제목: The impact of preprocessing on text classification (2013)
A.K. Uysal, S. Gunal / Information Processing and Management 50 (2014) 104–112
링크: https://www.sciencedirect.com/science/article/abs/pii/S0306457313000964
0. Abstract:
- Preprocessing is one of the key components in a typical text classification framework
- This paper aims to examine the impact of preprocessing on text classification in terms of various aspects such as classification accuracy, text domain, text language, and dimension reduction.
- 이 논문에서는 다양한 전처리 조합으로 이메일/뉴스 두 도메인 & 영어/터키어로 실험을 해봄
- 실험 결과: 다양한 조합의 전처리 기법을 적절히 섞는 것이 아예 안 쓰거나 다 쓰는 (enabling or disabling them all) 것보다 확실한 성능 개선을 보여준다.
1. Introduction:
- 전세계적으로 폭발적으로 늘어나는 전자 문서들을 정리/분류하기 위한 Text Classification
- 다양한 도메인에서 응용이 되고 있음: Topic detection, Spam E-mail Filtering, Sentiment Analysis 등등…
- 전통적인 텍스트 분류의 과정은: Preprocessing - Feature Extraction - Feature Selection - Classification
-- Preprocessing: Tokenization, Stop-word removal, lowercase conversion, stemming
-- Feature Extraction: Bag-of-words 같은 방법으로 벡터 스페이스를 구성
-- Feature Selection: Document Frequency, Chi-square와 같은 방법으로 처리
-- Classification: 다양한 분류 알고리즘 (SVM, Decision Tree, Bayesian 등등) - 강조하고 싶은 점은, 전처리 과정도 Feature Extraction/Selection 만큼이나 중요한 과정이다
- 기존에 Preprocessing의 영향을 확인하고자 했던 연구는 굉장히 많았다.
- 스터디는 굉장히 많았으나, Table 1 의 나온 내용대로, 다 제각기 다른 환경에서 진행을 했기 때문에 스터디 별로 전처리 효과가 매우 상이하다. (성능에 좋은 영향을 주지 못했지만, 벡터의 Dimensionality를 줄일 수는 있었다…오히려 성능에 악영향을 줬다…조금 도움이 되었다…등등 결과가 매우 다양함)
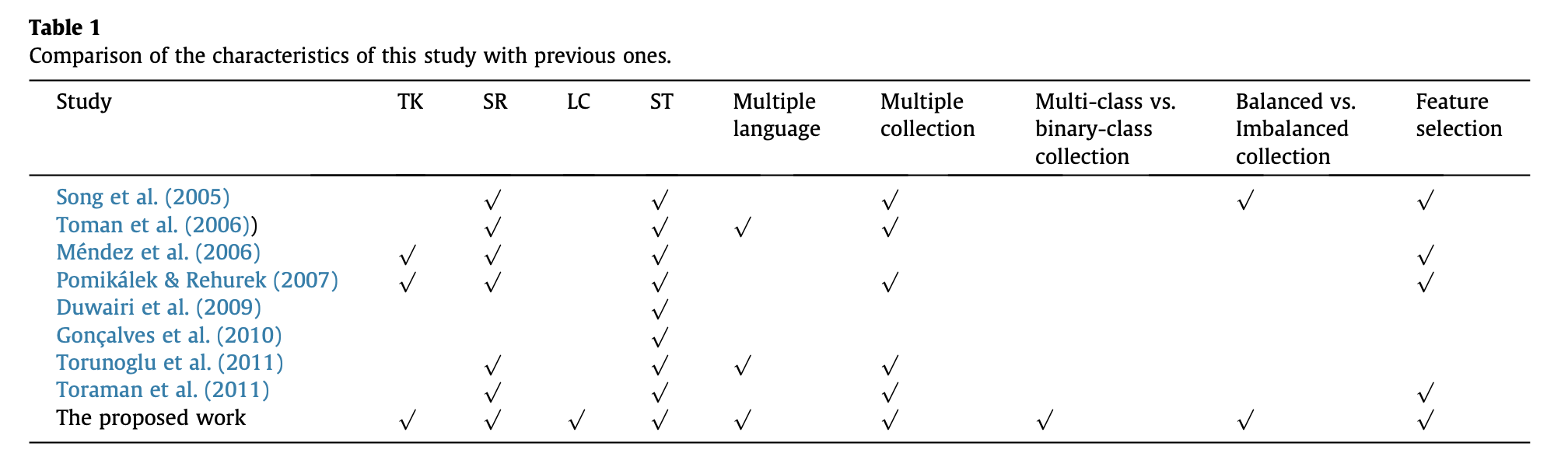
- 그래서 이번 논문에서 가능한 모든 조합으로 전처리의 효과가 어떠한지 확인을 해보겠다고 함
(본 논문에서 약자를 다음과 같이 사용함)
Tokenization = TK / Stop-word removal = SR / Lowercase Conversion = LC / Stemming = ST
2. Preprocessing Methods
- 그래도 처음 논문을 읽는 분들을 배려해서, 위에서 나온 전처리 기법들의 개념을 소개해준다. 나도 간단하게라도 써야겠다
- Tokenization (토큰화) : 텍스트를 단어와 같은 최소 구성 요소로 나누는 작업 (“I like cats” -> “I”, “like”, “cats”)
- Stop-words : 글에서 자주 등장하는 단어들 (예로 들면 영어에서 the, an, a, is). 너무 많이 등장해서 텍스트를 분류하는데는 큰 도움이 되지 않고 관계가 없을 것으로 예상이 되어 사전에 제거를 하는 용도로 사용한다.
