
백엔드 개발의 핵심은 DB와의 통신이라고 생각합니다
그런데 그 DB가 죽어버린다면....???
제대로된 서비스를 제공할 수 없겠죠...

오늘은 다양한 DB 플랫폼에서 이런 사태를 막기 위해서 어떻게 대비하고 있는지 알아보겠습니다!!
MySQL
MySQL(마이에스큐엘, /maɪ ˌɛskjuːˈɛl/)은 세계에서 가장 많이 쓰이는) 오픈 소스의 관계형 데이터베이스 관리 시스템(RDBMS)이다
MySQL은 가장 많이 사용되는 DB 엔진 중 하나입니다.
보통은 MySQL을 사용할 때, 메인 서버 하나만 올리고 사용을 하죠
서버 하나에만 프로젝트를 연결 시켜 놓고, 해당 서버로 읽기/쓰기 작업을 모두 수행하죠
하지만 이렇게 되면 읽기와 쓰기를 하나의 서버에서 처리해야 해서 효율이 떨어지고, 메인 서버가 모종의 이유를 죽어버린다면....
당장 서비스를 할 수 없겠죠...
그럼 이 문제를 어떻게 해결할 수 있을까요??
Replication
바로 복제(Replication)을 통해서 달성할 수 있습니다!!
Replication은 말 그대로 원본 DB를 복제한 복제본을 이용하는 방식입니다.
MySQL은 복제 기능을 통해서 원본 DB와 동일한 데이터의 서브 DB 서버를 구성할 수 있는 기능을 제공하고 있습니다.
Master - Slave
여기서 원본 DB를 Master, 복제본을 Slave 라고 하죠.
Master 와 Slave 사이의 복제는 비동기적으로 이루어집니다.
자세한 MySQL Replication 과정은 추후에 다른 게시물로 올리겠습니다.
Benefit
이렇게 MySQL 서버를 다중화 시켜서 얻을 수 있는 장점은 무엇일까요??
1. 부하 분산
첫 번째 이득은 바로 부하 분산입니다.
하나의 DB로 모든 트랜잭션을 처리하면 당연히 해당 DB 서버에는 부하가 많이 가겠죠
여기서 동일한 데이터를 가진 DB 서버가 여러 대가 있다면 부하를 분산시켜서 서버에 부담을 줄여줄 수 있겠죠!!
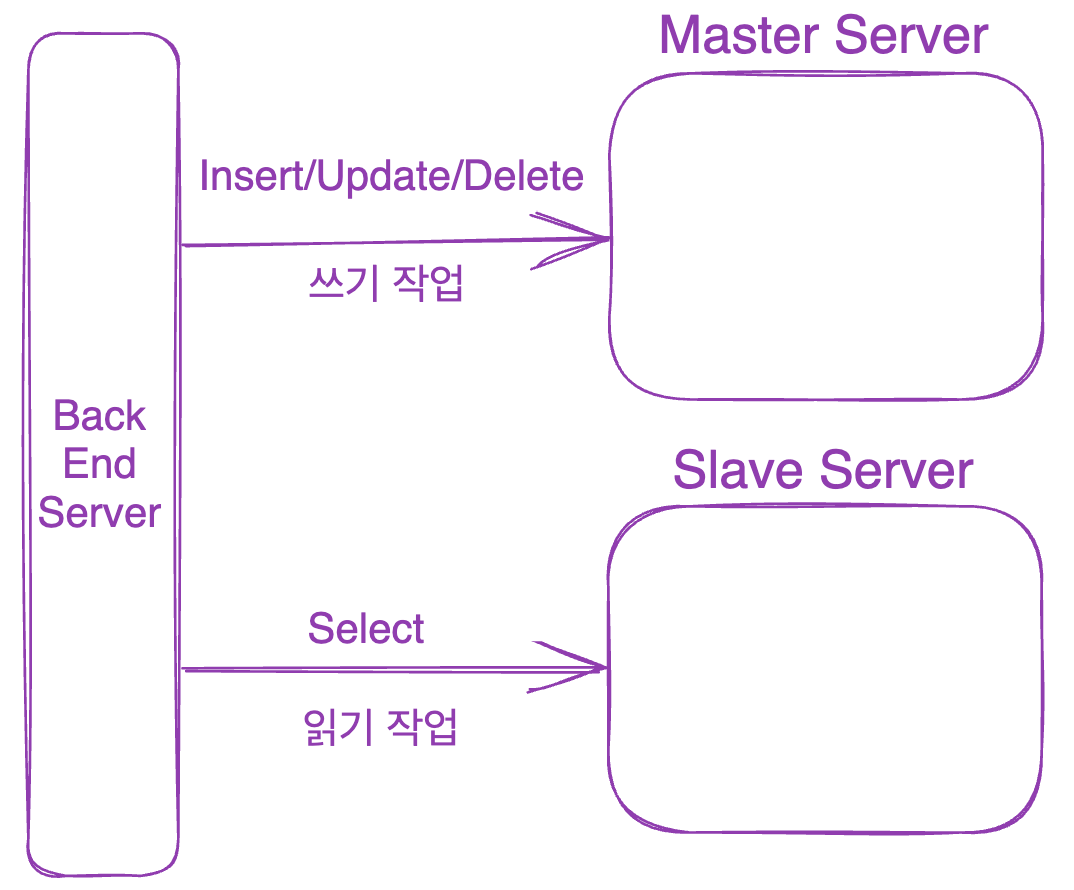
메인 DB에는 수정작업을 계속 수행시키고, 읽기 작업은 레플리카 DB로 수행하는 것이죠
비동기적으로 메인 DB의 정보가 레플리카 DB로 업데이트 되므로 동기적으로 복제하는 것보다 부하가 덜 가도록 부하를 분산시킬 수 있죠
위와 같이 나눈 이유는 보통 DB서버에 가는 요청 중 읽기 작업 즉, SELECT 문이 가장 많이 쓰이기 때문입니다.
2. 백업용
장애는 언제 어디서 갑자기 다가올 지 모릅니다.
우리의 메인 DB 서버도 언제 죽을 지 모르죠...
하지만 레플리카 DB 서버가 존재한다면??
레플리카 DB 서버를 메인 서버로 승격시켜서 사용할 수 있습니다.(MySQL 짱!!)
MongoDB
몽고DB(MongoDB←HUMONGOUS)는 크로스 플랫폼 도큐먼트 지향 데이터베이스 시스템이다. NoSQL 데이터베이스로 분류되는 몽고DB는 JSON과 같은 동적 스키마형 도큐먼트들(몽고DB는 이러한 포맷을 BSON이라 부름)을 선호함에 따라 전통적인 테이블 기반 관계형 데이터베이스 구조의 사용을 삼간다.
NoSQL의 대표 주자인 MongoDB 또한 다양한 배포 형태를 가지고 있습니다.
Standalone
단순히 MongoDB 서버 하나만 사용하는 배포 형태입니다.
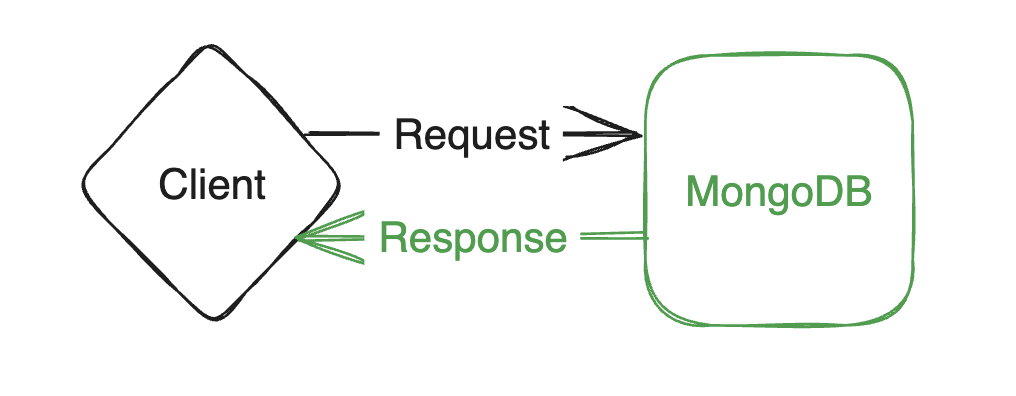
하나의 서버만을 가지고 통신을 하기 때문에 DB 서버가 죽어버리면 서비스가 되지를 않죠
고가용성, 내구성 모두 챙기지 못한 모습입니다.
