문제상황
S3로 옮긴 데이터를 aws athena를 이용해 테이블을 생성+파티셔닝을 해야한다.
우선, 테이블을 생성하면서 파티셔닝을 하기로 했다. S3에는 연도/월/일 폴더의 구조로 파일들이 들어가있다.
파티셔닝을 해주러 athena 콘솔로 들어가서 아래와 같이 작성한다.
CREATE EXTERNAL TABLE `channel`(
컬럼들)
PARTITIONED BY (`year` int, `month` int, `day` int)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://{버킷URI}'
TBLPROPERTIES (
'classification'='parquet',
'parquet.compression'='SNAPPY',
'projection.enabled'='true',
'projection.day.digits'='2',
'projection.day.range'='01,31',
'projection.day.type'='integer',
'projection.month.digits'='2',
'projection.month.range'='01,12',
'projection.month.type'='integer',
'projection.year.digits'='4',
'projection.year.range'='2020,2102',
'projection.year.type'='integer',
'storage.location.template' = 's3://{버킷URI}/${year}/${month}/${day}')
문제없이 쿼리는 실행되었고, 아래와 같이 쿼리를 날려 제대로 파티셔닝 되었는지 확인해보았다.
SELECT channel_id
FROM channel
WHERE year=2023 and month=3 and day=12
LIMIT 10;안 나옴🙄
문제 해결
파티셔닝 했다면서 쿼리가 안 먹힌다. 무언가 파일 자체가 잘못 된 것 같다는 판단이 들었다.
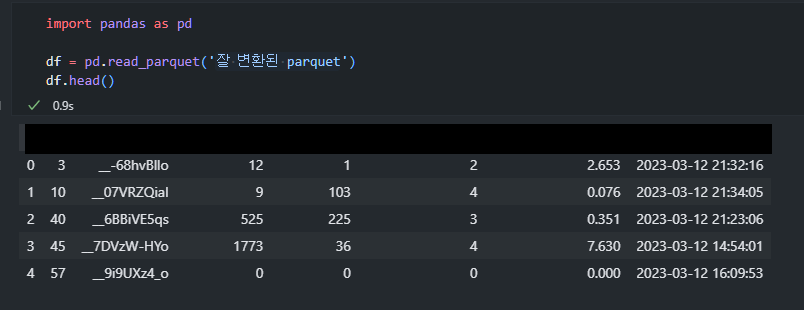
파티셔닝이 자꾸 안 돼서 결국 parquet 파일을 열어보니 수동으로 변환했던 json 파일들은 아래와 같이 깔끔하게 변환이 되었는데
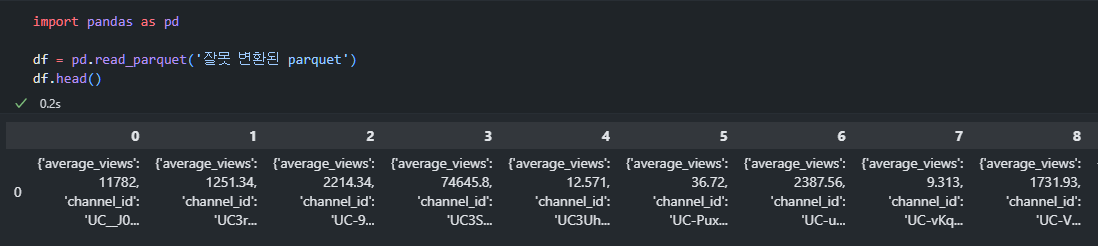
어디서 긁어온 코드로 변환한 파일들은 다 아래 사진처럼 되어있더라
그래서 결국 다시 parquet로 만들어주고 athena에서 파티셔닝을 진행했다.
import pyarrow as pa
import pyarrow.parquet as pq
import json, pandas as pd
from pathlib import Path
import time
def json_to_pq(folder, date) :
'''
json 파일을 snappy로 압축하여 parquet 파일로 변환하는 코드
'''
BASE_PATH = Path(f'C:/Users/User/{folder}')
logfile_path = BASE_PATH/f'{date}.json'
pqfile = BASE_PATH/f'{date}.parquet'
start = time.time()
with open(logfile_path, 'r', encoding='utf-8') as f:
data = json.load(f)
df = pd.json_normalize(data)
pq.write_table(
pa.Table.from_pandas(df),
pqfile,
compression='snappy'
)
end = time.time()
total_time = end-start
return total_time그 결과, 짜잔
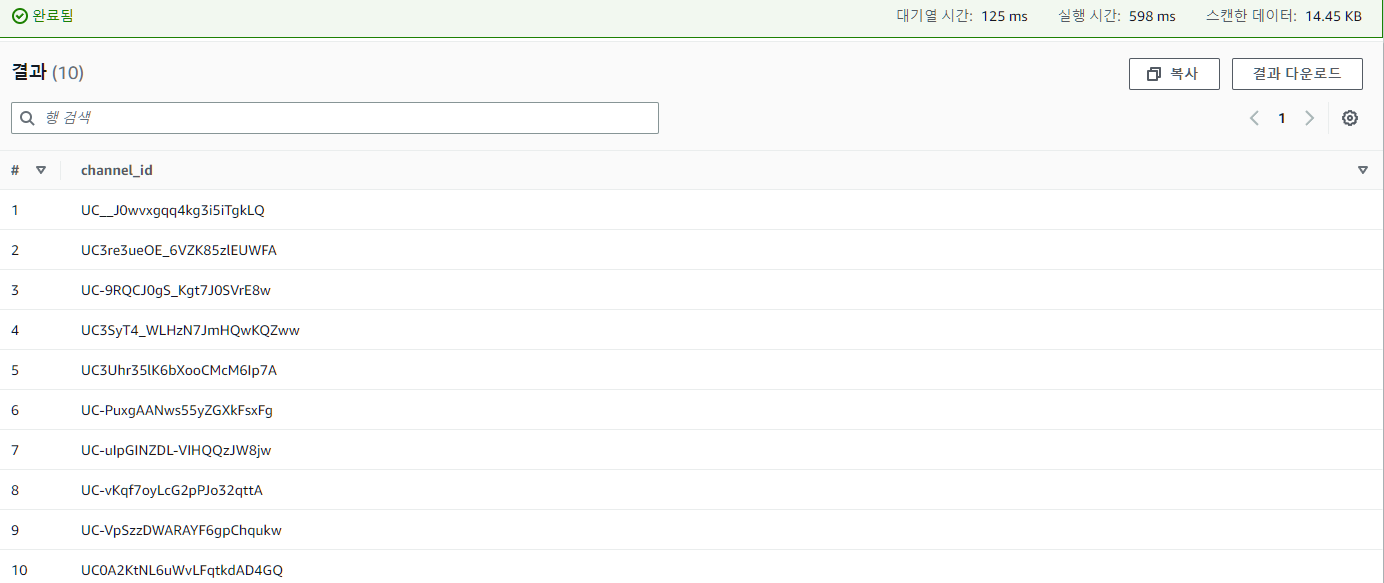
위와 같이 실행시간 598ms, 스캔한 데이터 14.45KB로 쿼리가 실행되었다. 원래 파일이 254.4KB인 것에 비하면 상당히 깔쌈한 것을 알 수 있었다.
남의 코드 함부로 가져다 쓰지 말자. 가져다 쓰고는 꼭 결과물을 확인하자.

완료주의