[0]
- OpenPose
- Carnegie Mellon University에서 개발한 오픈소스 라이브러리이다. Body, Hand, Face 세 종류의 뼈대(Skeleton) 위치를 추정하고, 그 위치를 나타내는 키포인트(총 135개)를 제공한다. 또한 이미지 및 비디오 내에서 핵심 좌표 데이터를 추출하는데 있어서 다수의 사람이 포함되어 있더라도 각각의 사람에 대한 신체 핵심 좌표 데이터를 구분하여 제공해 준다. 그러나 학습량에 따라 일반적으로 잘 취하지 않는 자세의 경우, 신체의 일부가 가려진 경우, 여러 사람이 겹치는 경우 등에서 신체에 대한 좌표 데이터를 생성하기 어렵다는 문제가 있다
- MediaPipe
- MediaPipe는 구글에서 개발한 오픈소스 프레임워크이다. 사진 또는 영상에서 실시간으로 사람의 동작을 감지하여 몸 관절에서 33개, 손 관절에서 21개의 3D 랜드마크를 추론할 수 있다.
- 기본적인 얼굴 인식(Face Detection) 외에도 얼굴 윤곽의 좌표(Face Mesh), 손, 팔 등의 신체 부위 인식, 자세(Pose)에 대한 좌표, 머리칼(Hair Segmentation) 등의 이미지 분석 기능을 제공한다.
- CNN
- LSTM
- Conv1D-LSTM 결합 모델
[1] CNN기반의 온라인 수어통역 상담 시스템에 관한 연구 (2021)
- data
- 한국수어 사전에 있는 일상생활에서 많이 사용되는 수어 단어 300개를 선별하여, 영상으로 촬영하고 시스템에 학습
- 촬영하는 영상의 Frame Rate는 초당 24개의 프레임을 촬영하기 위해 일반적으로 영화 촬영 시 표준이 되는 24fps(Frame Per Second)를 설정하여 촬영을 진행
- 촬영된 영상은 연속된 이미지로 시스템에 입력이 되며 시스템의 학습 진행 속도 향상을 위해 이미지 크기를 가로, 세로 224픽셀로 고정하였다.
- OpenCV에서 제공되는 이진화 기법을 사용하여, 변환된 이미지들의 색을 인식하여 전처리 작업을 수행하였다. 이진화 처리된 데이터는 오픈소스로 제공되고 있는 Teachable Machine의 기술을 활용하여 이미지 내의 신체 영역에 대한 객체를 생성하고, 손부분의 오브젝트 영역을 사각형으로 영역을 지정하고, 손의 마디 부분에 객체를 생성하여 데이터화 하고, 이를 데이터베이스에 저장한다.
- model
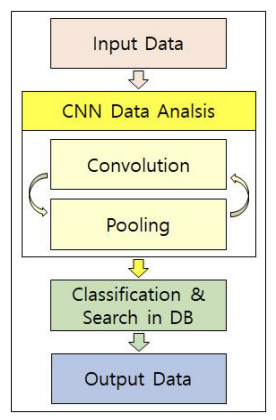
- 일반적인 CNN모델과 ResNet50,
VGG-16등 특성 추출 성능이 검증된 주요 CNN모델의 구조를 적용하였다.
- 일반적인 CNN모델과 ResNet50,
- train
Epoch = 800 Batch_size = 32 Learning_rate = 0.001 With session(graph = g) as session : Execution session_data_reset_function()) for i in range (30) : batch_data, batch_label = batch(img_list, Batch_size), l = session.run([train, loss]), feed_dict = {x: batch_data y: batch_label }) print(i, 1) saver.save(session, ‘’, global_step = i + 1)
[2] 딥러닝 기반 OpenPose를 이용한 한국 수화 동작 인식에 관한 연구 (2021)
- data
- 데이터 수집
- AI Hub와 국립국어원의 Open Data 중 조회 수가 높은 10개의 단어를 수화 데이터로 선정하였다. 선정된 10개의 수화 데이터는 ‘감사’, ‘경찰’, ‘머리’, ‘안녕’, ‘아래’, ‘위’, ‘집’, ‘존경’, ‘친구’, ‘아빠’ 등 이다. 선정된 10개의 수화데이터에는 수화 동작의 형태가 비슷한 단어들이 포함되어 있어 수화 동작 인식 및 분류에 대한 난이도를 높이고자 하였다.