어떻게 챙길 수 있을까요??
Replica Set
첫 번째 방식은 바로 Replica Set입니다.
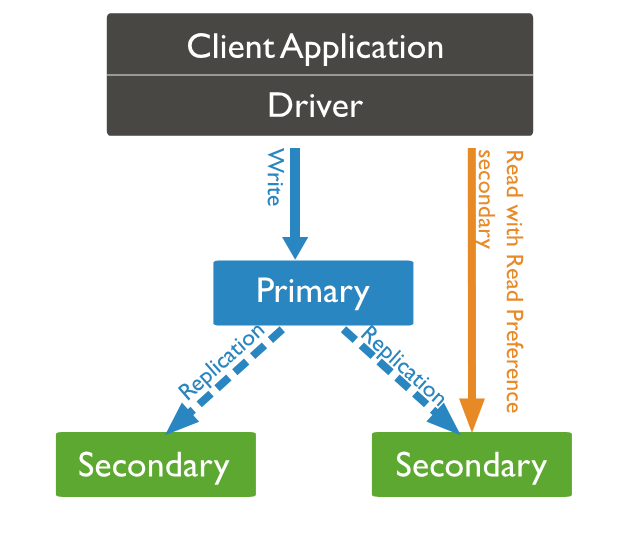
Replica-Set은 여러 개의 복제본을 두는 형태로 고가용성을 획득할 수 있는 배포 형태입니다.
여기서 메인 DB는 Primary 복제 대상은Secondary라고 부릅니다.
Primary는 Read/Write 모두 수행할 수 있습니다.
특히 Replica -Set 내부에서 유일하게 Write 작업을 수행할 수 있죠
그리고 Set 안에 단 1개만 존재합니다.
그에 반해 Secondary는 Read 요청만 수행할 수 있으며
복제를 통해서 Primary와 같은 데이터 셋을 유지할 수 있습니다.
그리고 여러 개가 존재해도 무방하죠
Secondary 진화!
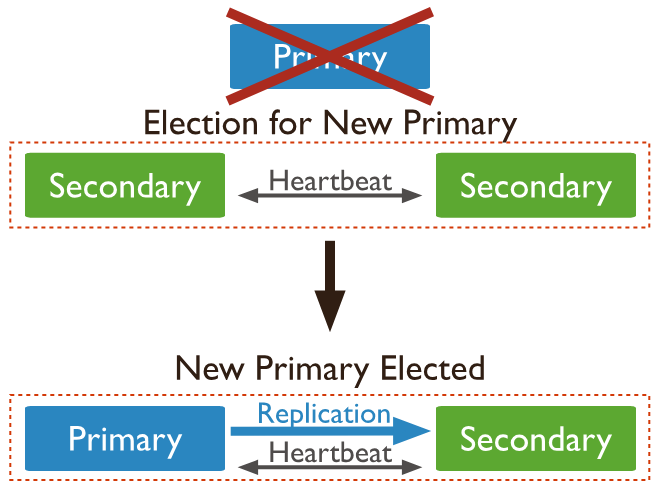
그리고 위 그림과 같이 Primary 가 이용이 불가능할 경우 Secondary 끼리 투표과정을 거쳐서 Secondary 중 하나를 Primary로 승격시켜서 사용할 수 있습니다.
Sharded Cluster
두 번째 방식은 Sharding입니다.
Sharded Cluster는 데이터를 여러 개의 Shard에 나누어 저장을 하는 분산 저장 방식입니다.
어라? 그냥 분산 저장 방식 아니냐고요??
사실 모든 Shard는 Replica Set으로 구성되어 있습니다!!
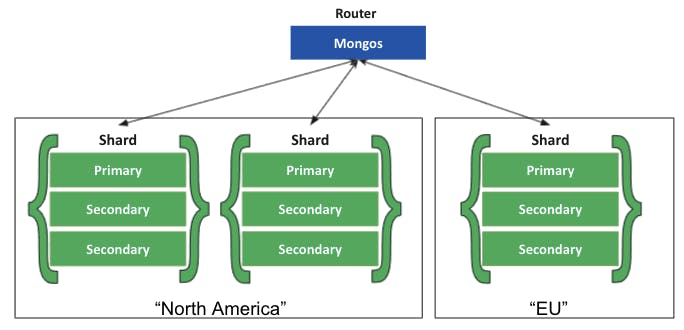
위와 같이 구성되어 있으므로 Replic-Set의 고가용성을 얻을 수 있고, 추가로 Sharding의 특성으로 부하 분산의 효과도 얻을 수 있습니다.
Sharded Cluster가 짱??
그럼 우리는 앞으로 MongoDB를 사용할 때, 모두 Sharded Cluster로 구성해서 사용하면 될까요??
고가용성에다가 Sharding으로 인한 데이터 분산까지 얻어서 대규모 데이터도 보다 더 수월하게 처리하니까요!!
하지만....
Sharded Cluster는 Replica-Set에 비해서 관리가 비교적 어렵고, 쿼리가 느리다는 단점이 있습니다.
그렇기 때문에 관리 경험이 없거나, 대규모 처리가 필요 없는 곳이면 굳이 사용할 필요가 없죠
MongoDB Atlas
마지막으로는 MongoDB의 클라우드 서비스인 MongoDB Atlas 입니다.
MongoDB Atlas는 기본적으로 Replicat-Set 으로 이루어져 있으며
클라우드 사업자, 리전 등을 선택할 수 있고
클라우드 서비스 답게 무료 부터 서비스를 제공하고 있습니다.
그리고 이렇게
다양한 수단을 통해 클라우드와 연결할 수 있습니다.
mongodb compass를 통한 연결 중
연결 후
Redis
레디스(Redis)는 Remote Dictionary Server의 약자로서 "키-값" 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 비관계형 데이터베이스 관리 시스템(DBMS)이다.
레디스를 빠른 속도를 자랑하는 Key-Value 형식의 NoSQL in-memory DB입니다.
주로 캐싱, 분산락 등에 사용되죠
레디스 역시 다양한 형태로 사용자에게 고가용성을 제공해주려 노력하고 있습니다.
Replication
첫 번째 방식은 복제입니다.
지금까지 나왔던 방식들과 매우 유사한 방식입니다.
하나의 마스터를 두고 여러 대의 레플리카가 존재하는 방식이죠
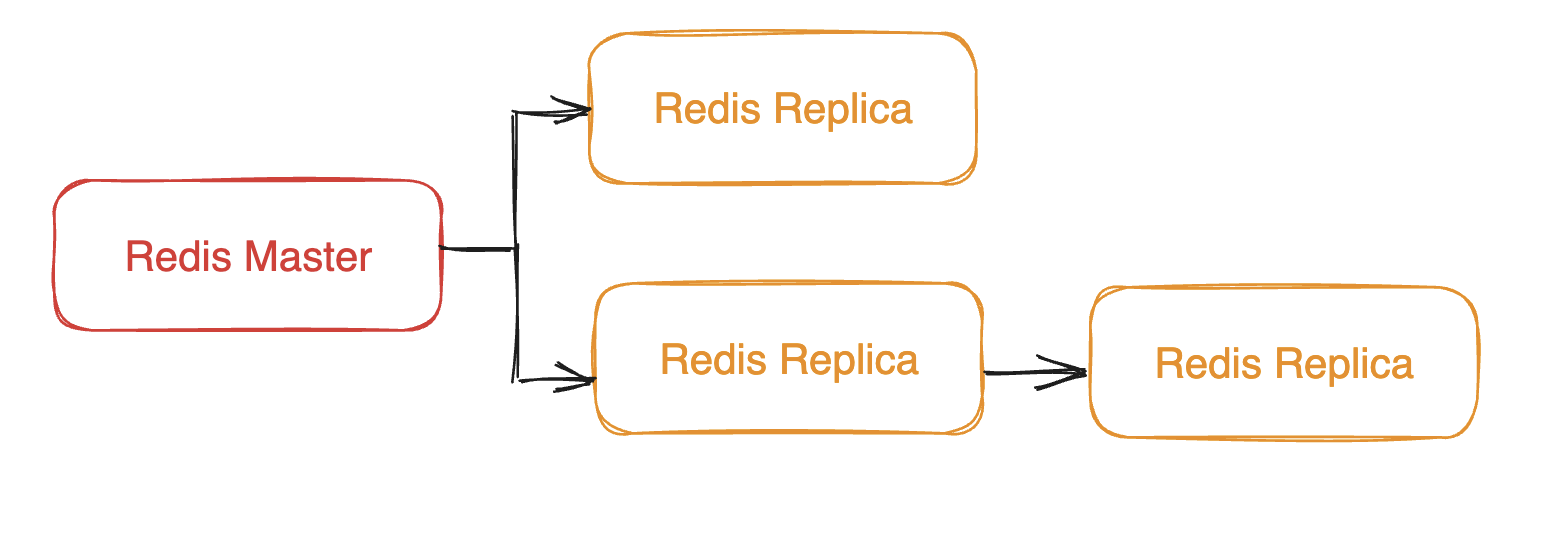
Master Redis가 다운되어서 사용을 못하게 되면, 레플리카 들 중 하나가 Master가 되어서 고가용성을 보장해 줍니다.
