
Kafka?
Apache Kafka는 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼입니다. 여러 소스에서 데이터 스트림을 처리하고 여러 사용자에게 전달하도록 설계되었습니다. 간단히 말해 A지점에서 B지점까지 이동하는 것뿐만 아니라 A지점에서 Z지점을 비롯해 필요한 모든 곳에서 대규모 데이터를 동시에 이동할 수 있습니다.
저는 카프카가 아주 잘 만들어진메세지 큐 라고 생각합니다!
기존의 메세지큐가 프로세스간의 데이터를 전송하는 파이프라인이라면,
카프카는 프로듀서와 컨슈머, 마이크로서비스에서라면 서비스간의 메세지를 전송하는데 사용되는 라이브러리입니다.
카프카 중요 개념
Topic
카프카에서 메세지를 전송하는 스트림의 이름을 토픽이라고 합니다.
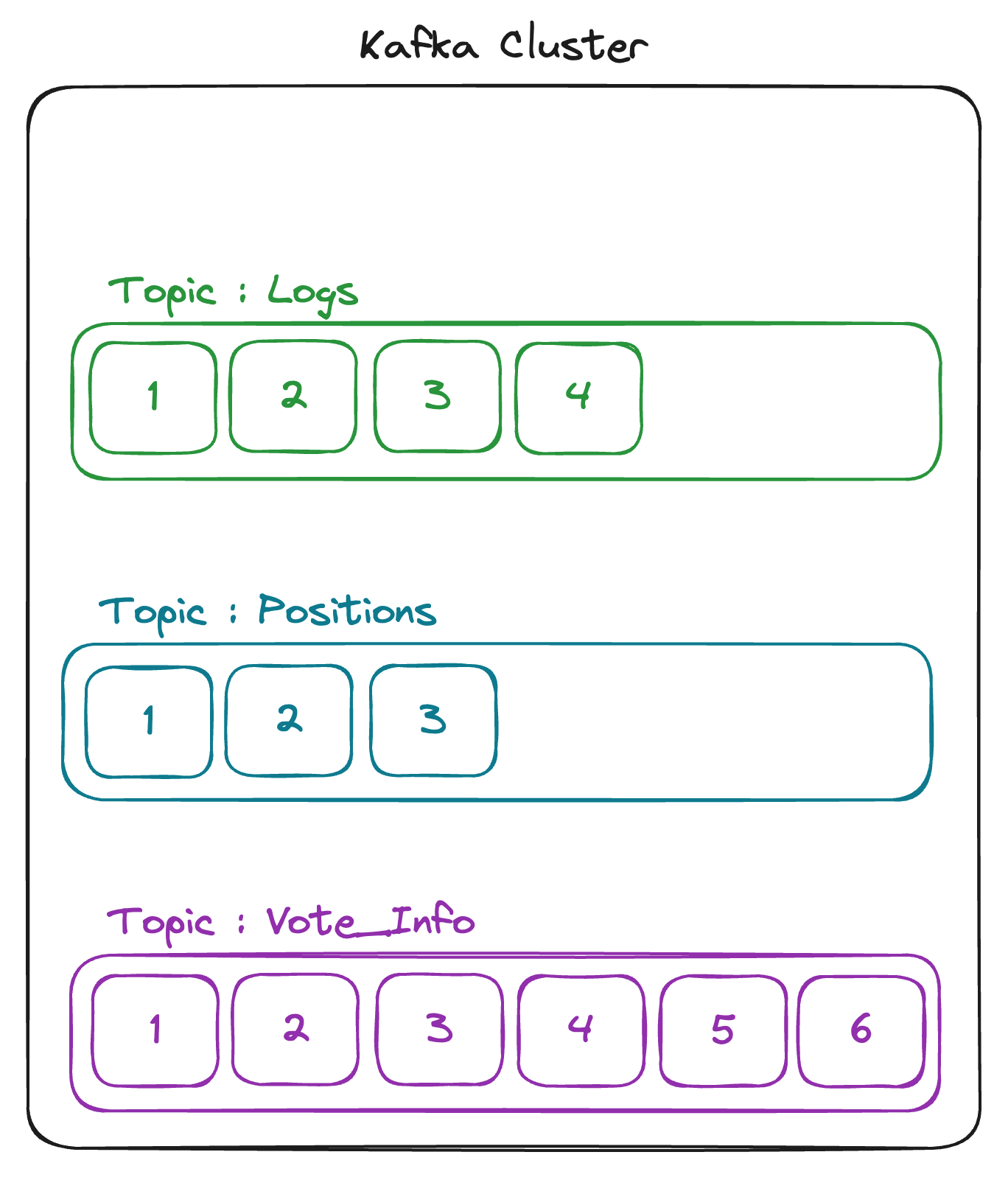
Partition
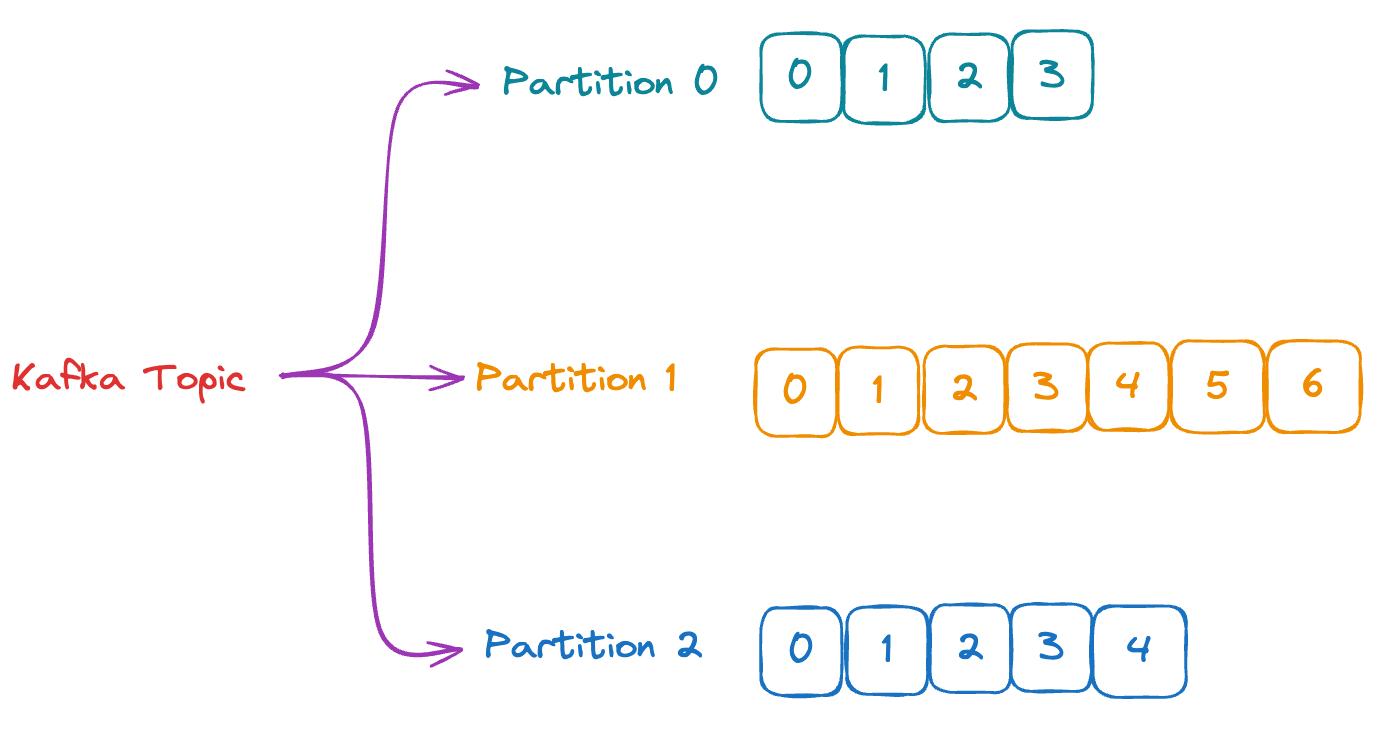
토픽을 내부를 여러 개로 분할한 것으로 원하는 만큼 설정할 수 있습니다.
하나의 토픽의 내부에는 여러개의 파티션으로 나뉘어서 메세지가 전송됩니다.
각 파티션으로 들어가는 조건은 메세지의 key 부분에 들어있는 내용을 바탕으로 결정됩니다.
만약 아무런 설정을 하지 않고 보낸다면, Round-Robin으로 모든 파티션에 골고루 나뉘어서 전송됩니다.
