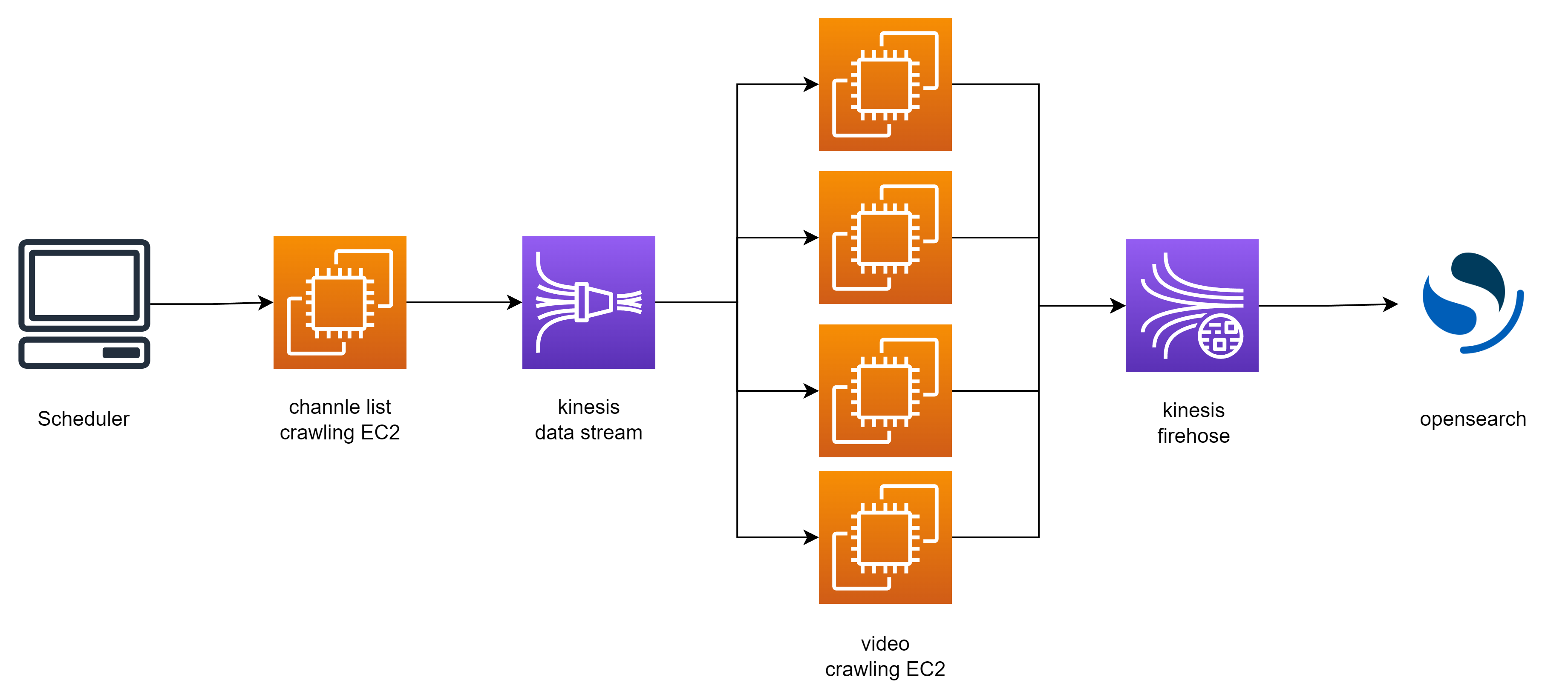
kinesis를 써보는 것도, Opensearch를 써보는 것도, scheduler를 구축하는 것도 처음이라 많은 시행착오가 있었지만, 내가 맡은 업무에서 다시 한 번 문제가 생겼다.
채널리스트와 영상 크롤링을 하는데 ray 같은 병렬처리가 불가능하고 ec2 서버 자체가 모델을 위해 메모리가 좀 클 뿐 cpu 등의 리소스는 별로라 크롤링이 속도가 너무 안 났다. 그래서 데이터는 흐르나, 우리의 수집 주기를 도저히 따라갈 수 없는 속도라 어쩔 수 없이 큰 흐름은 가져가되, 새로운 시도가 필요하게 되었다.

잘 읽고 갑니다~!! 👍👍