RDBMS
Relational Database Management System
- a program used to maintain a relational database
- (ex) MySQL, Microsoft SQL Server, Oracle, etc.
- SQL 쿼리를 통해 데이터베이스의 데이터에 접근한다
Relational Database
- type of database that stores/provides access to data points that are related to one another
- each row is a record w/ a unique ID called key
- columns are attributes of the data
1. 테이블들의 연관 관계
Unique Key
- does not allow duplicate values in a column of the table
- does the same job as primary key
- but CAN accept NULL values (primary keys don't)
- accepts only one NULL value
- can be used as foreign key in other tables
- a table can have more than one unique column
테이블 만들 때 unique key 설정하기
CREATE TABLE table_name(
column1 datatype UNIQUE KEY,
column2 datatype,
...
...
columnN datatype
);기존 테이블에 unique key 추가하기
ALTER TABLE table_name ADD CONSTRAINT UNIQUE_KEY_NAME UNIQUE(column_name);Primary Key
- uniquely identifies each record in a table
- benefits
- speeds up data access
- is used to establish a relationship b/w tables
- only one primary key per table
- a primary key can be created across more than one field
- called a Composite Key
- no duplicate values allowed
- canNOT be NULL
- primary key length cannot exceed 900 bytes
테이블 만들 때 primary key 설정하기
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
...
columnN datatype,
PRIMARY KEY(column_name)
);기존 테이블에 primary key 추가하기
ALTER TABLE table_name ADD CONSTRAINT PRIMARY KEY(column_name);기존의 primary key 삭제하기
ALTER TABLE table_name DROP PRIMARY KEY;Foreign Key
- matches a Primary Key in another table to connect the two tables
- maintains referential integrity
- hence, it's impossible to drop the table containing PK
- benefits
- reduces redundancy/duplicates in the table
- normalizes the data in multiple tables
- can be duplicated
- can be null
- a table can have more than one FK
테이블 만들 때 외래키 설정하기
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
CONSTRAINT fk_name
FOREIGN KEY (column_name)
REFERENCES referenced_table(referenced_column)
);기존 테이블에 외래키 추가하기
ALTER TABLE TABLE2
ADD CONSTRAINT fk_name
FOREIGN KEY(column_name)
REFERENCES TABLE1(column_name);기존 외래키 삭제하기
ALTER TABLE table_name DROP FOREIGN KEY (constraint fk_name);2. Indexing
Index
Index: special lookup tables used to speed up data retrieval
- holds pointers that refer to data stored in a database
- improves query/application performance of a database
- (ex) SELECT
- slows down performance of data input queries