- 데이터 전처리
- 촬영한 수화 비디오의 해상도는 1280 × 720 픽셀이고 같은 동작을 촬영한 비디오도 촬영자 별로 약 3~6초로 비디오 길이가 달랐다. 데이터의 균일화 및 전처리를 위해 핵심 부분만 잘라서 프레임 추출을 위한 짧은 비디오로 만들었다. 수화 동작의 핵심 부분으로 이루어진 비디오를 이미지로 표현하기 위하여 동영상의 5번째 프레임마다 핵심 프레임으로 추출하여 총 12프레임으로 구성하였다. 이때 프레임당 이미지의 크기는 650 × 650 픽셀이다.
- OpenPose를 이용한 비디오 프레임 키포인트 추출. 추출한 몸체, 손 그리고 얼굴의 키포인트가 들어있는 비디오를 통하여 비수지 요소인 얼굴표정과 머리와 몸의 움직임 등을 데이터에 포함 할 수 있다. OpenPose의 키포인트가 포함된 각 단어 비디오에서 5번째 프레임마다 핵심 프레임으로 추출하여 총 12 프레임으로 구성된 단어별 이미지 데이터 셋을 생성하였다. 각 이미지의 크기는 650 × 650 픽셀이다.
- 데이터 증강
- 수화의 RGB형식 비디오 파일에서 추출한 총 12프레임을 가진 이미지 데이터 셋(RGB)과 OpenPose 라이브러리를 통해 키포인트가 포함된 비디오 파일에서 추출한 총 12프레임을 가진 이미지 데이터 셋(RGB+OpenPose)으로 구성한다.
- 한 단어당 10명의 사람으로부터 촬영된 10개의 단어를 12프레임씩 나눠 수집한 총 이미지 데이터는 1,200장이다. 준비한 두 개의 데이터 셋을 증강하여 각 데이터 셋을 13,200장으로 늘린다. 본 논문에서 사용한 Augmentation 방법은 Rotation, Shifting, Rescaling, Stretching, Brightness를 사용하였다.
- 데이터 수집
- model
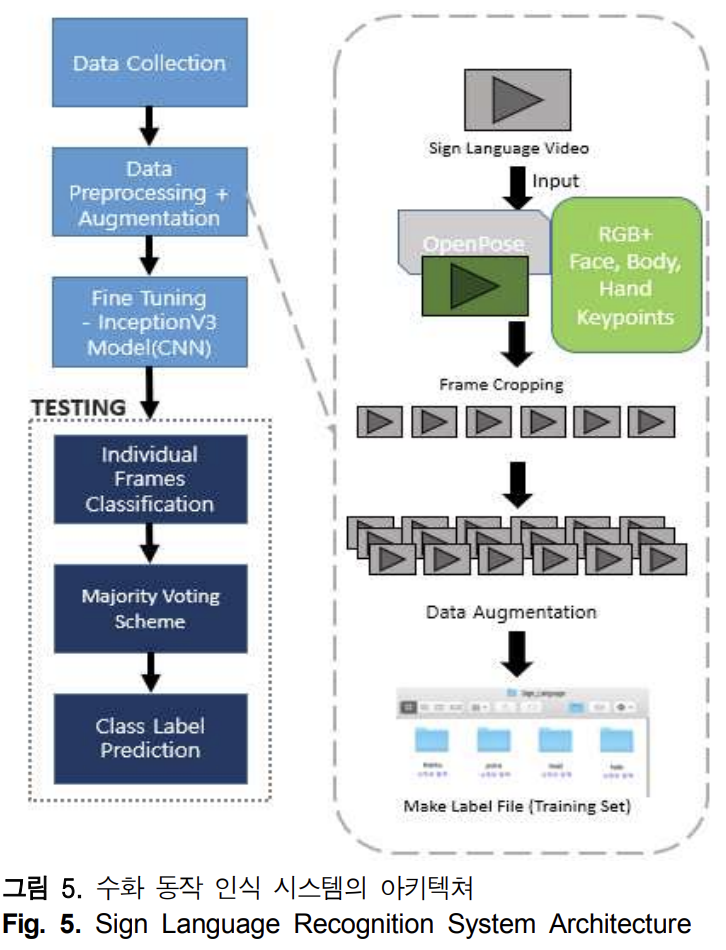
- CNN
- CNN모델로는 InceptionV3을 사용하여 분류하였고 출력층의 Cross Entropy 를 통해 오차가 계산된다. 역전파 과정에서 계산된 오차와 Optimizer를 통해 가중치를 최적화하고 Optimizer는 ADAM을 사용한다. 데이터를 학습시킨 후 테스트 데이터 셋을 통하여 인식 결과를 측정한다.