Producer
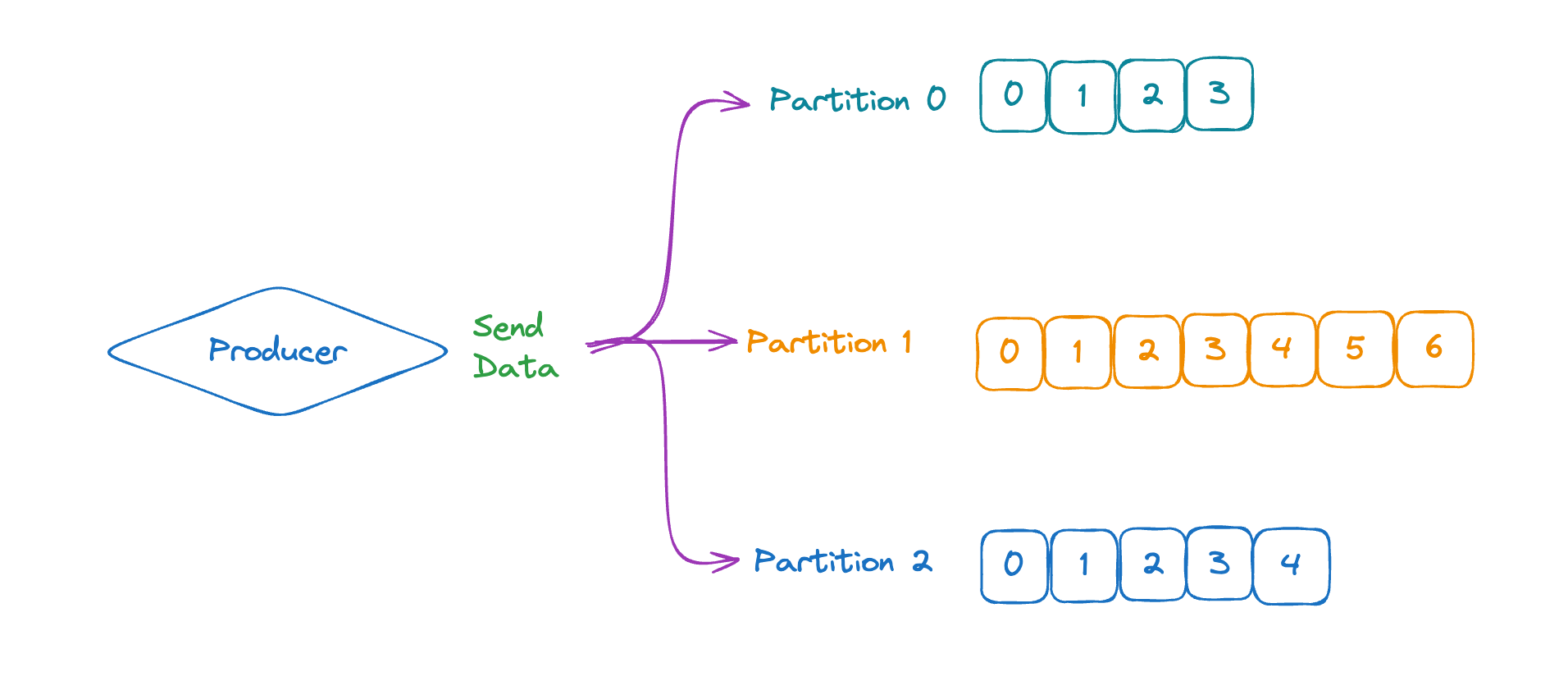
카프카에서 메세지를 전송하는 역할을 담당하는 녀석입니다.
정확히는 토픽에 데이터를 기록하기 위해서는 Kafka Producer안에서 작생해야합니다.
그러면, Producer가 토픽과 파티션에 데이터를 기록하게 됩니다.
데이터를 기록할 때는 전송하기 편하게 직렬화를 거쳐야 합니다. 메세지의 직렬화 또한 Producer가 담당하는 역할입니다.
Consumer
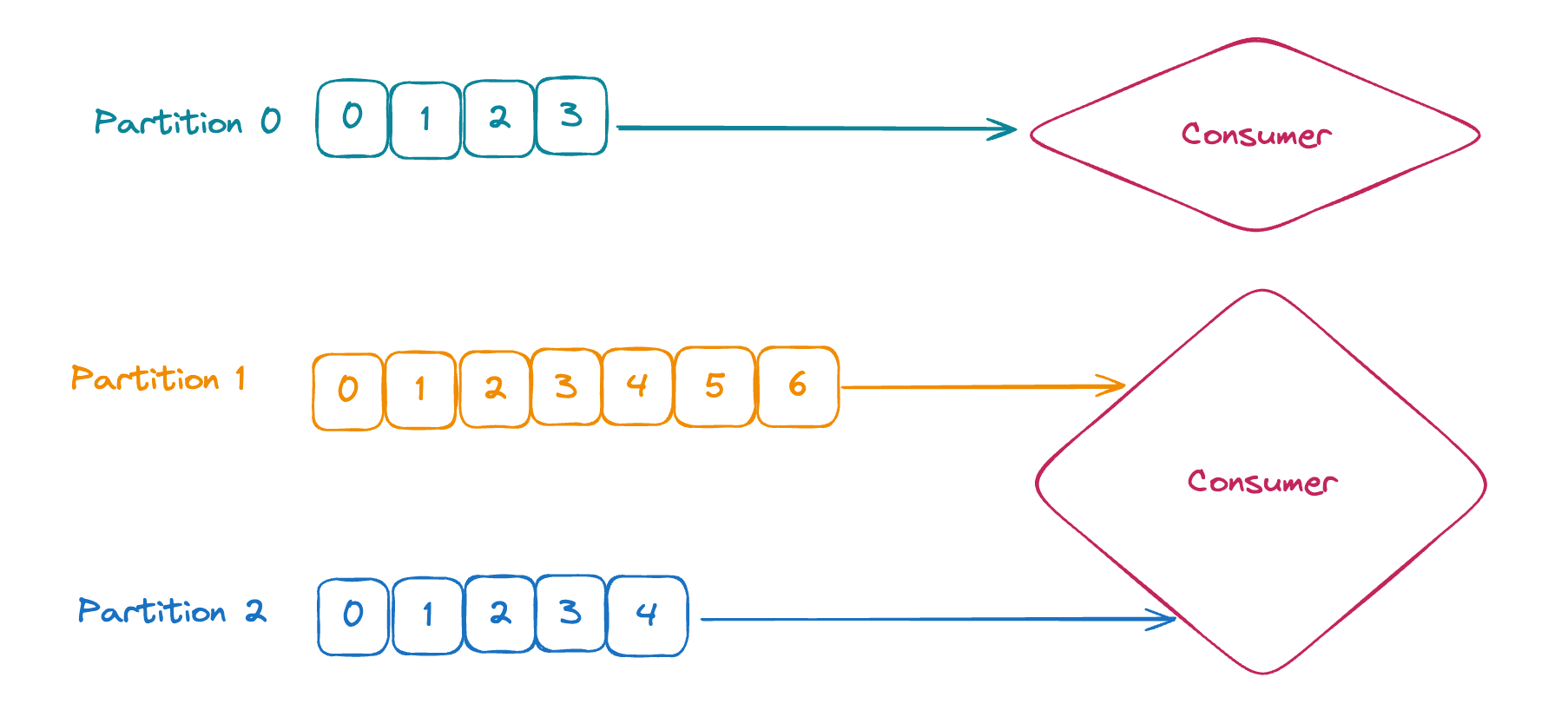