레플리카는 역시 Read-Only 노드로 사용이 가능해서 부하 분산 또한 가능합니다.
하지만 이러한 작업은 모두 수동으로 해줘야합니다...
매우 귀찮죠
하지만 Sentinel의 도움이 있다면 위와 같은 작업을 자동으로 수행할 수 있습니다.
Sentinel
Sentinel은 레디스에서 고가용성을 제공하기 위한 장치로서 master-replica구조에서 Replica를 자동으로 Master로 승격시켜 주는 작업을 수행합니다.
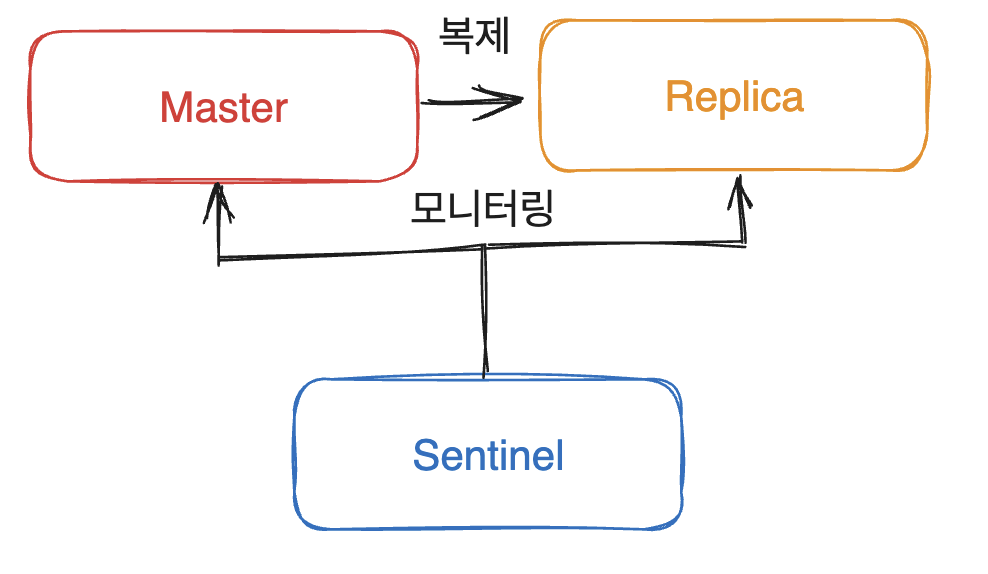
그리고 또한 레디스 각 노드에 대한 모니터링, 알림 그리고 환경 설정 제공자의 역할 또한 수행합니다.
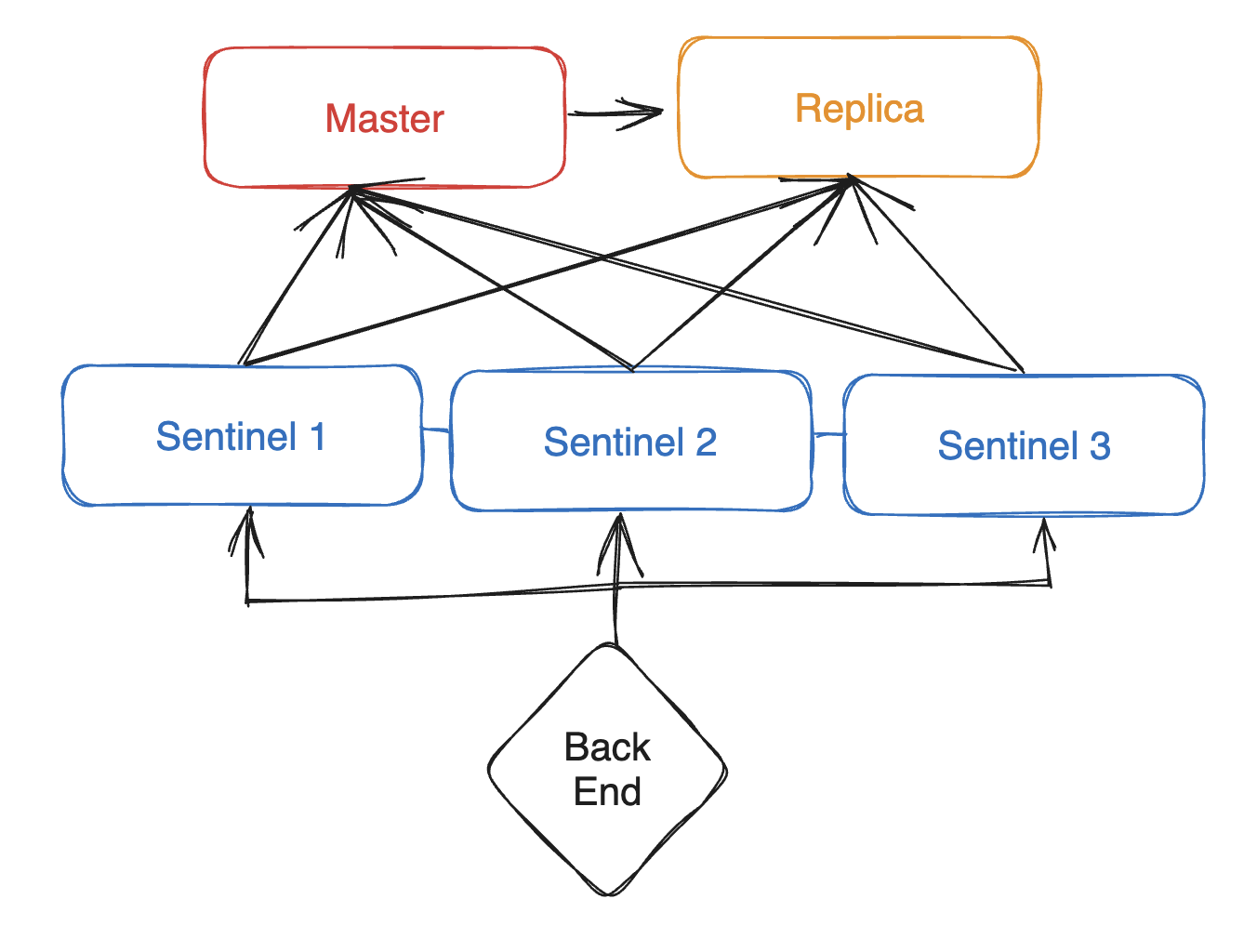
Sentinel은 실제로는 여러 개의 노드로 구성되어 있습니다. 3개 이상으로 구성되죠.
그리고 모든 Sentinel은 서로 연결되어 있으며
각각 Master와 Replica를 각각 모니터링 합니다.
사용자는 Sentinel을 통해서 Redis 에 접근하죠
왜 여러 대가 존재할 까요??
바로 투표를 위해서입니다.
Sentinel중 하나가 실수로 Master가 down 되었다고 판단했다고 가정해봅시다.
만약 sentinel이 하나만 있으면 멀쩡한 상황이지만, 장애 대응 조치가 불필요 하게 이루어 지겠죠!!