- (ex) UPDATE, INSERT
Types of Indexes
Unique indexes
- for performance & data integrity
- does not allow duplicate values
- automatically created by
PRIMARY&UNIQUEconstraints
CREATE UNIQUE INDEX index_name
on table_name (column_name);Single-column indexes
- created only on one table column
CREATE INDEX index_name
ON table_naem (column_name);Composite indexes
- created on two or more columns of a table
CREATE INDEX index_name
on table_name (column1, column2);Implicit indexes
- automatically created by database server when an object is created
Create Index
CREATE INDEX index_name ON table_name;Drop Index
DROP INDEX index_name;When to avoid indexes
- 인덱스는 작은 테이블에 적합하지 않음
- tables with frequent, large batch update/insert operations
- columns with a high number of NULL values
- columns that are frequently manipulated
Show Index
- retrieves information about the indexes defined on the table
- only works on MySQL RDBMS
SHOW INDEX FROM table_name;Unique Index
- no duplicate values allowed in indexed column
- Composite unique index: combination of rows in these columns should be unique
- no combination of coolumns can contain NULL in more than one row
3. Transaction
Transaction: unit of work performed on a database
ACID
ACID는 관계형 데이터베이스 트랜잭션에 필수적인 4가지 요소다
- Atomicity: 하나의 작업은 완료되거나 시작하지 않거나 둘 중 하나의 상태만 존재한다
- 부분적으로만 완수되는 일은 없다
- Abort: 트랜잭션 실패 >> 데이터베이스에 변화가 반영되지 않음
- Commit: 트랜잭션 성공 >> 변화 반영됨
- Consistency: 트랜잭션 전후로 데이터베이스는 consistent해야 한다
- Isolation: 각 트랜잭션은 서로에 영향을 주지 않고, 독립적으로 수행되어야 한다
- Durability: 성공적으로 완료된 트랜잭션은 시스템 실패의 상황에라도 반영되있어야 한다
Consistent: integrity constraints are maintained
Transaction Control
COMMIT- save changesCOMMIT;ROLLBACK- undo transactions that are not already saved to databaseROLLBACK;SAVEPOINT- creates points within groups of transactions to which toROLLBACK- rollbacks the transaction to a point without rolling back the entire transaction
SAVEPOINT SAVEPOINT_NAME; ... ROLLBACK TO SAVEPOINT_NAME; ... RELEASE SAVEPOINT SAVEPOINT_NAMESET TRANSACTION- places name on a transaction- initiates a database transaction
- specifies characteristics for following transaction
SET TRANSACTION [READ WRITE | READ ONLY];
JPA & Hibernate
1. ORM
ORM: Object-Relational Mapping
객체지향적 개념의 클래스와 관계형 데이터베이스를 매핑하는 개념
ORM 덕에 어플리케이션의 객체를 관계형 데이터베이스의 테이블로 자동 매핑 및 영속화가 된다
장점
- 메서드로 데이터베이스를 조작할 수 있다
- SQL문을 작성할 필요 없다
- 유지보수 및 리팩토링이 용이하다
- 비슷한 부류의 RDBMS 간 변경은 코드 변화가 거의 없이 적응할 수 있다
단점
- 직접 SQL문을 작성하는 것에 비해 성능이 낮을 수 있다
2. JPA
