
Classicist TDD vs Mockist TDD
이번주 과제부터는 미션에 제한 조건이 걸려있었다. 모든 기능은 TDD로 구현해야 한다는 조건이였다.
강의에서 아샬님은 Mockist TDD 방식을 사용해서 아래와 같은 순서로 개발하신 것 같았다.
- 정상인 상황 성공 테스트 작성 → 테스트 실패 → 실제 구현 (테스트 성공되도록) → 테스트 성공
- 예외 상황 실패 테스트 작성 → 테스트 실패 → 실제 구현 (테스트 성공되도록) → 테스트 성공
추가로 mock을 사용하여 내부 동작을 정의할 경우에는, verify()를 통해 행위 검증을 수행하는 것 같았다.
그렇다면 Mockist TDD와 Classicist TDD의 차이는 무엇일까?
학습한 내용을 아래와 같이 정리해보았다.
[Mockist TDD]
- Mockist TDD는 “행위 검증” 테스트로써 의존 객체의 특정 행동이 이루어졌는지 검증하는 테스트입니다.
- 장점
- 단위들 간의 테스트를 독립적으로 격리할 수 있어, 외부 요인으로 인한 테스트 실패를 걱정할 필요가 없습니다.
- Spring 환경을 사용하지 않으므로 테스트가 빠릅니다.
- 단점
- 의존 객체에 대한 구현을 직접 설정하기에, 실제 동작과 다를 수 있으므로 테스트의 안정성이 낮습니다.
- 의존 객체의 구현에 묶이는 특성이 있어, 기존 구현이 바뀐다면 테스트가 바로 깨집니다.
- 내부 구현(메서드)을 전부 given()으로 설정해줘야 하기 때문에, 기존 구현에서 추가 기능이 들어올 경우에 추가 기능에 대한 given()이 설정되어 있지 않아 테스트가 깨집니다.
- 따라서 구현이 변경될 때마다 일일히 테스트 코드를 수정해줘야하는 단점이 있습니다.
(리팩토링에 대한 두려움이 생길 듯함)
- 장점
[Classicist TDD]
- Classicist TDD는 “상태 검증” 테스트로써 의존 객체의 구현보다는 실제 입/출력 값을 통해 검증하는 테스트입니다.
- 장점
- 실제 의존 객체를 사용하여 테스트를 진행하므로 테스트의 안정성이 높아집니다.
- 의존 객체의 구현에 묶이지 않고 입/출력 값을 통해 검증하므로, 기존 구현이 변경되더라도 테스트가 깨지지 않습니다.
- 단점
- 실제 의존 객체들과 연결되어 있어, 하나의 테스트가 실패하면 다른 테스트들도 연쇄적으로 실패할 수 있습니다.
(테스트를 세세하게 짜지 않는다면 디버깅이 어려울 수 있을 듯 함)
- 실제 의존 객체들과 연결되어 있어, 하나의 테스트가 실패하면 다른 테스트들도 연쇄적으로 실패할 수 있습니다.
- 장점
하지만 저번 주 회고(3주차)에서 얘기했듯이 mock은 꼭 필요한 상황에서만 사용해야 좋다고 했다.
(실제 mock을 남발할 경우 실제 구현 동작과 다른 상황이 발생할 수 있어 테스트의 신뢰도가 떨어지고, 내부 구현을 변경할 경우는 그냥… 너무 힘들어진다 😂)
따라서 나는 여기에서 고민이 생겼다.
“실제 객체를 사용해서 TDD를 진행하려면 Repository → Service → Controller 순서대로 진행해야되는 건가..??”
그렇다면 “데이터 생성, 삭제 메서드를 먼저 만들어야 되는 것인가..??” 라고 고민을 했었다.
이 때는 실제 객체를 사용하는 것 == 실제 DB 데이터를 사용하는 것으로 생각했기 때문이다.
이 고민이 혼자 해결되지 않아, 이번 주 리뷰어님인 영환 멘토님에게 질문을 드렸더니 다음과 같은 답변을 해주셨다.
