문제 상황
기존 RDS만 이용하는 아키텍처에서 S3->Glue->Athena로 아키텍처를 바꾸었다. 따라서 기존 RDS에 있던 데이터들을 날짜 파티셔닝 하여 S3에 넣기로 하였다.
그 전에, channel_history 테이블에는 크롤링해서 DB에 insert 된 날짜가 기록되어 있었지만 channel 테이블에는 없어서 나중에 컬럼을 추가해주었다(테이블 설계를 잘 했어야 했는데...). 그러고 default로 current timestamp을 해주었더니 실제 크롤링 된 날짜가 아니라 그 컬럼을 만든 날짜로 컬럼이 채워져서 당황했다.
그래서 channel_history랑 channel 테이블은 같은 데이터를 같은 날 수집했다. 라는 전제하에 channel_history의 날짜컬럼을 고대로 복사해와 channel 테이블의 날짜컬럼을 수정하기로 하였다.
현재 상황
SELECT c.channel_id, c.crawl_update_at as channel_date, ch.crawl_update_at as channel_history_date FROM channel c JOIN channel_history ch ON c.channel_id=ch.channel_id;
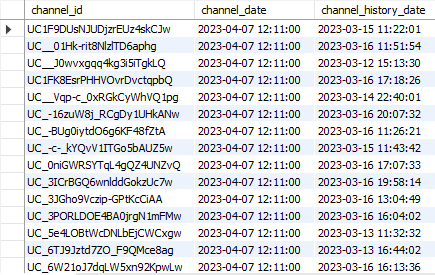
같은 데이터이고 같은 날에 DB에 저장되었음에도 두 테이블에 날짜가 다른 것을 확인 할 수 있었다.
첫 번째 문제 해결
이를 해결 하기위해
channel_history테이블의 날짜 컬럼을 복사해서channel테이블에 넣어주었다.
UPDATE channel c
JOIN (
SELECT channel_id, crawl_update_at
FROM channel_history
) ch
ON c.channel_id = ch.channel_id
SET c.crawl_update_at = ch.crawl_update_at;그 뒤, 결과를 확인해보니
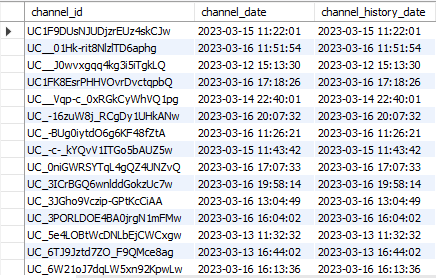
쨔잔😎 무사히 업데이트 된 것을 확인할 수 있었다.
두 번째 문제 해결
이제 원래 목적이었던 MySQL 데이터를 S3에 저장하기 위한 작업을 수행해보자.
우선, Athena를 사용할 것이기 때문에 S3에 날짜별로 파티셔닝해서 데이터를 넣어두어야 한다. 그를 위해 channel 테이블과 channel_history 테이블을 날짜별로 csv로 export 해주어야 하고, 그 전에 S3에 날짜별로 폴더를 만들어놔야 한다.
우선, 현재 몇 개의 날짜가 존재하는지 확인하기 위해 쿼리를 날려보았다.
SELECT DATE(crawl_update_at) AS date, COUNT(*) AS count
FROM channel
GROUP BY DATE(crawl_update_at)
ORDER BY 1;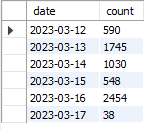
확인 결과, 총 6일동안 6500여개의 채널 데이터를 수집한 것을 알 수 있었다.
따라서 아래와 같은 쿼리를 통해 날짜별로 S3에 넣어주려 시도했다.
SELECT *
FROM channel
WHERE date(crawl_update_at)='2023-03-12'
INTO OUTFILE 's3://dothis-crawling-data/channel/dt=2023-03-12/channel.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n';하지만...
ERROR 1227 (42000): Access denied; you need (at least one of) the FILE privilege(s) for this operation
계속해서 이런 에러를 뱉어내길래 DB 권한을 가지고 있는 백엔드에게 권한을 요청하니....현재 우리가 사용하고 있는 RDS는 프리티어라 MySQL 8.0을 쓰고 있다고 하는데, 그 8.0 버전에는 OUTFILE 기능이 없다고 한다.....ㅎ aurora를 써야 생긴다고 하니 어쩔 수 없이 데이터를 수동으로 옮기기로 했다.
세 번째 문제 해결
그런데, 여기서 간과하고 넘어간 부분이, 대부분의 블로그 글에서는 csv로 S3에 넣길래 우리도 그렇게 할까 했더니, 용량이 너무 커지기도 하고 비용도 감당이 안 될 것 같았다. 그래서 파일 형식에 대한 고민을 시작했다.
우선, S3에 넣을 수 있는 파일 형식은 아래와 같다.
- CSV
- TSV
- JSON (newline delimited JSON, JSON with arrays)
- Apache Parquet
- ORC
- AVRO
- Apache RCFile
- SequenceFile
- Text (plain text)
그리고 압축 방식은 아래와 같다.