JPA: Java Persistence API
Java 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 Interface
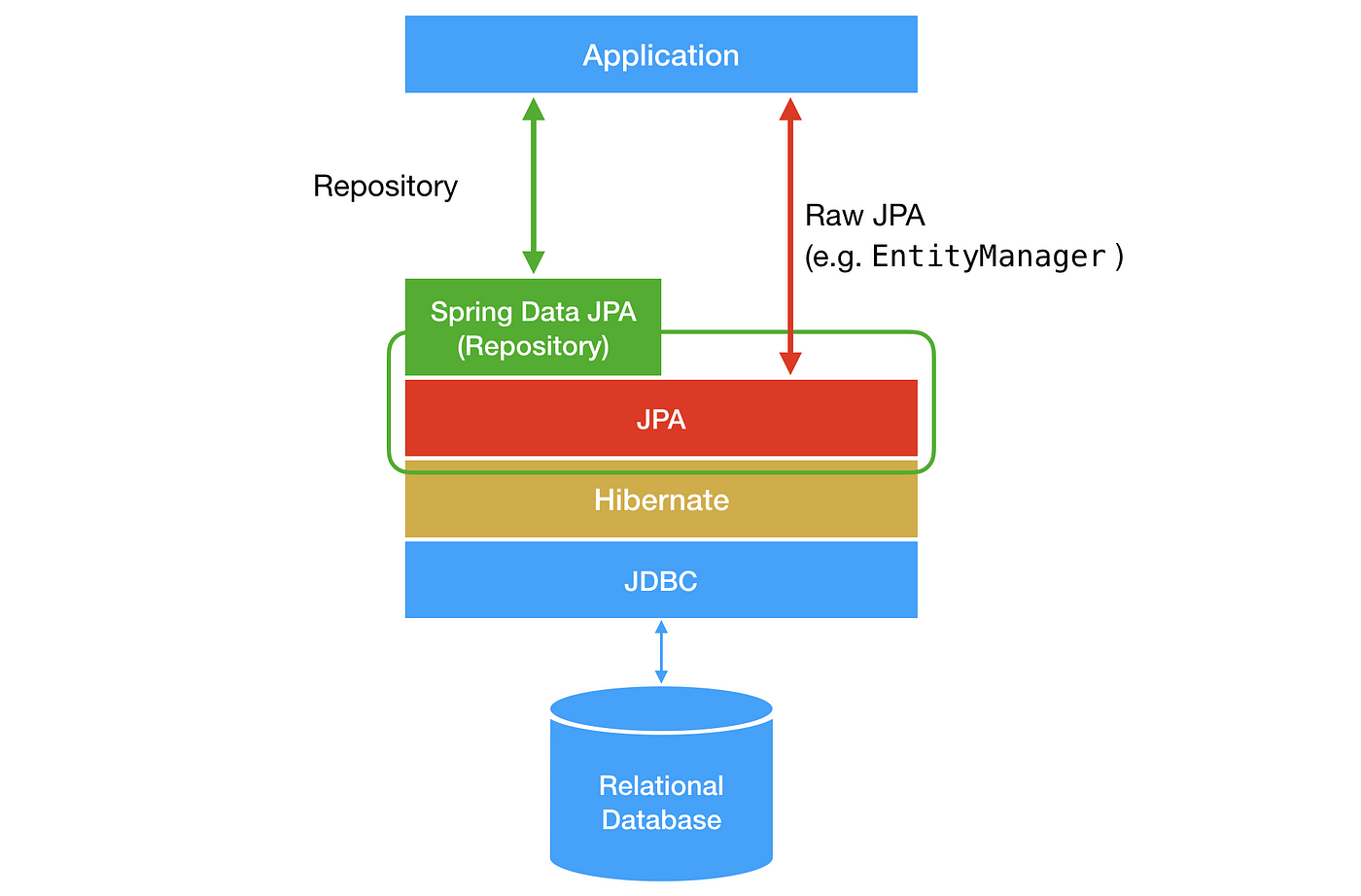
[이미지 출처]
{kind=link}
3. 프로젝트 셋팅
Dependency 추가
spring-data-jpa
JPA 및 데이터베이스 설정
src/main/resources/application.yml
spring:
jpa:
hibernate:
ddl-auto: create
properties:
hibernate.dialect: #본인이 사용할 데이터베이스
...
logging:
level:
org.hibernate.SQL: debugddl-auto:create: 테이블 자동 생성update값을 사용하면 테이블의 변화를 생겼을 때 hibernate이 변화를 자연스럽게 반영하지 못할 가능성이 존재하기 때문에create을 사용하는 편
org.hibernate.SQL: debug: JPA/hibernate이 생성하는 SQL이 logger를 통해 보임
4. Entity 정의
@Entity
@Getter @Setter
@Table(name = "USER",
indexes = {
@Index(name = "username", columnList = "username"),
@Index(name = "email", columnList = "email")
})
public class User {
@Id
@GeneratedValue
private Long id;
@NotBlank(message = "사용자 이름은 필수 입력 항목입니다.")
@Size(min = 4, max = 12)
@IncludeCharInt
private String username;
@NotBlank(message = "암호는 필수 입력 항목입니다.")
@Size(min = 8)
private String password;
@NotBlank(message = "이름은 필수 입력 항목입니다.")
private String name;
@Email
@NotBlank(message = "이메일은 필수 입력 항목입니다.")
private String email;
@NotBlank(message = "전화번호 필수 입력 항목입니다.")
@Pattern(regexp = "^01(?:0|1|[6-9])[.-]?(\\d{3}|\\d{4})[.-]?(\\d{4})$")
private String mobileNumber;
@NotBlank(message = "전공은 필수 입력 항목입니다.")
private String major;
@NotNull(message = "학번은 필수 입력 항목입니다.")
private int studentId;
@NotBlank(message = "자기소개는 필수 입력 항목입니다.")
private String description;
@Enumerated(EnumType.STRING)
private SchoolStatus schoolStatus;
private boolean isMember;
private boolean isClubMember;
private boolean isAdmin;
@OneToMany(fetch = FetchType.LAZY, mappedBy = "user")
private List<Activity> leadingSeminars = new ArrayList<>();
@OneToMany(fetch = FetchType.LAZY, mappedBy = "user")
private List<Activity> leadingStudies = new ArrayList<>();
@OneToMany(mappedBy = "user")
private Set<Participation> participationList = new HashSet<>();
public User(String username, String password, String name, String email, String mobileNumber, String major, int studentId, String description) {
this.username = username;
this.password = password;
this.name = name;
this.email = email;
this.mobileNumber = mobileNumber;
this.major = major;
this.studentId = studentId;
this.description = description;
this.schoolStatus = SchoolStatus.DEFAULT;
this.isMember = true;
this.isClubMember = false;
this.isAdmin = false;
}
public User() {
this.isMember = true;
this.isAdmin = false;
this.isClubMember = false;
}
...