- mock 사용을 지양하면 왜 Repository -> Service ->Controller 순서로 개발하야 하나요?!
그리고 그것은 왜 Classic TDD 라고 불리나요?- mock을 사용하면 계층을 나눌 수는 있지만 실제동작과는 전혀 다를 수 있어요.
mock 이 꼭 없어도 FakeObject 를 만들 수 있죠!
Mock vs FakeObject
첫번째로 주신 질문인, mock을 지양한다면 왜 Repository -> Service -> Controller 순서로 개발하는 Inside-Out 방식이 적합하다고 생각했는지 다시금 곰곰히 생각해보았다.
실제 객체의 입/출력값을 통해 테스트가 진행되야되니까 당연히 데이터를 만드는 영속성 계층부터 시작해야되는 것이 아닐까? 라고 생각을 했었던것 같다.
하지만 여기서 난 의문이 들었다. FakeObject가 뭘까?
FakeObject는 실제 객체가 동작한 것처럼 출력값이 전달되도록 만드는 테스트용 객체로써, 실제 객체의 구현 로직을 간소화(?)시킨 버전을 의미한다.
개인적으로 Mock과 FakeObject의 차이점을 아래와 같이 느꼈다.
Mock은 실제 객체의 깡통을 가져다가 행위를 재정의 해주는 것이고, FakeObject는 실제 객체가 동작한것 처럼 출력값이 전달되는 방식인 것 같았다.
따라서 FakeObject를 사용한다면 Mock 과는 다르게 실제 구현이 변경되더라도, 반환 값을 바꾸지 않는 이상 테스트를 그대로 사용할 수 있는 장점이 있는 것 같았다.
이런 식으로 생각을 정리하니까 위에서 얘기했던 mock을 지양한다면 Repository -> Service -> Controller 순서로 개발하는 Inside-Out 방식이 굳이 아니어도 될 것 같다는 생각이 자연스럽게 들었다.
Controller를 먼저 개발하더라도 Service 객체의 FakeObject를 생성하면 되니 말이다.
나는 초반에 mock을 사용하지 않는다면 유닛 테스트를 불가능하다고 생각했지만, FakeObject가 생각을 바뀌게 해주었다. 그렇다면 mock을 사용하기 적절한 상황은 무엇일까?
영환 멘토님은 다음과 같은 질문을 던져주셨다.
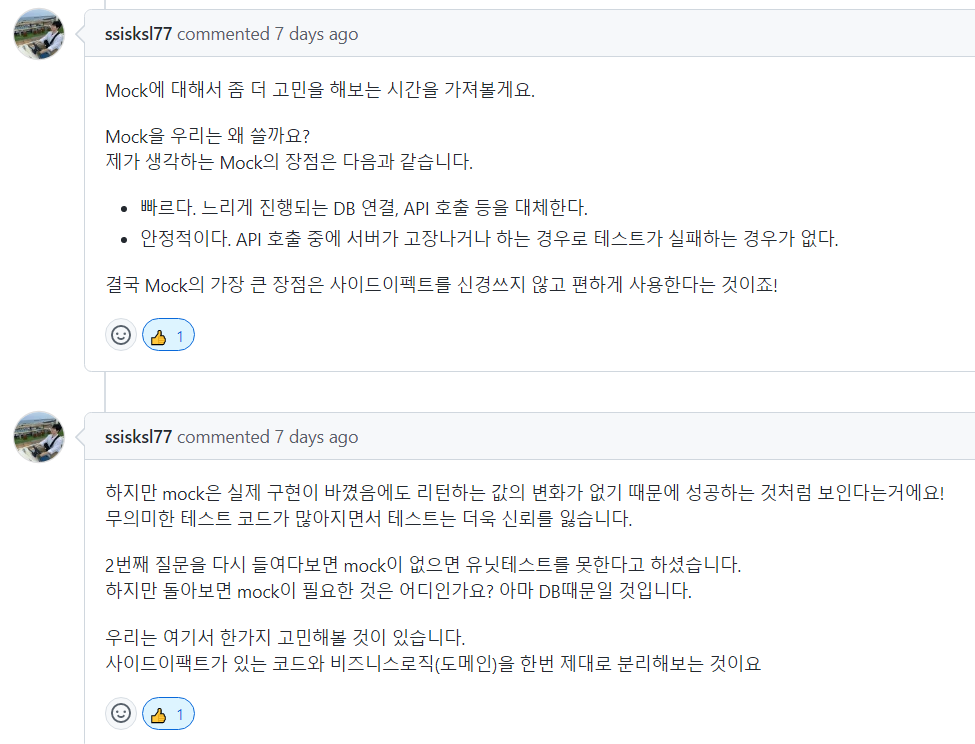
FakeObject와 다르게 Mock의 가장 큰 장점은 사이드 이펙트를 신경쓰지 않고 편하게 사용할 수 있다는 것이다.