- Gzip : 일반적으로 가장 많이 사용되는 압축 방식 중 하나로, 데이터를 빠르게 압축할 수 있습니다. Gzip은 일반적으로 텍스트 파일에 사용됩니다.
- Snappy : 데이터를 빠르게 압축하고 해제할 수 있으며, CPU 사용률이 낮아서 대량의 데이터를 처리할 때 유용합니다.
- LZO : 데이터를 압축하고 해제할 때 CPU 사용률이 낮으며, 매우 큰 파일을 처리할 때 효과적입니다.
- Bzip2 : 압축률이 높지만 압축과 해제 속도가 느리며, CPU 사용률이 높기 때문에 대규모 데이터를 처리하는 데는 적합하지 않습니다.
- SnappyCodec : Snappy와 비슷한 압축률을 가지며, 데이터를 처리할 때 CPU 사용률이 낮습니다. 하지만 압축 속도는 Snappy보다 느리며, 대용량 데이터를 처리할 때는 효과적이지 않을 수 있습니다.
- 이 외에도 LZ4, Zstd 등 다른 압축 방식도 지원합니다.
처음 백엔드분은 주로 사용되는 gzip-json 압축-파일형식 방식을 선택하셔서 알려주셨다. 하지만, 빅데이터를 자주 조회하고 다루기에는 내 생각엔 snappy-parquet도 나쁘지 않을 것 같았다. 무엇보다 쌓인 데이터를 자주 조회하거나 앞으로 분석면에서 여러번 건들이고 싶은 내 입장에서 전자보단 후자인 쪽이 속도면에서도, 비용면에서도 나을 것 같아 비교 분석 해보기로 했다.
# pip install pyarrow python-snappy
import gzip, snappy, time, os, json
import pyarrow as pa
import pyarrow.parquet as pq
import json, pandas as pd
from pathlib import Path
# 파일 크기 변환 함수
def convert_size(size_bytes):
import math
if size_bytes == 0:
return "0B"
size_name = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB")
i = int(math.floor(math.log(size_bytes, 1024)))
p = math.pow(1024, i)
s = round(size_bytes / p, 2)
return "%s %s" % (s, size_name[i])
BASE_PATH = Path('원본파일경로')
logfile_path = BASE_PATH/'파일명.json'
gzipfile = BASE_PATH/'파일명.gz'
pqfile = BASE_PATH/'파일명.parquet'
file_size = os.path.getsize(logfile_path)
print('원본json 파일 크기 : ', convert_size(file_size), 'bytes')
# json 파일을 -> gzip 으로 압축 .gz 파일로 변환해서 저장
start = time.time()
with open(logfile_path,'rb') as f_in:
with gzip.open(gzipfile,'wb') as f_out:
f_out.writelines(f_in)
end = time.time()
print(f"gzip처리 시간 : {end - start:.5f} 초")
print(f"gzip 압축 후 파일 크기 : ", convert_size(os.path.getsize(gzipfile)), 'bytes')
# json 파일을 -> snappy로 압축 .parquet 파일로 변환해서 저장
start = time.time()
with open(logfile_path, 'r', encoding='utf-8') as f:
data = json.load(f)
df = pd.json_normalize(data)
pq.write_table(
pa.Table.from_pandas(df),
pqfile,
compression='snappy'
)
end = time.time()
print(f"snappy처리 시간 : {end - start:.5f} 초")
print(f"snappy 압축 후 파일 크기 : ", convert_size(os.path.getsize(pqfile)), 'bytes')그 결과, 아래와 같이 나왔다.
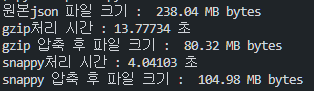
결국 우리는 용량보다는 처리 속도에 더 비중을 두기로 하고 snappy-parquet 페어를 선택하기로 했다.
다시 두 번째 문제 해결
문제를 해결하고 MySQL Workbench에서 직접 쿼리 결과를 json파일로 export하는 방법을 택해, snappy를 이용해 parquet 파일로 변환해주고 수동으로 S3에 업로드 하였다.

import pyarrow as pa
import pyarrow.parquet as pq
import json, pandas as pd
from pathlib import Path
'''
json 파일을 snappy로 압축하여 parquet 파일로 변환하는 코드
'''
BASE_PATH = Path('json 파일이 들어있는 폴더')
pq_dir = BASE_PATH / 'parquet'
pq_dir.mkdir(exist_ok=True)
for logfile_path in BASE_PATH.glob('*.json'):
data = []
with open(logfile_path, 'r', encoding='utf-8') as f:
# 수집단에서 개행문자를 제거하지 않았고, db에서 값을 빼오다보니 null값이 있어서 json.load를 쓸 수 없었다.
decoder = json.JSONDecoder()
buffer = ""
for line in f:
buffer += line.strip()
try:
while buffer:
obj, idx = decoder.raw_decode(buffer)
data.append(obj)
buffer = buffer[idx:].lstrip()
except json.JSONDecodeError:
pass
df = pd.json_normalize(data)
pqfile = pq_dir / (logfile_path.stem + '.parquet')
pq.write_table(
pa.Table.from_pandas(df),
pqfile,
compression='snappy'
)