- Lowercase conversion : 영어 기준으로 모든 단어들을 소문자로 변환해주기
- Stemming : 단어의 어근(?)으로 정리하는 작업. (예: running, runner -> run이라는 단어의 의미를 가진 단어로 정리)
3. Experimental Settings
- 전처리 방법, 데이터셋, Feature Selection 기법, Classification 알고리즘을 포함한 다양한 조합으로 실험
- 전처리: TK,SR,LC,ST의 2^4 = 16가지의 조합
- 데이터셋: 이메일/뉴스 도메인 & 영어/터키어의 조합
- Feature Selection: Chi-square
- Classification: SVM / 성능 측정은: Micro-F1 score
4. Experimental Work
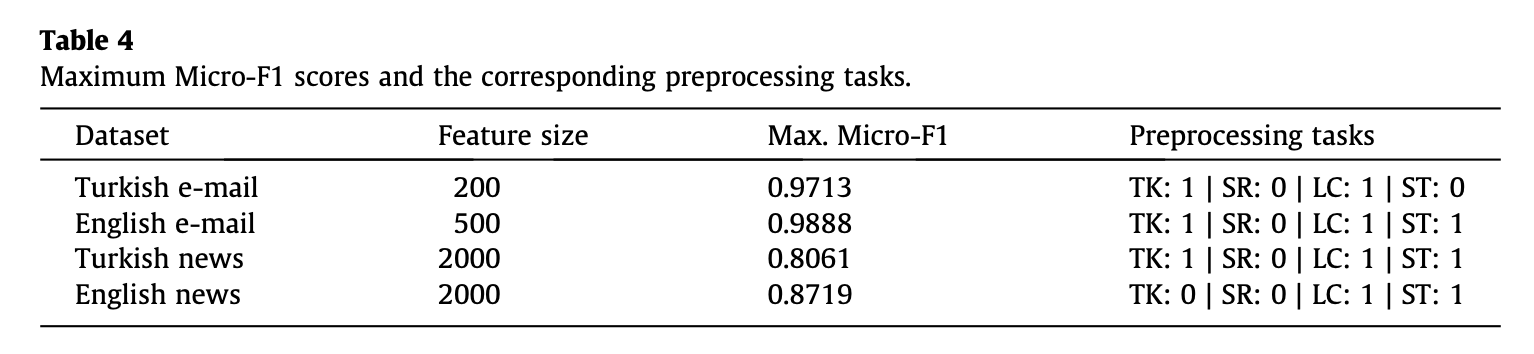
- 다양한 시나리오에 대한 성능 요약은 아래와 같음
- 그리고 다른 연구들과 비교를 했을 때 전처리 기법의 영향 비교
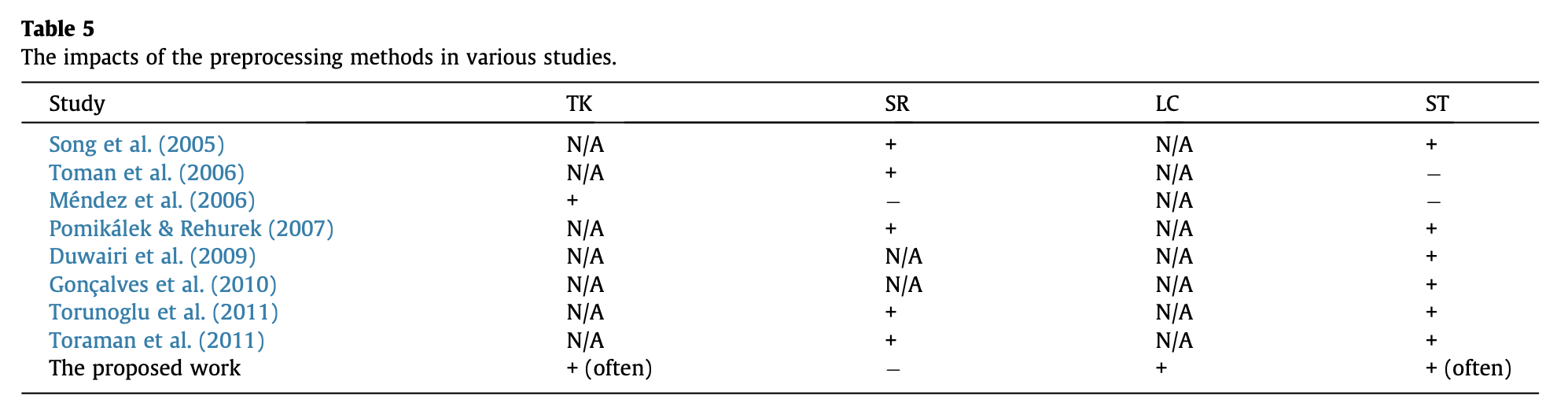
- 막 우와...이걸 써야겠다...라는 느낌을 주는 설정값은 없었음.
- 결국 어떤 문제를 해결하려고 하는지, 그 문제의 환경에 따라 차이가 많이 남
5. Conclusion
- 전처리 기법도 도메인/언어나 환경에 따라 적절히 잘 사용하면 성능 개선이 도움이 되지만, 조합을 잘못하면 성능이 오히려 안 좋아질 수 있다고 확인.
- 알아서 잘 조합을 해서 사용을 해라…

아픈 사람 돕고 싶은 Bioinformatics Engineer