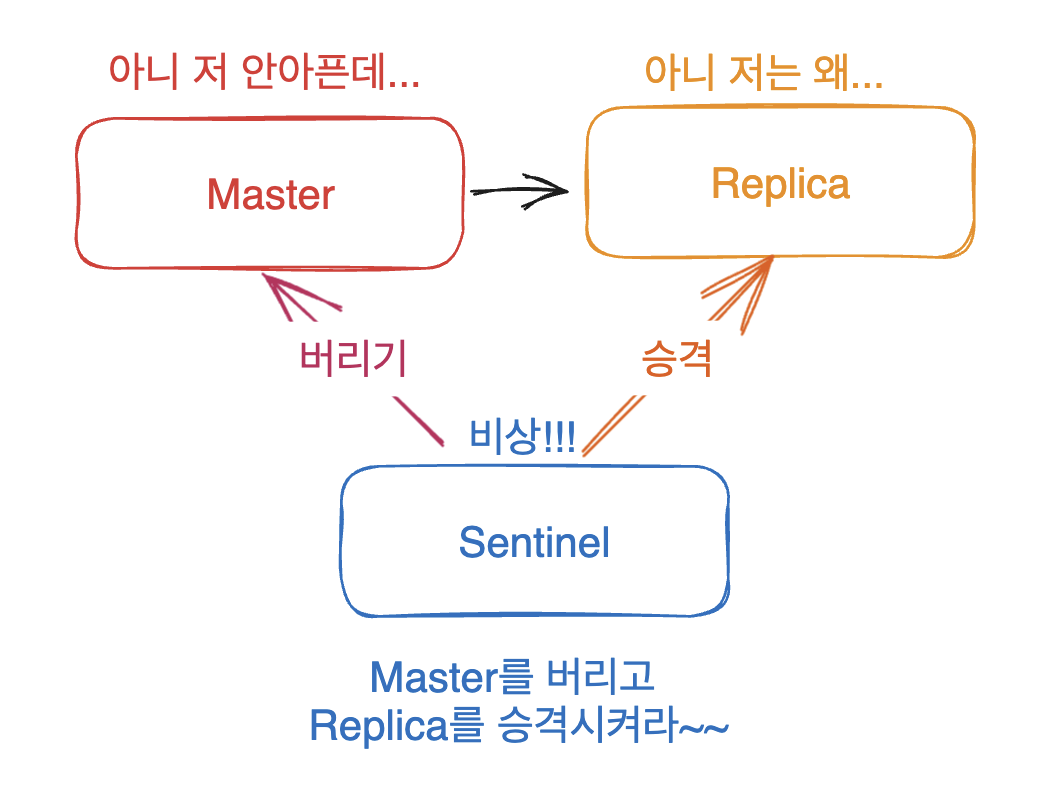
sentinel 오류로 멀쩡한 상황에서 불필요한 작업을 수행해서 가용성이 저하된다.
그렇기 때문에 모든 Sentinel 들이 일정 수 이상으로 Master 가 down 되었다고 판단하면 장애 대응 조치를 하도록 위와 같이 여러 대의 Sentinel들이 필요하게 된 것입니다!!
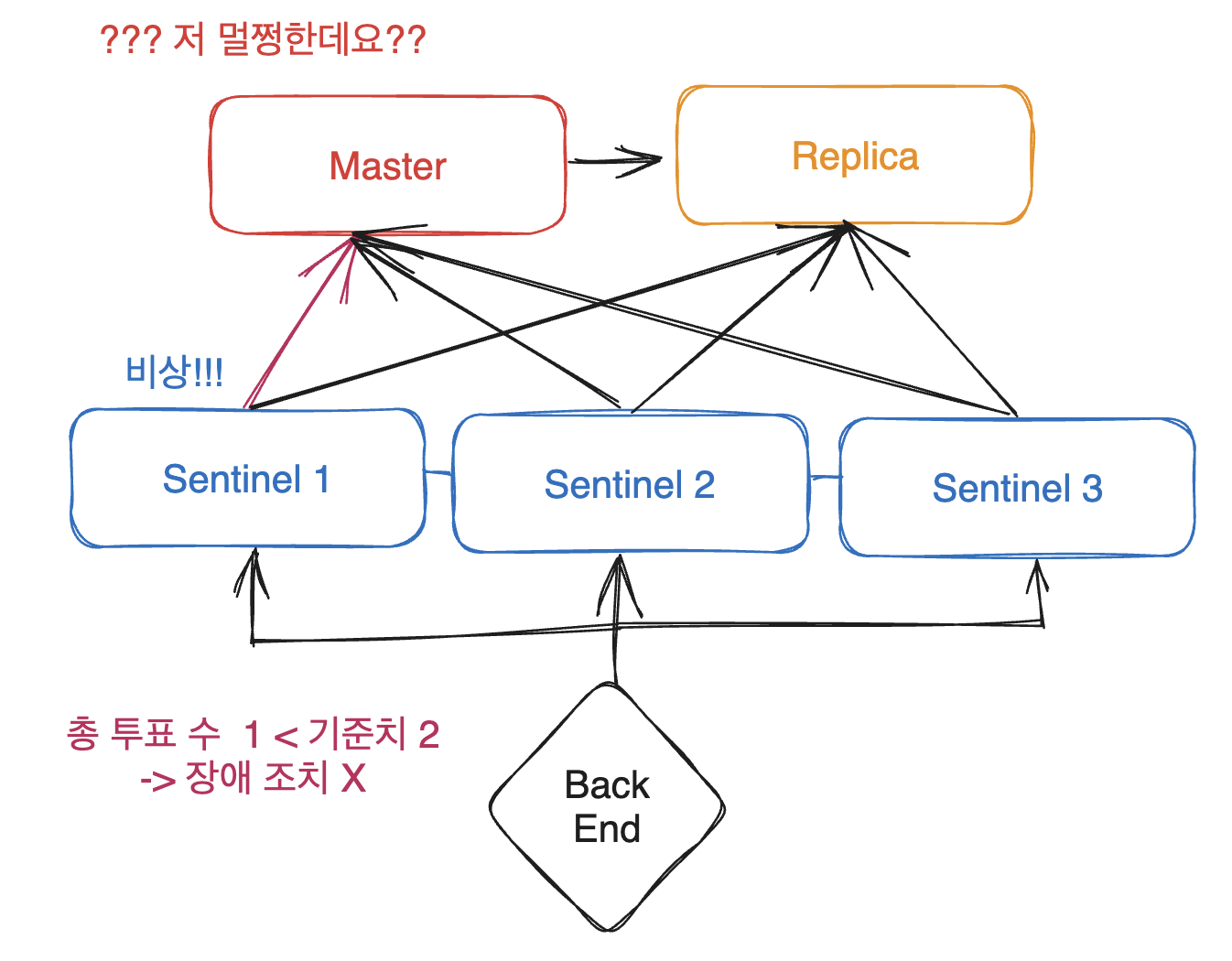
sentinel 하나가 실수해도 장애 조치를 취하지 않는다
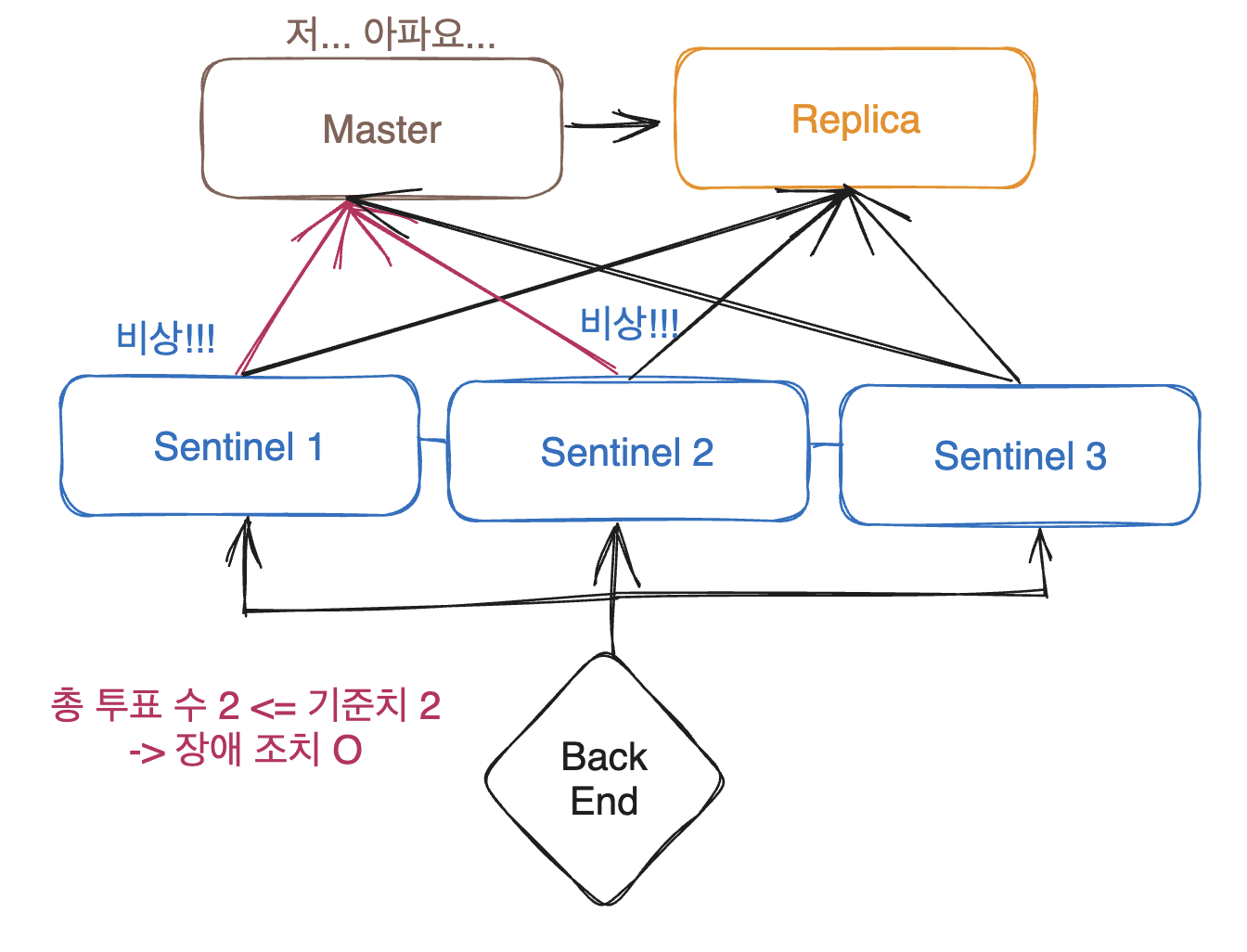
진짜 큰일이 일어났으므로 장애 대응 조치를 취한다
Redis Cluster
또 다른 방법으로 Redis Cluster가 존재합니다.
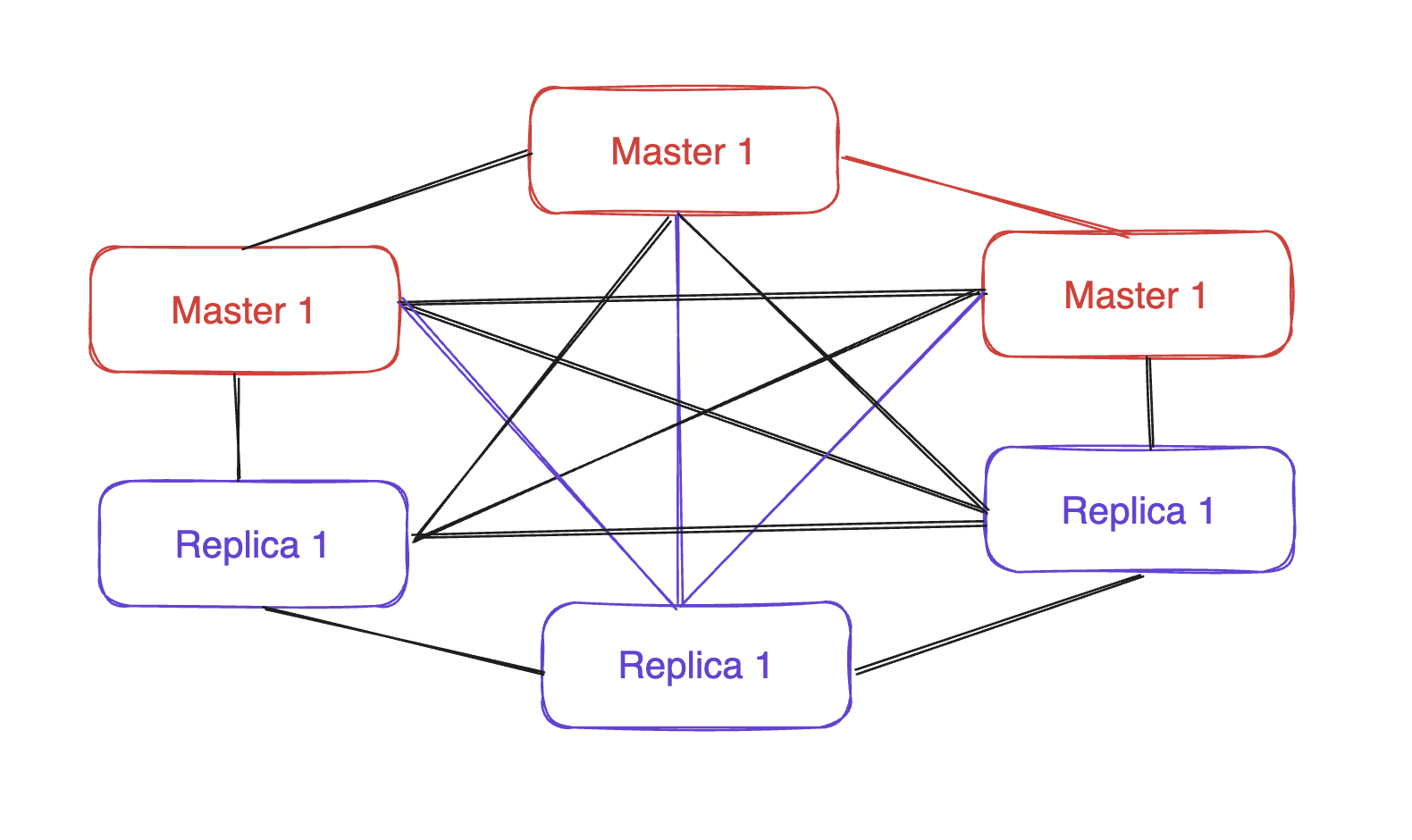
Cluter 내부에는 여러 대의 레디스 서버가 노드로서 존재를 하고 있습니다.
Scale-out이 이론적으로는 무한정 가능하고, 부하 분산에 적합한 구조입니다.
Redis-Cluster 는 모든 노드가 서로서로 연결된 full-mesh 구조로 이루어져 있으며, 서로 간의 통신은 cluster bus을 사용합니다.
또한 모든 마스터가 각각 모든 레플리카에게 모두 데이터를 전송하면 매우 비효율적이겠죠