따라서 직접 제어할 수 있는 로직들 같은 경우에는 최대한 FakeObject를 사용하고, FakeObject로 구현하기 어려운 것들을 Mock으로 대체할 수 있을 것이다.
예를 들면 외부 날씨 정보 API, 주식 정보 API, 구글 메일 발송 프로그램 등 내부에서 제어할 수 없거나 테스트 할 때마다 매번 실제로 호출하기 어려운 것들은 Mock을 사용하는 것이 바람직할 것이다.
우리는 여기서 한가지 고민해볼 것이 있습니다.
사이드이팩트가 있는 코드와 비즈니스로직(도메인)을 한번 제대로 분리해보는 것이요
비지니스 로직(도메인)은 FakeObject로 대체하였다.
방법은 간단했다. 실제 DB를 사용하지 않고 객체를 하나 생성해 아래와 같이 ArrayList를 하나 선언했다.
private List<Product> products = new ArrayList<>();
해당 products 변수는 이제 Product 도메인의 임시 데이터베이스가 되는 것이다.
기타 CRUD 로직은 모두 해당 변수 products에 저장하고, 삭제하고, 수정하고, 조회한다.
이렇게 하면 FakeObject의 본 목적대로 실제 객체가 동작한것 처럼 출력값이 전달되는 효과를 얻을 수 있다.
앞으로 단위 테스트를 작성할 때 FakeObject 사용을 지향하고, FakeObject로 구현하기 어려운 기타 제약 사항이 있는 곳에서는 부분적으로 mock을 사용해 개발하면 좋을 것 같다는 생각이 들었다.
Hexagonal-Architecture
이번주에 영환 멘토님께서는 헥사고널 아키텍처에 대해 소개해주셨다.
헥사고널 아키텍처는 무엇일까?
포트와 어댑터 아키텍처, 육각형 아키텍처 등 불리는 이름이 여러개인 헥사고널 아키텍처는 아래와 같은 구조를 지니게 된다.
