
Project_디붕
Day2
첫날에 가장 걱정했던 크롤링을 해결했으니, 이제 전체적인 구상에 들어갔다.
1) 자료구조
html / javascript : items(아이템 정보), user_data(유저 개인 영지 정보)
<script>
// 테이블의 순서대로 네이밍, 0:고대 유물 ~ 12:최상급 오레하
let items = new Array(13)
for (let i = 0; i < items.length; i++) {
items[i] = {}
}
// items[i] = {
// 'name': name,
// 'price': price,
// 'image': image
// }
// 작업하기 편하게, 종류도 5개 밖에 안되서 이대로 썼다.
// 0: 닉네임, 1: 에너지 회복량, 2: 에너지 소모 감소
// 3: 골드 소모 감소, 4: 소요시간 감소
// 아래 수치는 초기화.
let user_data = new Array(5)
user_data[0] = ''
user_data[1] = 100
for (let i = 2; i < user_data.length; i++) {
user_data[i] = 0
}
$(document).ready(function () {
set_temp()
set_price()
})
// 그날 평균 가격으로, 아이템 테이블을 생성
function set_price() {...}
// 유저 영지 정보 저장
function save_user() {...}
// 유저 영지 정보 로드
function load_user() {...}
// 실시간 최저가 크롤링
function crawling()
// 임의의 아이템 가격 설정
function modify()
</script>Python, mongoDB :
itemDB (아이템 정보) : 0 ~ 12,
update_date : update 날짜와 오늘 날짜가 다르면 크롤링.
user_data (영지 정보) : 0 ~ 4
# 전날 평균 가격을 긁어 오는 함수
def today_price():...
# 검색했을 때 데이터가 보기 좋게 정렬되어 있지 않다.
# 이 함수를 통해 순서를 바로잡았다.
def transform(num):...2) 흐름