카프카에서 메세지를 수신하는 역할을 담당하는 녀석입니다. 데이터를 Pulling하는 방식으로 메세지를 읽어오죠.
Consumer는 하나 이상의 파티션과 연결되어 Producer 에서 전송한 메세지를 비동기식으로 수신하는 역할을 담당하고 있습니다.
전송된 메세지를 역직렬화를 통해서 원래 메세지의 형태로 전송받는 역할을 하죠
Consumer Group
여러 개의 Consumer 가 모인 그룹입니다.
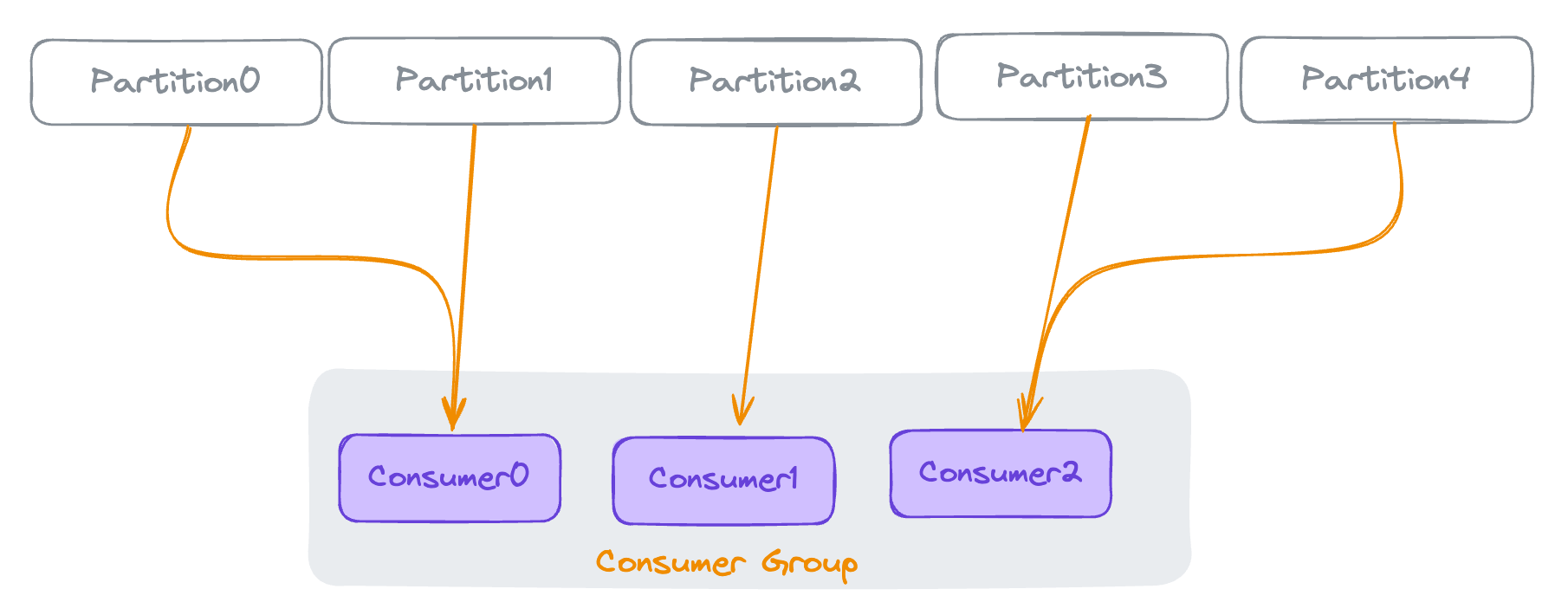
하나의 Consumer Group이 하나의 토픽의 여러 개의 파티션에서 적절히 메세지를 수신하는 그룹입니다.