- 앙상블
- 각 10개의 수화 단어에 Class Label을 부여하고 앙상블 기법 중 다수결 투표 방식인 Voting방법을 통해 입력된 테스트 이미지를 분류한다. 학습된 모델을 이용하여 각 테스트 이미지 프레임에 대해 각 Class Label의 확률점수를 출력한다. 다수결 투표방식인 Voting 방법을 통해 각 테스트 이미지 프레임의 Class Label이 결정되고 다시 Voting 방법을 통해 테스트 이미지에 대한 최종 Class Label이 분류된다.
- CNN
[3] 청각장애인의 수어 교육을 위한 MediaPipe 활용 수어 학습 보조 시스템 개발 (2021)
- data
- 데이터 수집
- 지숫자 9개, 지문자 24개(자음 14개, 모음 10개)를 연구대상으로 선정
- 데이터 전처리
-
수형 학습 및 Landmark 추출을 위한 과정은 데이터를 수집하여 이미지 파일을 입력하고 미디어파이프에 이미지 프레임 입력 후 결과를 리턴한다. 그 결과를 이용하여 Landmark와 이미지 프레임에서 손 영역 이미지 추출한다. 추출한 Landmark와 손 영역 이미지를 이용하여 학습용 데이터 셋을 생성한다. 모든 이미지 프레임에 대해서 단계1부터 단계4를 반복하면서 데이터 셋을 생성한다.
# 랜드마크 추출 def detect(self, img): result= self.detector.process(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) height, width, _ = img.shape return HandResult((width, height), result)# 손 영역 추출 def get_box_list(self, bRelative : bool = False): if self.count() == 0: return None box_list = [] landmark_list = self.get_landmark_list(bRelative) for landmark in landmark_list: minX = min(landmark, key = lambda x : x[0])[0] minY = min(landmark, key = lambda x : x[1])[1] maxX = max(landmark, key = lambda x : x[0])[0] maxY = max(landmark, key = lambda x : x[1])[1] box = [minX, minY, maxX – minX, maxY – minY] box_list.append(box) return box_list# 손 영역 위치 및 랜드마크 정보 리턴 def extract(self, img): result = self.detect(img) if result.count() == 0: return None box_list = result.get_box_list(False) landmark_list = result.get_box_landmark_list(True) return [(box, np.asarray(landmark).flatten()) for box, landmark in zip(box_list, landmark_list)]
-
- 데이터 수집
- model
- 추출한 Landmark는 SVM으로 분류하고, Hand 이미지는 CNN 분류기로 분류한다. 두 가지 분류 방법에 따른 결과가 동일하면 해당 예측 결과를 보여준다.
- 전처리 작업으로 (a)원본 이미지에서 변환된 이미지들의 색을 인식하고, Teachable Machine의 기술을 활용하여 이미지 내의 신체 영역에 대한 객체를 생성하고, 손부분의 오브젝트 영역을 사각형으로 영역을 지정하고, 손의 마디 부분에 객체를 생성하여 데이터
화 하고, 이를 데이터베이스에 저장한다. 미디어파이프를 사용한 원본 이미지에서 Landmark를 추출 한 뒤 해당 Landmark를 이용하여 손이 위치한 영역만 추출하여 파일시스템에 저장하여 Labeling을 수행한 후, 시스템은 학습을 진행한다.