그래서 gossip-protocal을 사용해서 효율적으로 통신합니다.
A gossip protocol or epidemic protocol is a procedure or process of computer peer-to-peer communication that is based on the way epidemics spread
쉽게 말해 서로의 연결성을 이용하는 것입니다.
소문이 퍼져나가는 모습과 비슷하다고 할 수 있죠.
각 노드는 근처의 몇 개의 노드 끼리만 서로 통신을 해도, 결과적으로 모든 노드와 통신이 가능하다는 방법을 이용해서 노드 간의 통신의 부하를 줄입니다.
Sentinel vs Cluster
지금까지 나온 두 방식이 뭔가 유사해 보이면서 뭔가 달라 보이는데요...
두 방식의 차이점을 정리하면 다음과 같습니다.
- 클러스터는 Sharding을 제공한다 -> 분산처리가 가능하다
- 클러스터는 장애 자동 조치를 위한 Sentinel이 필요가 없다
- 클러스터에서는 multi-key operation의 사용이 제한된다.
- Sentinel은 구조가 비교적 단순하기 때문에 소규모 시스템에서 고가용성이 필요할 때 사용한다.
Amazon RDS

RDS는 AWS에서 제공하는 관계형 데이터베이스 서비스(Relational Database Service) 입니다.
그리고 관리형 서비스입니다.