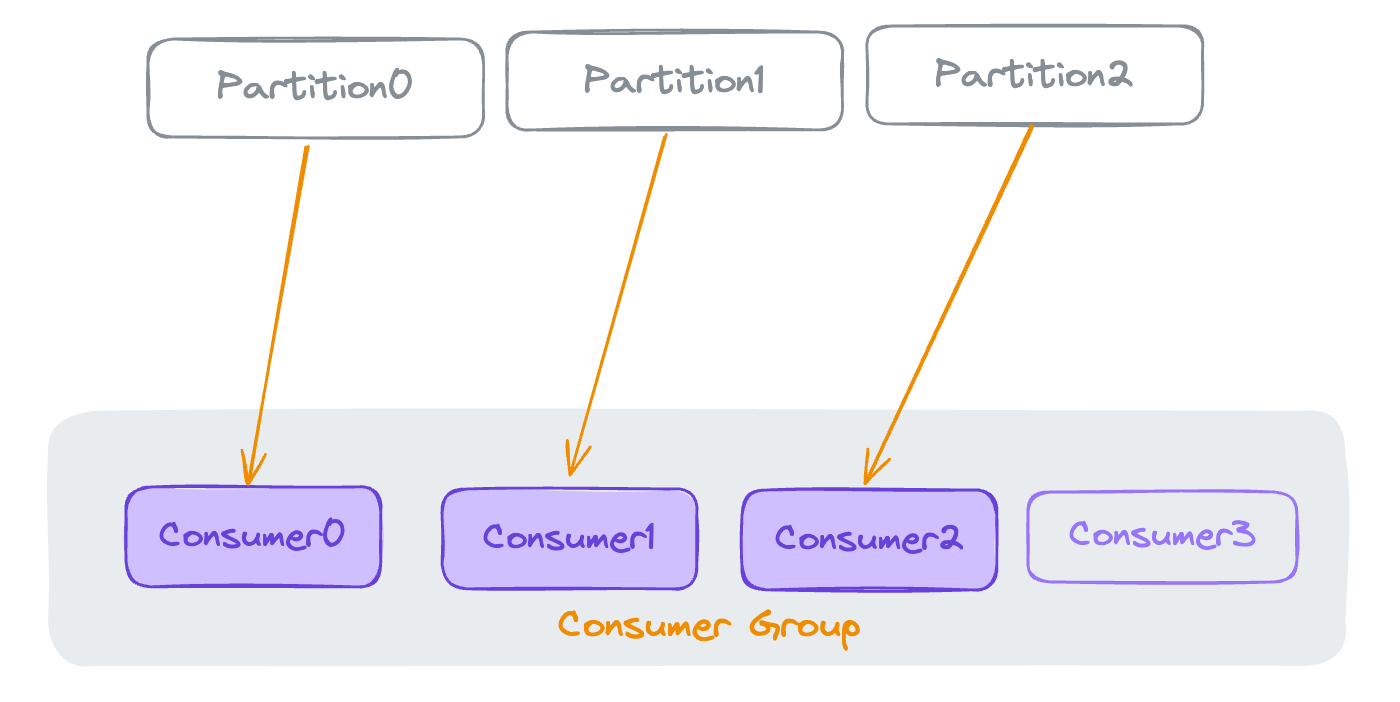
만약 파티션의 개수보다 Consumer Group 내에서 Consumer 가 많으면, 초과되는 Consumer는 휴면 상태에 돌입하게 됩니다.