}- 클래스를 정의하면서 고민했던 것들
- 어느 필드를 인덱스로 설정해야 가장 성능이 좋을까?
isMember,isAdmin,isClubMember는 역할을 따로 테이블을 만들어 관리하는 것이 좋을까? 아니면boolean값으로 관리하는 것이 좋을까?- 어떤 validation이 필요할까? 어떻게 구현해야 하나?
@NotBlank,@NotEmpty,@NotNull는 어떻게 다를까?- 테이블간 관계에서 양방향 매핑이 필요할까?
Entity간 관계 매핑하기
@Entity
@Getter @Setter
public class Participation {
@Id @GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
@ManyToOne
@JoinColumn(name = "activity_id")
private Activity activity;
private boolean isApproved;
private String reason;
...
}Custom Validator 정의하기
인터페이스 먼저 정의
@Target( { ElementType.FIELD, ElementType.PARAMETER })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Constraint(validatedBy = IncludeCharIntValidator.class)
public @interface IncludeCharInt {
public String message() default "Your username must include both English characters and numbers";
public Class<?>[] groups() default {};
public Class<? extends Payload>[] payload() default {};
}구현 클래스 정의
public class IncludeCharIntValidator implements ConstraintValidator<IncludeCharInt, String> {
char[] chars;
@Override
public void initialize(IncludeCharInt constraintAnnotation) {
ConstraintValidator.super.initialize(constraintAnnotation);
}
@Override
public boolean isValid(String value, ConstraintValidatorContext context) {
chars = value.toCharArray();
int strCount = 0;
int intCount = 0;
for (char c : chars) {
if (!Character.isLetter(c) && !Character.isDigit(c)) {
return false;
}
if (Character.isLetter(c)) strCount++;
if (Character.isDigit(c)) intCount++;
}
if (strCount==0 || intCount==0) {
return false;
}
return true;
}
}5. Repository
@Repository
public interface UserRepository extends JpaRepository<User, Long>, PagingAndSortingRepository<User, Long>, JpaSpecificationExecutor<User> {
Optional<User> findByUsername(String username);
Boolean existsByUsername(String username);
Boolean existsByEmail(String email);
List<User> findAll();
Page<User> findByUsernameContaining(String infix, Pageable pageable);
Page<User> findByNameContaining(String infix, Pageable pageable);
Page<User> findByMajorContaining(String infix, Pageable pageable);
Page<User> findByIsClubMemberTrue(Pageable pageable);
Page<User> findByIsAdminTrue(Pageable pageable);
}- 기본적으로
findById(),deleteById()와 같은 메서드는 제공됨 Page등을 사용하여 요청된 데이터의 크기가 클 경우를 대비한다- 데이터베이스 작업에 부하를 방지하기 위해 메서드에 자주 등장하는 필드는 인덱스 설정을 고려한다
전체 코드는 제 깃허브 레포에 있어요
References:
- https://www.w3schools.com/mysql/mysql_rdbms.asp#:~:text=What%20is%20RDBMS%3F,the%20data%20in%20the%20database.
- https://www.oracle.com/database/what-is-a-relational-database/#:~:text=A%20relational%20database%20is%20a,of%20representing%20data%20in%20tables.
- https://www.geeksforgeeks.org/acid-properties-in-dbms/
- https://www.tutorialspoint.com/sql/sql-unique-key.htm
- https://www.tutorialspoint.com/sql/sql-primary-key.htm
- https://www.tutorialspoint.com/sql/sql-foreign-key.htm
- https://www.tutorialspoint.com/sql/sql-indexes.htm
- https://www.tutorialspoint.com/sql/sql-show-indexes.htm
- https://www.tutorialspoint.com/sql/sql-unique-index.htm
- https://www.tutorialspoint.com/sql/sql-transactions.htm

우당탕탕