즉, AWS가 관리하는 클라우드 서버에 사용자가 DB를 생성하면 해당 DB 서버의 자원 관리는 AWS가 다 알아서 하는 서비스죠.
RDS에서 사용할 수 있는 DB 엔진은 다음과 같습니다.
MySQLPostgreSQLMariaDBOracleMicrosoft SQL ServerAmazon Aurora
만약 여러 분이 DB로 위에 있는 엔진을 사용하고 있었다면 쉽게 온프레미스에서 클라우드로 마이그레이션 할 수 있죠!!!
"근데 EC2에 DB 설치해서 DB서버로 사용하도 되지 않나요?? 굳이 RDS와 같은 독립적인 서비스가 필요한가요??"
네!!
당연히 사용할 가치가 있습니다.
Amazon RDS는 RDB 특화 클라우드 서비스로 여러 장점들을 제공합니다.
EC2 vs RDS
1. RDS는 관리형 서비스이다.
사용자가 모든 것을 관리하는 EC2 와는 다르게 RDS는 관리형 서비스입니다.
AWS가 자동으로 DB서버의 용량을 확보하고, OS 패치와 같은 작업을 수행해주죠!!
2. 지속적으로 백업이 자동으로 생성된다
RDS는 기본적으로 백업이 생성됩니다. 그렇기 때문에 서버가 다운 되더라도 복원을 할 수 있으며,
특정 시점의 DB상태를 언제든지 확인할 수 있습니다.
3. 모니터링 가능
AWS 에서 제공하는 기본적인 모니터링 기능 뿐 아니라 CloudWatch, SQS 등의 다른 서비스들과 연계해서 활용할 수 있습니다.
4. 읽기 전용 복제본 제공
여기에서도 복제본 즉, 레플리카를 제공해줍니다.
이 레플리카들은 읽기 전용으로 메인 RDS에 가해지는 부하를 분산시키는데 활용할 수 있습니다.
5. 다중 AZ 활용으로 고가용성 확보 가능
RDS 인스턴스 중 복제본을 여러 가용 영역으로 분산시킴으로써 한 AZ가 사용 불능이 되더라도 DB 사용에는 차질 없게 서비스하는게 가능합니다.
6. 언제든지 확장 가능
클라우드 서비스의 최대 장점인 유연함이 발휘되는 부분입니다.
언제든지 Scale-out, Scale-up 이 가능하죠!!(돈만 내면야...)
단!!! RDS 인스턴스는 EC2 인스턴스와는 다르게 ssh 로는 접근할 수 없습니다. 유일한 단점이네요
RDS Storage Auto Scaling
RDS는 수동으로도 용량을 원하는대로 조절할 수 있지만, 자동으로 용량을 조정해주는 서비스가 존재합니다.
Storeage Auto Scaling을 활용하면 RDS의 용량을 자동으로 늘려주죠
여기서, 늘어나는 용량은 사용자가 제한할 수 있습니다.
무한대로 늘어나면... 안되니깐요..!!!
용량을 늘리는 조건은 아래와 같습니다
- 남은 공간이 10% 이하가 되면
용량 부족 상태라고 판단함 용량 부족 상태가 5분 이상 지속될 경우- 지난 수정으로 부터 6시간 이상 지났을 경우
그리고 다음과 같은 DB 엔진에서 제공합니다
MySQLPostgreSQLMariaDBOracleMicrosoft SQL Server
Read-Only Replica
읽기 전용 복제본은 RDS가 고가용성을 유지하는 방법입니다.
RDS 인스턴스는 최대 15개의 읽기 전용 복제본을 생성할 수 있습니다.
그리고 이들은
- 동일한 AZ
- 동일 리전 내 여러 AZ
- 여러 리전
등에 거쳐서 생성됩니다.
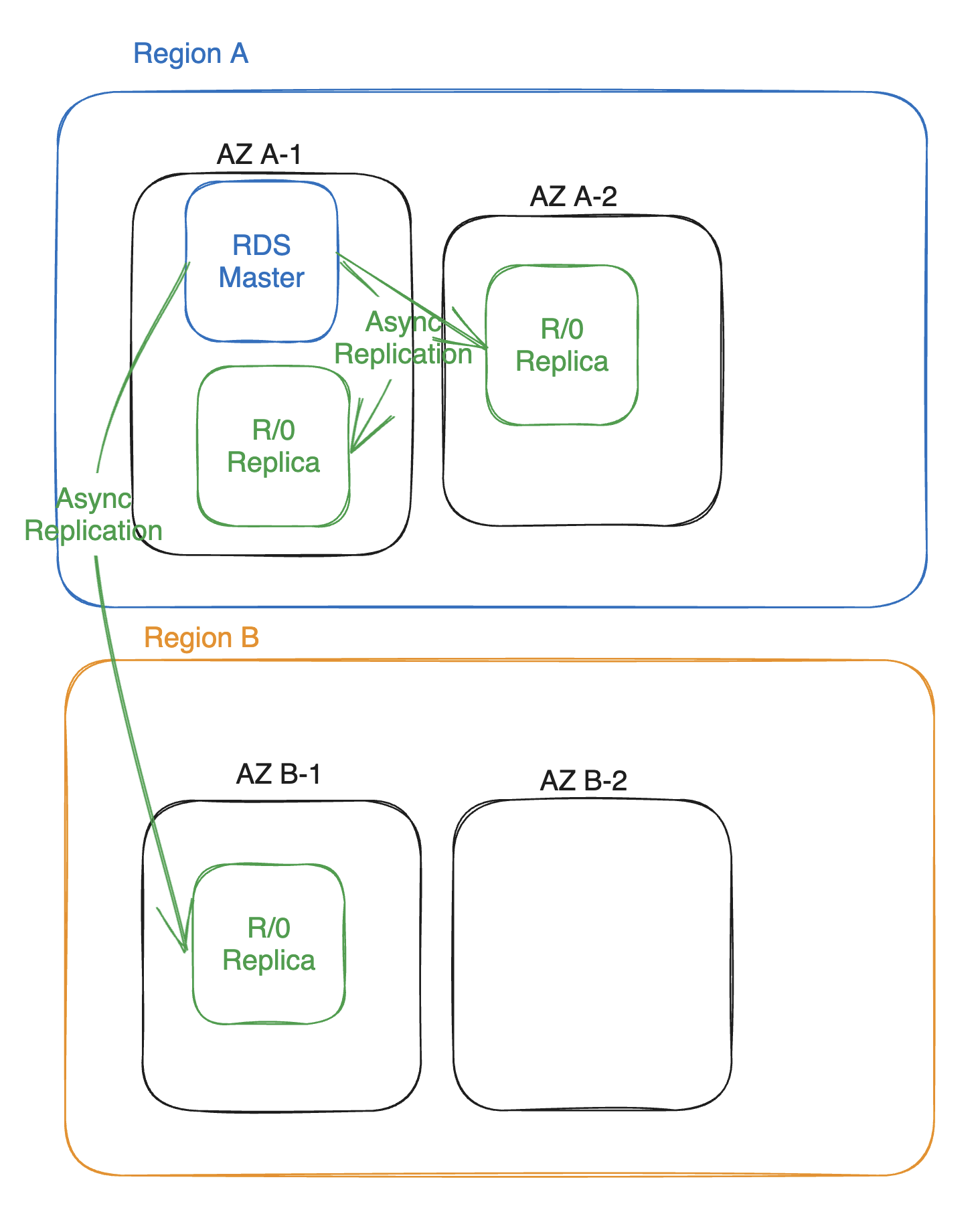
비동기 복제
읽기 전용 복제본은 비동기적으로 원본 RDS 인스턴스로부터 데이터를 복제해옵니다.
RDS 인스턴스로 승격
읽기 전용 복제본이지만, 역시 자체 RDS 인스턴스로 사용이 가능합니다.
승격시켜서 자체 RDS 인스턴스로 사용할 수 있죠
이렇게 되면 기존의 읽기 전용 복제본의 주기에서 벗어나며 자체 생애 주기를 가지게 됩니다.