Offset
오프셋이란, 하나의 Consumer가 토픽의 파티션에서 메세지를 읽었던 부분입니다.
Consumer가 메세지를 하나를 성공적으로 읽으면 오프셋을 commit 하게 되고,
오프셋은 한 칸 앞으로 전진합니다.
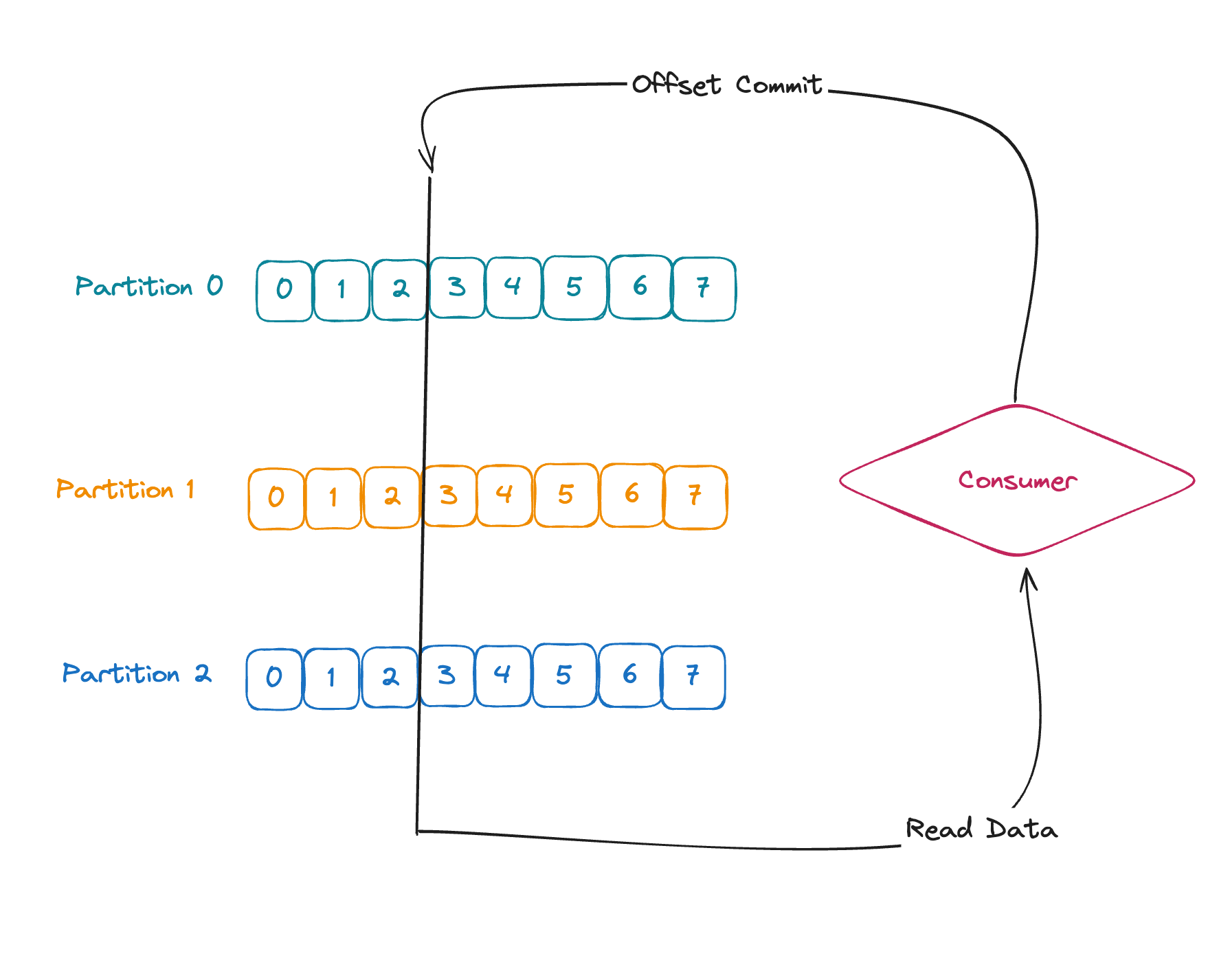
커밋 방법
커밋에는 여러가지 방법이 존재하는데요
Java Consumer 는 기본적으로 At Least Once 를 사용합니다.
총 3가지가 존재하고 하나하나 알아보겠습니다.
At Least Once
- 메세지가 처리된 직후 offset을 커밋함
- 메세지 처리가 실패되면, 해당 메세지를 다시 읽을 기회가 주어지기 때문에 다시 반복이 가능함
- 그렇기 때문의 작업의 멱등성을 살펴봐야함!