[4] 딥러닝 기반 자세 및 손 제스처 인식 기술을 활용한 병원 수어 번역 프로그램 설계 및 구현 (2021)
- data
- 데이터 수집
- 실제로 병원에서 자주 사용되는 57개의 단어를 한국수어사전을 통해 찾아 각 단어당 약 100개씩의 영상을 직접 촬영하여 학습 데이터로 활용
- 데이터 전처리
- 1280 * 720의 해상도
- 미디어파이프 라이브러리를 사용하여 양손의 점 좌표(Frame, 42, 3)들을 얻어냄
- 각 영상마다 프레임 수가 다 르기 때문에 그 크기를 129로 맞추고 모자른 영상들은 패딩
- Dense층을 통과하여서 각 영상들의 크기를 (129, 126)으로 통일
- 데이터 수집
- model
- 전처리된 1차원 데이터를 시퀀스 압축 및 임베딩 효과 를 얻기 위해 CNN을 레이어를 적용하였으며 배치정규화와 ReLU를 적용
- ResNet에서 사용하는 Residual unit을 3번 적용하며 각 레이어 사이에 max-pooling을 적용하여 시퀀스를 압축
- Residual unit을 통과한 데이터를 시퀀스 단위로 분석하고 학습 및 번역하기 위하여 4개의 LSTM 레이어를 통해 압축된 시퀀스 데이터를 학습 (양방향으로 학습을 하기 위해 LSTM에 Bi-directional을 적용)
- 각 레이어 마다 dropout 이 적용되어 과적합되는 현상을 방지 하였고 활성화 함수로 tanh를 적용
- LSTM을 통과한 데이터는 Bahdanau Attention을 적용하여 정보 손실 문제와 기울기 손실 문제를 해결
- 마지막으로 분석된 데이터를 클래스로 분류하기 위하여 밀집(Dense)레이어를 적용하여 클래스를 분류
- 클래스 분류를 위해 마 지막 밀집 레이어에는 softmax를 적용
- training
- epoch 은 200
- 훈련과 테스트과정에서의 loss는 Categorical cross entropy loss를 사용하였고 Optimizer는 Adamax
[5] 딥러닝 기반 수어 교육 온라인 플랫폼 구현 (2022)
- data
- 데이터 수집
- 일상생활 속 많이 쓰이는 문장 6 개, 국립국어원에서 제공되는 한국어 학습용 어휘 목록 내 자주 사용되는 명사 어휘 5개를 채택하여 총 11개의 Label로 구성
- 각 Label에 대한 원본 데이터로 국립국어원 한국수어사전에서 제공되는 영상과 AI HUB에서 제공되는 한국 수어 영상 데이터셋을 사용하여 총 11개의 영상을 수집
- 동작 인식 기술인 MediaPipe를 적용하여 수어 동작 자의 팔과 손가락이 인식된 영상을 추가
- 따라서 각 Label에 대한 데이터로 22개의 영상을 수집
- 데이터 전처리
- 수집된 영상들은 불필요한 동작을 학습에서 제외
- 데이터의 균일화를 위해서 수어 동작의 시작과 끝을 잘라 핵심 동작만을 추출
- 동작을 반복하거나 배속을 조정하는 과정을 통해 모두 3초의 영상으로 통일
- 이후 영상 데이터를 핵심 동작으로 구성된 이미지 시퀀스 데이터로 변환하기 위해서 30fps 영상 기 준 5프레임당 1장, 60fps 영상 기준 10프레임당 1장을 추출 하여, 한 영상당 16장으로 이루어진 시퀀스 데이터로 구성
- 정확도를 위해 데이터 구성에 언어의 기초가 되는 자음과 모음 각각 3개를 추가하여 총 17개의 Label로 구성
- 데이터 증강
- Image Augmentation Library인 Albumentations를 이용하여 수어 동작의 의미를 해치지 않 는 선에서 각 이미지 시퀀스별로 Augmentation