Multi-AZ
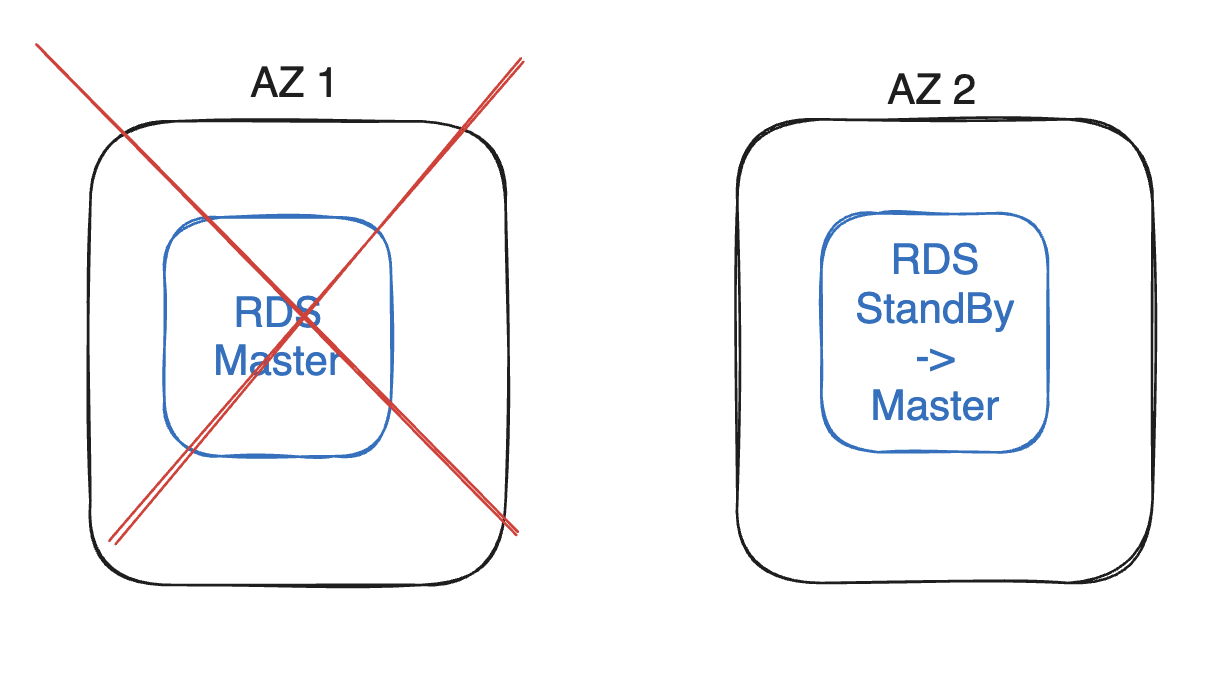
RDS 인스턴스는 또한 재해에 대응해서 다중 AZ기능도 제공합니다.
바로 RDS 인스턴스가 위치해있는 곳과 다른 AZ에 대기 인스턴스(Stand by Instace)를 생성해 놓습니다.
동기 복제
읽기 전용 복제본과는 다르게 대기 인스턴스는 메인 RDS 인스턴스와 동기식으로 복제됩니다.
놓치는 정보가 없다는 뜻이죠
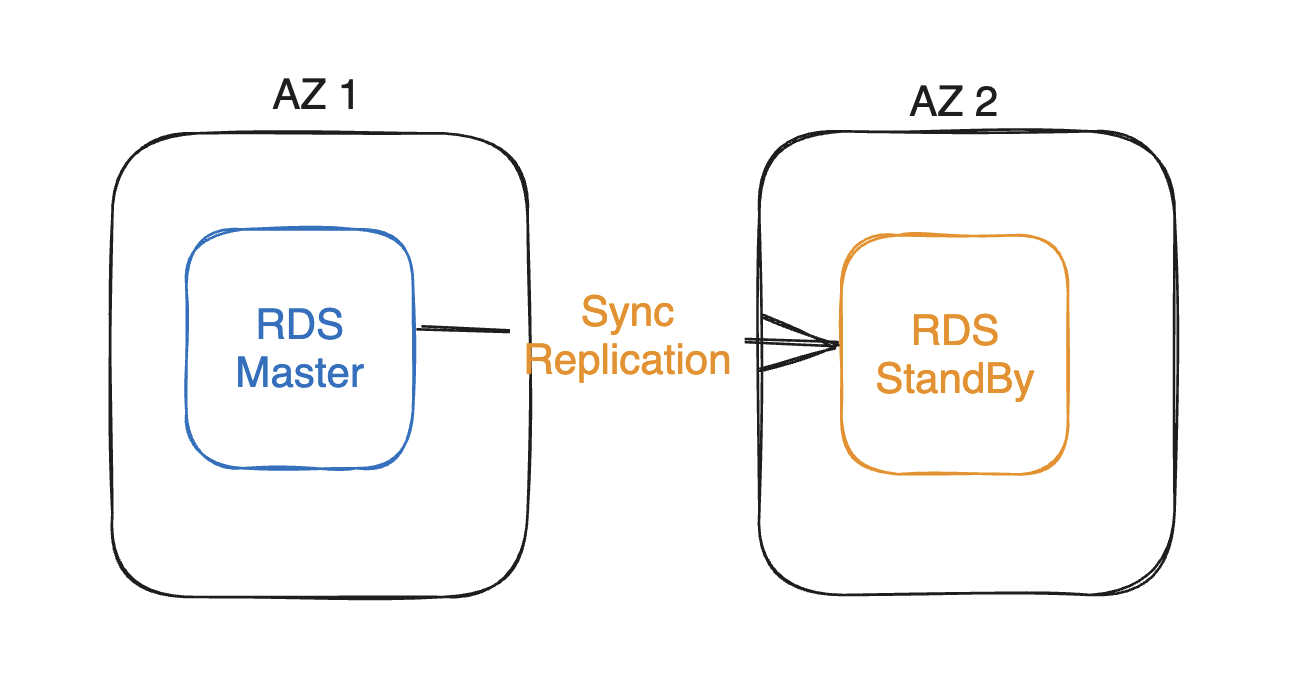
자동 복구
만약 Master RDS 인스턴스가 위치해 있는 AZ에 문제가 생겨서 Master RDS를 사용 못하게 된다면, 대기 인스턴스는 자동으로 본인을 Master로 승격시킵니다.
사용자는 아무것도 안해도 되죠
Amazon Aurora

Amazon Aurora(Aurora)는 MySQL 및 PostgreSQL과 호환되는 완전 관리형 관계형 데이터베이스 엔진입니다
Amazon Aurora는 클라우드 환경에 특화된 DB로서 속도가 매우 빠른 것이 특징입니다(MySQL 은 최대 5배, PostgreSQL은 최대 3배)
그리고 기존의 다른 RDS인스턴스와는 다른 특징들이 몇 가지 더 있습니다.
Read-Only Replica
역시 읽기 전용 복제본이 사용 가능합니다.
여기서 다른 DB와 다른 점음 최대 15개가 사용가능하다는 점이죠
MySQL은 최대 5개만 가능합니다
부하 분산에 매우 좋죠
Aurora 고가용성
Amazon Aurora는 데이터를 특이하게 저장합니다.