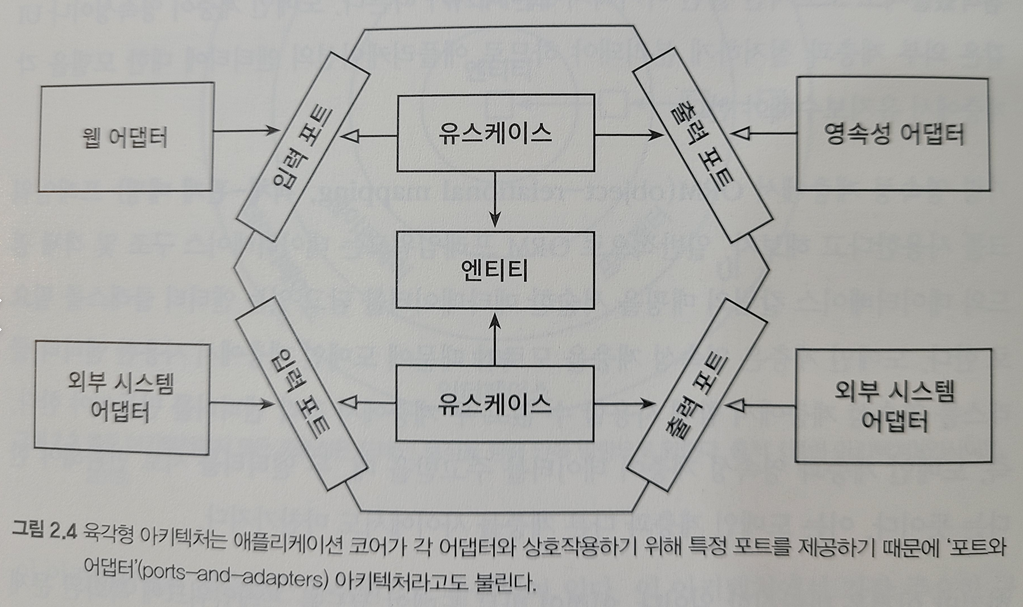
추가로 자료를 조사해보며 정리한 내용은 아래와 같다. 헥사고널 아키텍처의 핵심 요소는 크게 4가지인 것 같다.
- 어댑터
- 인커밍 어댑터(ex. 컨트롤러)
- 아웃고잉 어댑터(ex. Persistence(DB)) - 포트 (인터페이스)
- 인커밍 포트 (ex. usecase 인터페이스)
- 아웃고잉 포트 (ex. persistence 인터페이스) - usecase (application)
- domain (entity)
헥사고널의 특징은 모든 계층의 의존 방향이 도메인 엔티티로 향하는 것이다.
따라서 도메인 엔티티는 바깥쪽 코드에 의존하지 않게 됨으로써, 외부 환경 변경에 의한 코드 수정이 일어날 경우의 수가 줄어든다.
또한 어댑터를 사용하는 곳은 모두 Interface를 통해 의존 역전이 일어나므로 웹이나 영속성(DB) 등의 외부 환경을 변경해야 할 때 유스케이스의 변경 없이 쉽게 갈아끼우거나 수정할 수 있게 된다.
좀 더 깊은 이해를 위해 프로젝트에 아래와 같이 적용해보았다.
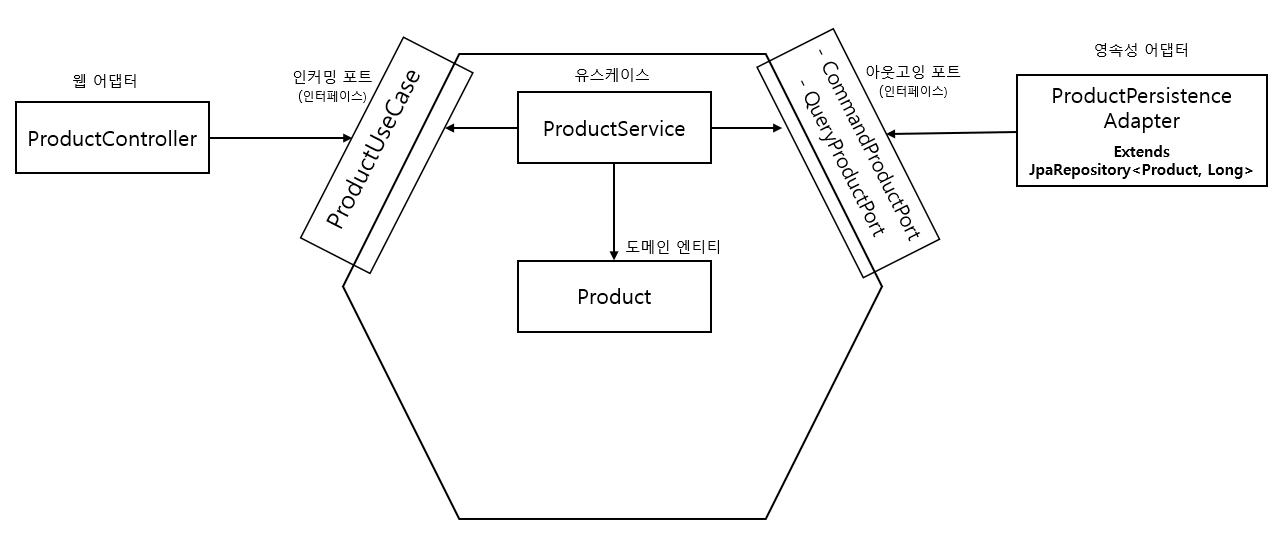
여기에서 한가지 궁금한 점은 영속성 어댑터 부분이었다.