At Most Once
- 메세지를 받자 마자 offset을 커밋하는 방식
- 메세지 처리를 실패할 경우, 메세지를 잃어버림
Excatly Once
- 메세지를 딱 한 번만 처리함
- Kafka - Kafka 워크 플로를 할 때, 트랜잭션 API 사용 가능함
오프셋은 계속 증가하는 특성을 가지고 있습니다.
실습
마지막으로 토픽을 생성하고, Producer를 통해 메세지를 생성하고, Consumer로 메세지를 읽어 보는 간단한 예제를 실행해 보겠습니다
Kafka는 정말 못생기고 알아보기 힘든 터미널로 모든 정보를 확인해야 합니다
그렇기 때문에 저는 upStash를 이용해서 예제를 실행해보도록 하겠습니다
우선 현재 클러스터를 확인해 보면
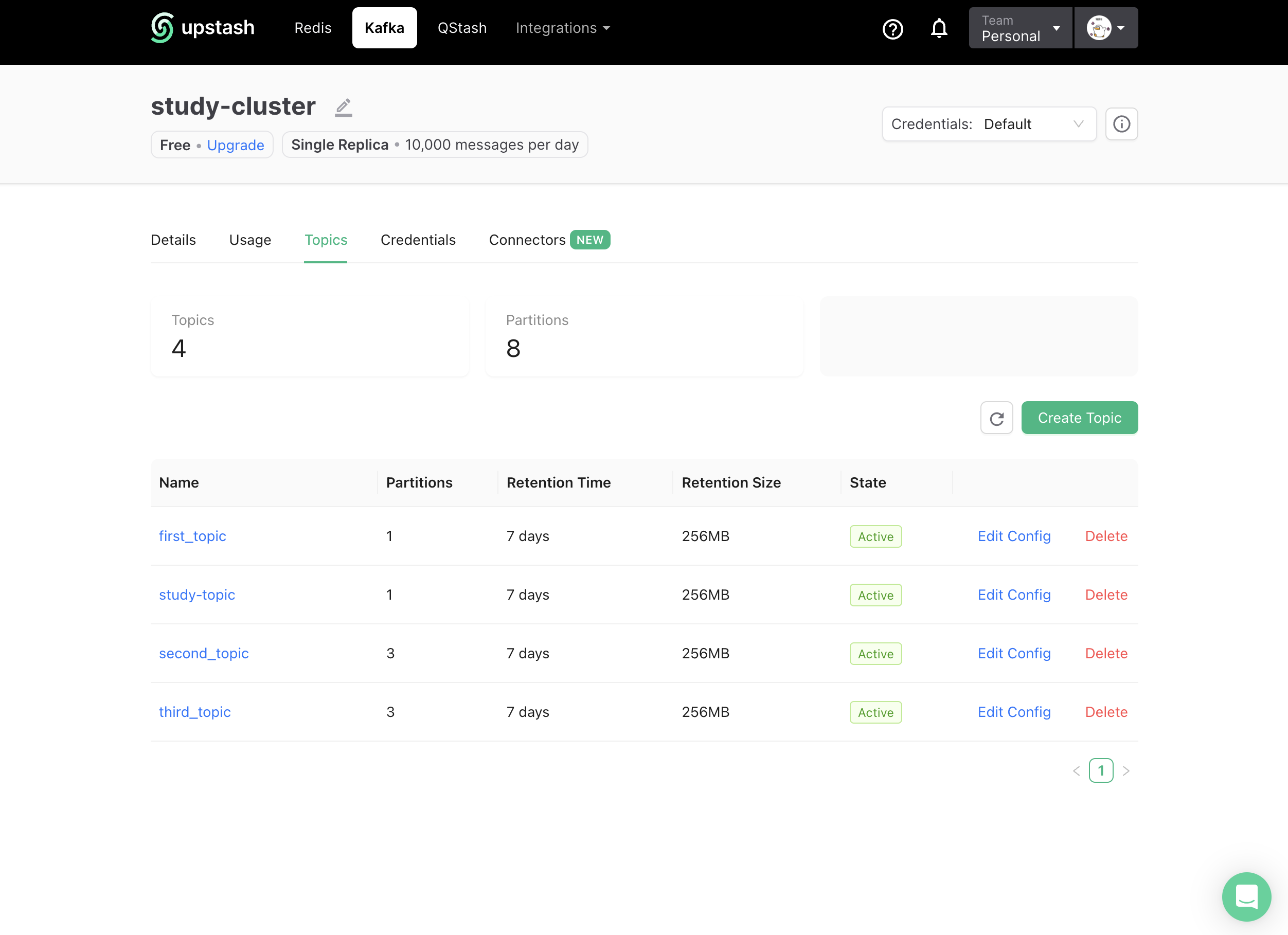
4개의 토픽이 존재하는 것을 확인할 수 있습니다.