동일한 데이터를 3개의 AZ에 걸쳐서 6개의 복제본을 저장하죠
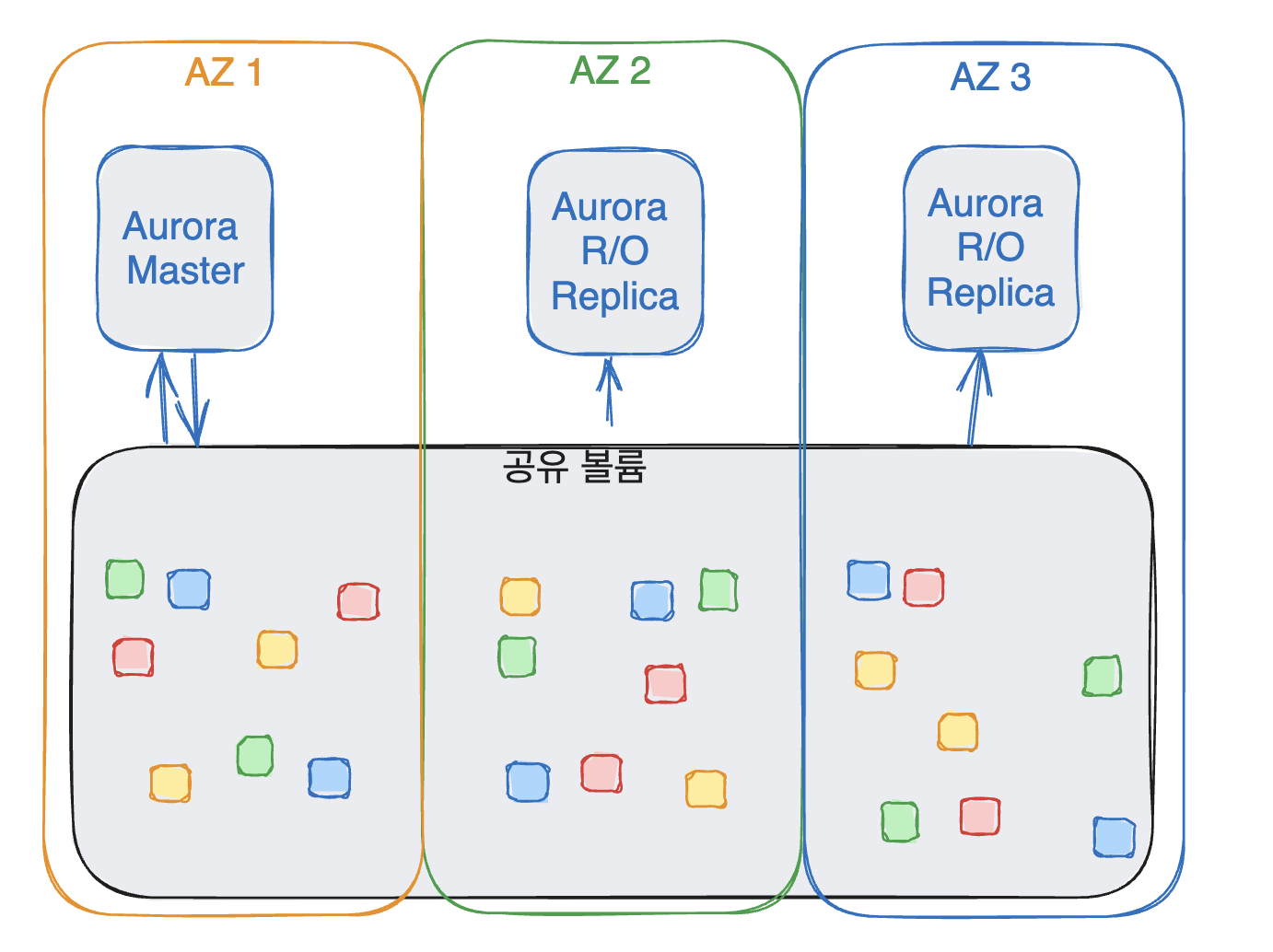
데이터를 쓰기 위해서는 6개 중 4개의 복제본만 있어도 되고,
데이터를 읽기 위해서는 6개 중 3개만 존재해도 읽을 수 있습니다.
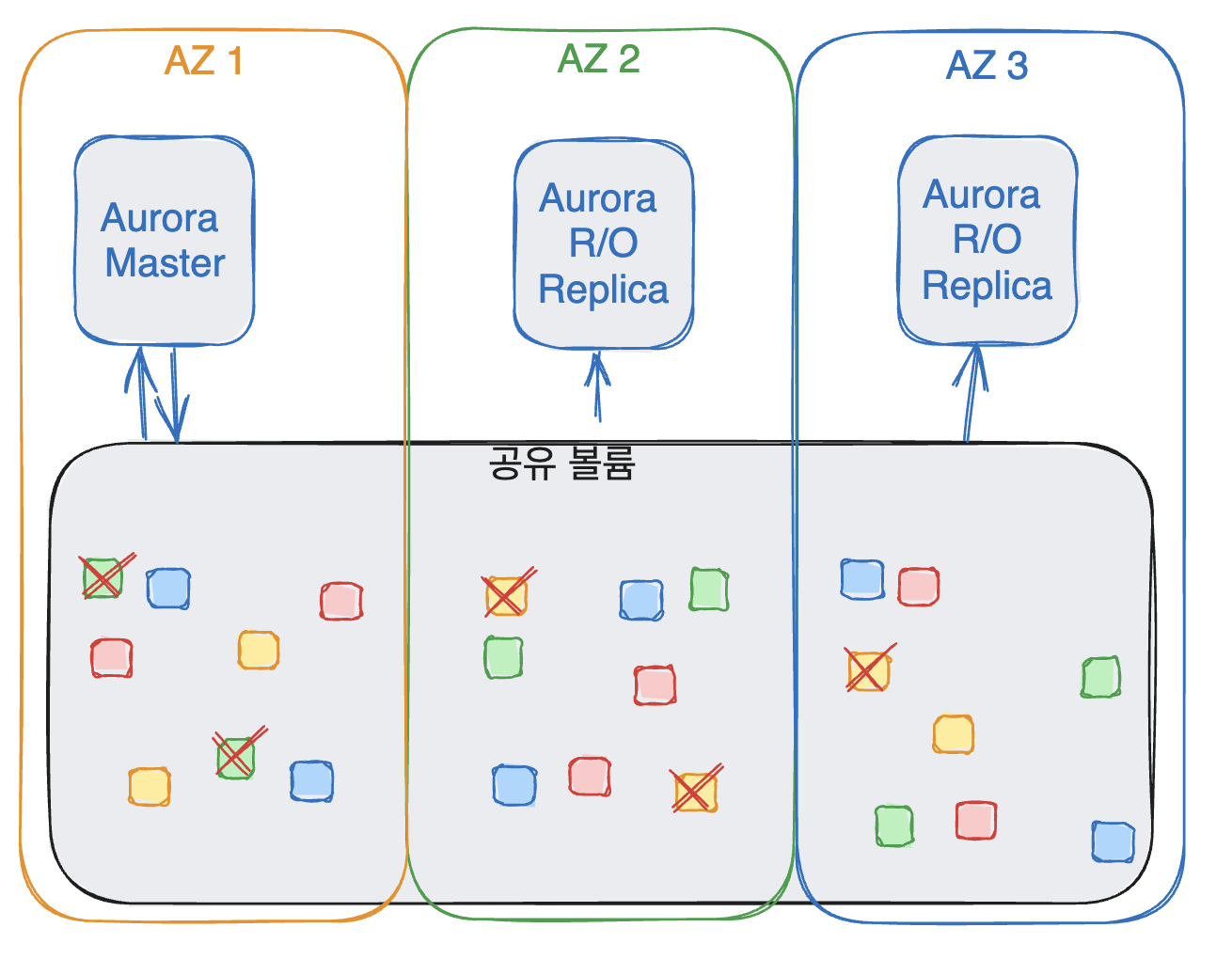
4개의 사본이 남아있으므로 초록색 데이터는 쓰기가 가능함
3개의 사본이 남아있으므로 노란색 데이터는 읽기가 가능함
그리고 일부 데이터가 손상되었을 경우, 클라우드의 저 뒷편에서 P2P 복제를 통해서 자가 복구를 진행합니다.
그리고 또한 단일 볼륨이 아니라 수 백개의 볼륨을 사용합니다.
하지만 논리적으로는 하나의 볼륨처럼 사용되기 때문에 사용자는 불편함을 느끼지 않습니다.
- 그리고 위 그림에서 공유 볼륨이 논리적 볼륨입니다!!
Cross - Region replication
Amazon Aurora는 다른 RDS 인스턴스들과는 다르게 복제본들의 리전간 복제가 가능합니다.
읽기 전용 복제본들이 다른 리전으로 쉽게 전달할 수 있기 때문에 가용성 측면에서 관리하는데 매우 용이하죠
Cluster
Amazon Aurora 의 Master 인스턴스와 레플리카 인스턴스들의 집합을 Cluster라고 합니다.
역시 Master 에서만 쓰기 작업이 가능하죠
그리고 Master 인스턴스가 만약 고장이 나면, 30초 이내로 장애 조치가 이루어 집니다.
참고
AWS Certified Solutions Architect Associate 시험합격!
백엔드 개발자를 위한 한 번에 끝내는 대용량 데이터 & 트래픽 처리 초격차 패키지 Online.