헥사고널 아키텍처의 장점을 최대한 살리는 방법은 모든 객체 간의 결합도를 제거하는 것으로 이해했는데, 그렇다면 영속성 어댑터에서도 Spring JPA랑 PersistenceAdapter랑 분리해야하는 것이 아닐까? 라는 의문이 들었다.
관련 질문에 대한 답변은 아래와 같다.
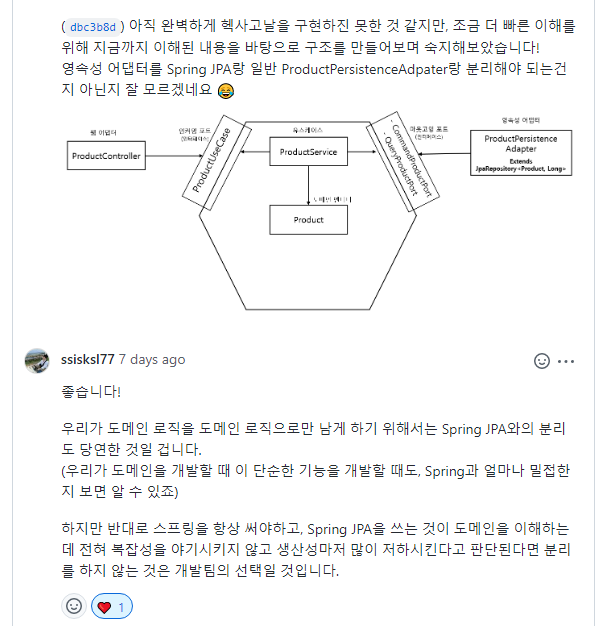
이 부분에서 약간의 오타가 있으신 것으로 사료되는데, 정리한 내용은 다음과 같다.
- 순수 도메인 로직만을 위해서라면 Spring JPA와의 분리도 당연히 진행해야한다.
- 하지만 Spring을 항상 쓰고, Spring JPA를 사용하는 것이 도메인의 복잡성을 야기시키지 않는다면 분리하지 않는다.
- 또한 Spring JPA를 분리하게 될 때 생산성이 많이 저하될 것으로 예상되는 경우 분리하지 않는다.
따라서 모든 코드숨 회고에서 한번씩은 말했듯이 기술에 정답은 없으니, 상황에 따라 적절한 판단을 팀과 함께 결정해나가면 될 것 같다.
내가 느꼈던 헥사고널 아키텍처의 장점을 객체지향 원칙으로 정리해보며 글을 마무리하겠다.
-
OCP : 외부 환경(웹, 영속성)의 변경으로부터 usecase가 수정되지 않고 어댑터만 새로 구현한다면 그대로 재사용할 수 있기에 OCP를 잘 지킬 수 있다.
-
DIP : 모든 외부 계층(웹, 영속성)과 usecase는 포트(인터페이스)를 통해 연결되므로, 의존 역전(DIP)을 지킬 수 있다.
-
SRP : 어댑터 계층은 외부 환경이 변경될 경우에만 코드 변경이 이루어지기 때문에, 단일 책임 원칙의 숨은 뜻인 "객체는 오직 한가지의 변경의 이유만을 가져야 한다"는 원칙을 지킬 수 있다.