- 회전 ±5, 이동 ±5 px, 크기 조정 ±0.3배, 밝기 ±0.2, 회전 +5 이동 +5로, 총 9개의 조건을 2번의 조정 을 통해 10배의 Augmentation을 수행
- 데이터 수집
- model
- 수집한 데이터의 특징을 학습시키기 위해 ImageNet 데이터 베이스의 영상에 대해 훈련된 컨볼루션 신경망인 VGG16 모델을 이용해 특징을 추출
- 이미지 별 추출된 특징을 시계 열 데이터 학습에 적합한 LSTM을 통해 특징을 학습
- 옵티마이저는 SGD, 손실함수로는 categorical_ crossentropy를 사용
- 마지막으로 훈련된 데이터를 클래스로 분류하기 위하여 밀집(Dense) 레이어를 적용하여 클래스를 분류
- 클래스 분류를 위해 마지막 밀집 레이어 에는 softmax를 적용
[6] OpenCV와 TensorFlow 기반 수어 번역 시스템 (2022)
- model
- OpenCV : 영상 데이터 → 연속된 이미지 데이터로 변환 → 훈련된 모델이 수어의 특징이 되는 부분을 추출
- tensorflow CNN : 추출된 데이터를 분석하고 기존 데이터들과 비교하여 가장 유사정확도가 높은 데이터 검색
- limitation
- 학습시킨 데이터의 개수가 한정되어있음
- 일반적인 데이터에 비해 연결되는 동작으로 표현되는 수어나 몸 전체를 사용하는 수어는 통역의 정확도가 다소 떨어짐
- 수어의 특성 상 같은 동작이더라도 그 순서에 따라 의미가 달라지고 단어와 의미가 단순하게 1대1로 연결되지 않아 통역 시스템에 더욱 연구가 필요
- 손으로 학습 데이터를 한정시킨것이 아닌 표정과 행동 등 비언어적인 표현 또한 학습시켜 대화의맥락도 통역 될 수 있도록 연구가 필요할것
[7] 딥러닝을 통한 실시간 수어 번역 프로그램 개발 (2022)
- data
- 28가지의 수어 영상 데이터를 촬영했다. 수어 영상 데이터에는 26개의 손가락 각도 데이터 및 6개의 포즈 각도 데이터가 들어있으며 수어마다 50개의 동영상이 촬영되었다. 검증용 데이터 및 테스트용 데이터에 10개의 수어 영상 데이터를 할당했다.
- model
- 객체 탐지 및 특징점 추출 : MediaPipe, OpenCV
- 손 및 포즈를 인식하기 위해 웹캠을 통해 실시간으로 영상을 입력 받는다. 그리고 Mediapipe를 사용해서 랜드마크를 탐지하는 것으로 실시간으로 랜드마크를 특징점으로 추출한다. 본 시스템에서는 640x480 해상도의 실시간 영상을 사용했으며 하나의 수어 당 50개의 영상 데이터를 통해 특징점을 저장했다.
- 손 모델
- 포즈 모델 : 6개의 랜드마크 집합을 사용했다. 각 팔의 굽혀진 정도를 알기 위한 [12, 14, 16]와 [11, 13, 15], 엄지와 검지 사이의 각도를 알기 위한 [20, 16, 22]와 [19, 15, 21], 검지와 소지 사이의 각도를 알기 위한 [18, 16, 20]와 [17, 15, 19]의 랜드마크 집합을 사용하였다.
- 수어 모델 적용 : Conv1D-LSTM 결합 모델
- Conv1D 모델로 입력 데이터를 가공하여 LSTM 모델로 학습을 시키는 모델이다. 이 결합 모델은 CNN 모델과 LSTM 모델 둘보다 더 적은 학습 파라미터로 더 낮은 RMSE 및 MRF 오류율을 기록한다. 따라서 결합 모델은 다른 두 모델보다 더 효율적으로 학습이 가능하다
- Conv1d 모델을 통해 Mediapipe에서 추출한 특징점을 입력 데이터로 받아 convolutional layer과 maxpooling layer로 특징과 패턴을 찾고 데이터의 크기를 압축한다. 그리고 압축된 데이터를 LSTM 모델을 통해 학습시켜 데이터 간의 시계열적 순서를 파악한다.