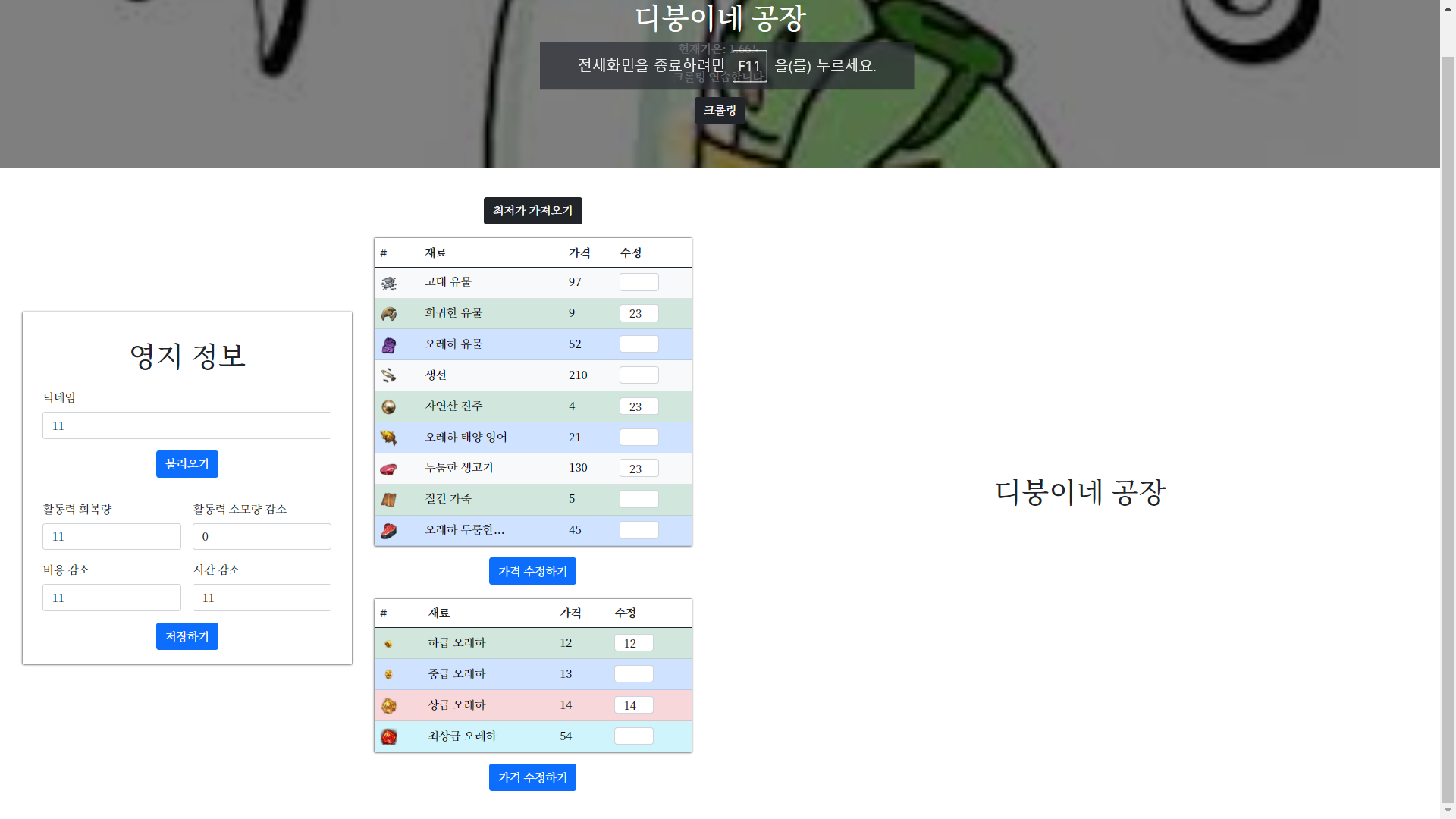
1] 사이트 켜짐 -> function set_price()
get방식으로 아이템 데이터를 받아오는 함수.
db에 저장된 update_date가 오늘과 맞는지 확인
-> true: DB 긁어옴, false: 크롤링 후 DB 저장 및 긁어옴.
2] 영지 정보 -> function save_user(), function load_user()
save_user()
input 안의 값을 통해 유저 정보를 받아와 저장.
input 안의 데이터 형식에 제약을 걸었음. (typeof, range)
같은 닉네임에 저장하면 updateload_user()
닉네임만 입력하면 나머지 input 안에 데이터를 불러오는 함수.
3] 최저가 크롤링 -> function crawling()
set_price() 에서 아이템 정보를 전체적으로 가져오는 것과 달리
crawling()은 가격 정보만 가져온다.
그리고 전일 평균 가격이 아닌 실시간 최저가격을 가져온다.
4] 임의의 가격 수정 -> function modify()
허수로 들어온 최저가를 임의로 조정할 수 있도록 수정할 수 있게 하였다. input 안에 입력한 데이터가 아이템의 가격 변수 안으로 들어가며, 시각적으로도 보이게 된다.
오늘은 전체적인 구상 및 왼쪽 화면에서의 기능들 중 일부를 구현해 보았다.
3) 문제 상황
전체적으로 구상에 힘썼고, 손이 많이 움직이지는 못했다.
문법적으로도 걸리는 부분이 많고, 회피도 조금 했다.
Daily_Crawling
원래 구상으로는 Schedule 프레임워크를 통해 전일 평균가격은 00:01 에 크롤링을 자동으로 실행하게끔 만들려 했다. 그런데 문제가 많이 발생했다.
몇 시간 썼는데도 진척이 없어 일단은 지금 소개했던 방식인, 그날 첫 방문객이 크롤링을 도와주게 될 예정이다.
슬프게도 하루 첫 방문객은 크롤링 하는 5초 정도의 delay가 생길 예정이다.
Json data
Ajax를 통해 data를 주고 받는데, Json 형식이 너무 힘들었다.
그냥 힘들었다.