여기서 터미널을 통해 하나의 토픽을 생성하면,
kafka-topics.sh --command-config playground.config --bootstrap-server 클라우드_서버 --create --topic 토픽이름
쨘!
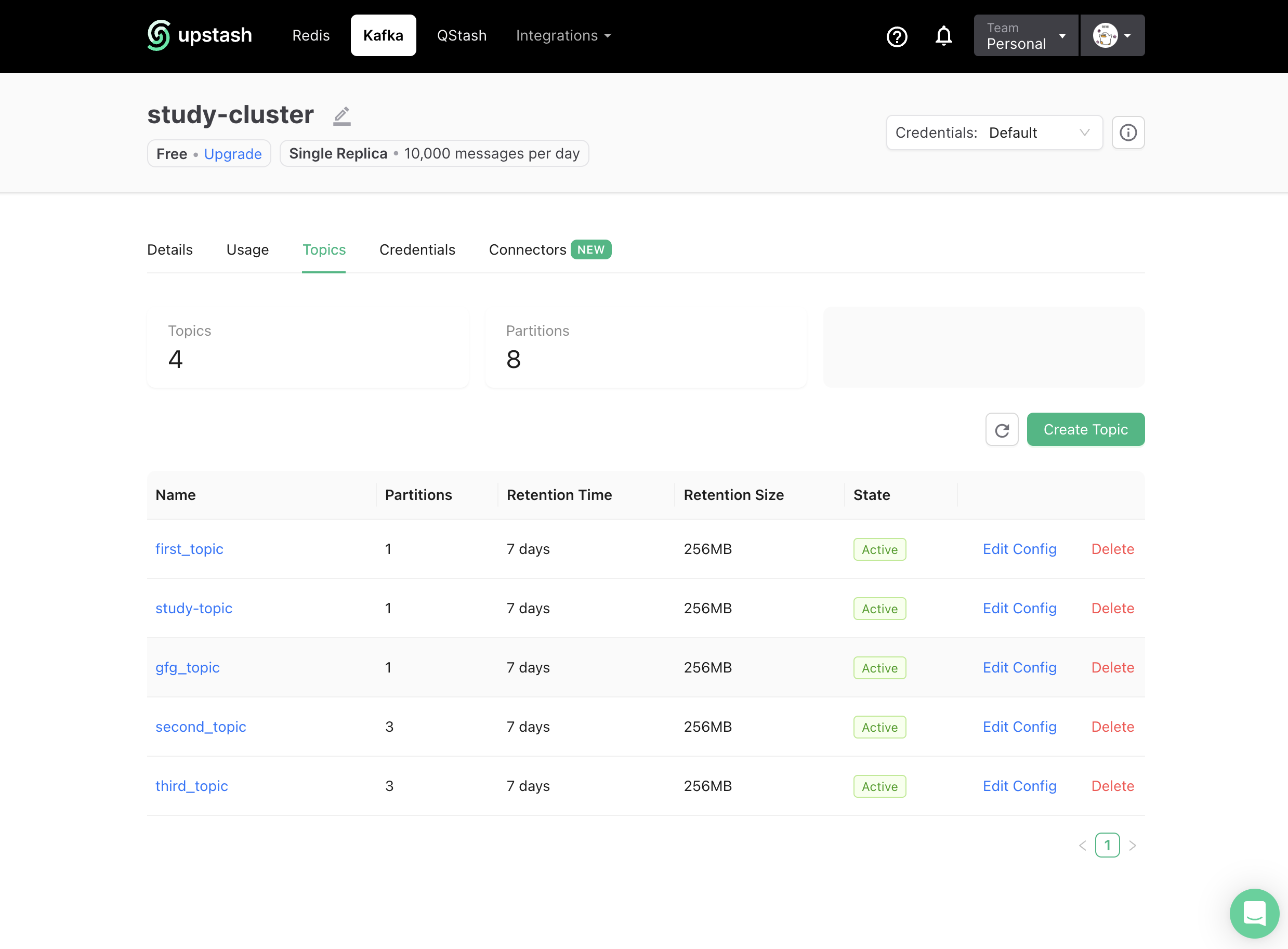
위와 같이 새로운 토픽이 하나 생성 되었습니다.
여기서 이제 하나의 터미널을 더 열어서
하나는 Producer, 하나는 Consumer의 역할을 부여하면....
이렇게 메세제를 주고 받을 수 있는 통로를 하나 만들었습니다!!
오늘은 간단하게 카프카의 중요 개념과 하나의 실습을 해봤습니다!!