- 객체 탐지 및 특징점 추출 : MediaPipe, OpenCV
[8] 키포인트 기반 수어 시작 및 종료 시점 탐지 기법 (2023)
- 개요
- 대부분의 수어 데이터셋은 실제 수어의 발화 데이터뿐만 아니라, 실제 수어 발화와 관련이 없는 정보가 공통적으로 포함되어 있다. 따라서, 본 논문에서는 수어 인식 정확도를 향상시키기 위해 수어 데이터에서 발화자의 주요 키포인트 정보를 추출하고 각 키포인트의 변화량에 기반하여 수어의 시작 시점과 종료 시점을 탐지하는 기법을 제안한다. 제안기법은 각 키포인트 변화량의 평균값을 임곗값으로 사용하여 임곗값보다 평균 변화량이 커지는 시점을 수어 시작 시점으로 탐지하고, 평균 변화량이 임계값보다 다시 작아지는 시점을 수어 종료 시점으로 탐지한다.
- MediaPipe의 Holistic 모델을 사용하여 Hand, Pose에 대한 키포인트 데이터를 추출한다. 제안기법은 각 키포인트 데이터의 (x,y) 좌푯값을 이용하여 프레임 간 (x,y) 좌푯값의 변화량에 기반하여 수어의 시작 시점과 종료 시점을 탐지한다.
- 실험을 통해 10개의 키포인트를 기반으로 수어 시작 시점과 종료 시점을 탐지하여도 탐지 소요 시간을 최소화하면서도 탐지 오차를 줄일 수 있음을 확인하였다.
- model
- 수어 영상 데이터에서 추출하고 중앙 크롭 및 이미지 리사이징을 적용한 프레임 데이터에서 추출한 키포인트 데이터를 사용한다. 이를 통해, 프레임 간 키포인트 데이터의 위치 변화량을 이용하여 수화가 발화되는 시작점과 끝나는 시점을 탐지한다.
- data
- 클래스별로 5개의 수어 영상을 사용하여 총 150개의 수어 데이터를 사용하였다. 실험에 사용된 실제 수어 발화의 시작점과 끝나는 시점의 정답 정보는 수작업으로 각 영상의 수어 발화 시점을 확인하여 설정하였다.
[9] 영상 내의 신체 핵심 좌표 데이터를 활용한 머신러닝 기반 수어 인식 연구 (2023)
- model
- Mediapipe의 Hands 및 Holistic 모델을 활용하여 입력 영상에서 신체의 자세를 특정할 수 있는 손가락 끝, 손바닥 중심, 어깨 관절, 무릎, 얼굴 위치 등의 주요 부분에 대한 좌표 데이터를 추출하여 동작 벡터 데이터를 생성하고, LSTM(Long Short-Term Memory) 모델을 활용한 머신러닝으로 수어를 인식하는 시스템 방법 및 구조를 제안한다.
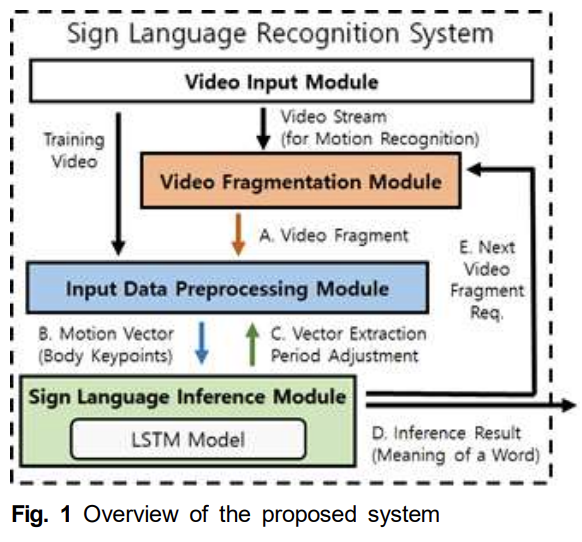
- Mediapipe의 Hands 및 Holistic 모델을 활용하여 입력 영상에서 신체의 자세를 특정할 수 있는 손가락 끝, 손바닥 중심, 어깨 관절, 무릎, 얼굴 위치 등의 주요 부분에 대한 좌표 데이터를 추출하여 동작 벡터 데이터를 생성하고, LSTM(Long Short-Term Memory) 모델을 활용한 머신러닝으로 수어를 인식하는 시스템 방법 및 구조를 제안한다.

좋은 글 감사합니다. 자주 올게요 :)