
의식의 흐름에 따른 글 입니다. 틀린 부분이 있다면 지적 해주시면 감사하겠습니다.🙇🏻♀️
어쩌다 성능 개선..?
일단 어째저째 프로젝트를 만들기는 했는데.. 이게 실제 서비스가 된다고 하면 퍼포먼스가 어떨지는 알 수가 없었다. '프로젝트 기간 끝났으니까 끝!'이 아니라 기간 이후에도 조금씩 더 개선해나가면 좋겠다는 생각을 했다. (너무 당연한거라 왜라고 묻는다면 이유가 없음.. 자장면보단 자장면 곱배기가 좋은 것 아니겠슴까) 특히 아무리 좋은 서비스라도 너무 느리거나, 에러가 많다면 사용자들에게 외면 받을 것이라는 점에서 먼저 부하테스트를 진행하기로 했고 부하테스트 툴로는 자료가 많아 접근하기 더 쉬울 것 같은 nGrinder를 사용하기로 했다.(짱민의 글이 도움이 많이 되었습니다. 감사합니다.)
nGrinder
설치
- nGrinder 깃헙에 들어가서 grinder-controller.war를 다운받는다.
- 다운로드를 완료하면 터미널에서 아래의 명령어를 실행한다.
java -jar ngrinder-controller-{version}.war --port=8300 - localhost:8300으로 접속해서 에이전트를 다운받는다
- 다운로드가 완료되면 아래의 명령어들을 실행한다
tar -xvf ngrinder-agent-{version}-localhost.tar // 압축 풀기
cd ngrinder-agent // 에이전트 폴더로 이동
./run_agent.sh // 에이전트 실행이 후에는 꼭 에이전트를 실행하고 localhost:8300으로 접속해야 한다!!!!!! (에이전트 실행도 안해놓고 안된다고 삽질하던 나자신이 말한다...)
여기까지 설치와 준비까지 완료.
스크립트 작성
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
// import static net.grinder.util.GrinderUtils.* // You can use this if you're using nGrinder after 3.2.3
import org.junit.Before
import org.junit.BeforeClass
import org.junit.Test
import org.junit.runner.RunWith
import org.ngrinder.http.HTTPRequest
import org.ngrinder.http.HTTPRequestControl
import org.ngrinder.http.HTTPResponse
import org.ngrinder.http.cookie.Cookie
import org.ngrinder.http.cookie.CookieManager
/**
* A simple example using the HTTP plugin that shows the retrieval of a single page via HTTP.
*
* This script is automatically generated by ngrinder.
*
* @author admin
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test1
public static GTest test2
public static HTTPRequest request
public static Map<String, String> headers = [:]
public static Map<String, Object> params = [:]
public static List<Cookie> cookies = []
@BeforeProcess
public static void beforeProcess() {
HTTPRequestControl.setConnectionTimeout(300000)
test1 = new GTest(1, "127.0.0.1")
request = new HTTPRequest()
grinder.logger.info("before process.")
}
@BeforeThread
public void beforeThread() {
test1.record(this, "test1")
grinder.statistics.delayReports = true
grinder.logger.info("before thread.")
}
@Before
public void before() {
request = new HTTPRequest()
headers.put("access-token","faketoken")
request.setHeaders(headers)
CookieManager.addCookies(cookies)
grinder.logger.info("before. init headers and cookies")
}
@Test
public void test1() {
grinder.logger.info("test2")
String findUrl = "http://127.0.0.1:8080/houses/rent?page=";
String url2 = "&size=5&availableOnly=true";
for (int i = 0; i < 6; i++){
String url = findUrl + i + url2;
HTTPResponse response = request.GET(url, params)
if (response.statusCode == 301 || response.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", response.statusCode)
} else {
grinder.logger.warn("code: {}", response.statusCode)
assertThat(response.statusCode, is(200))
}
}
}
}완벽하지는 않지만 위의 스크립트는 팀프로젝트 글 페이지 1번부터 5번까지 조회하는 로직이다.
스크립트를 작성했으니 테스트를 해보기로 한다. (우리의 프로젝트는 작고 소중하므로) 아래 처럼 Vuser를 10으로 놓고 테스트를 진행했다.
(Vuser per agent는 Agent당 가상 유저이다)
결과는....
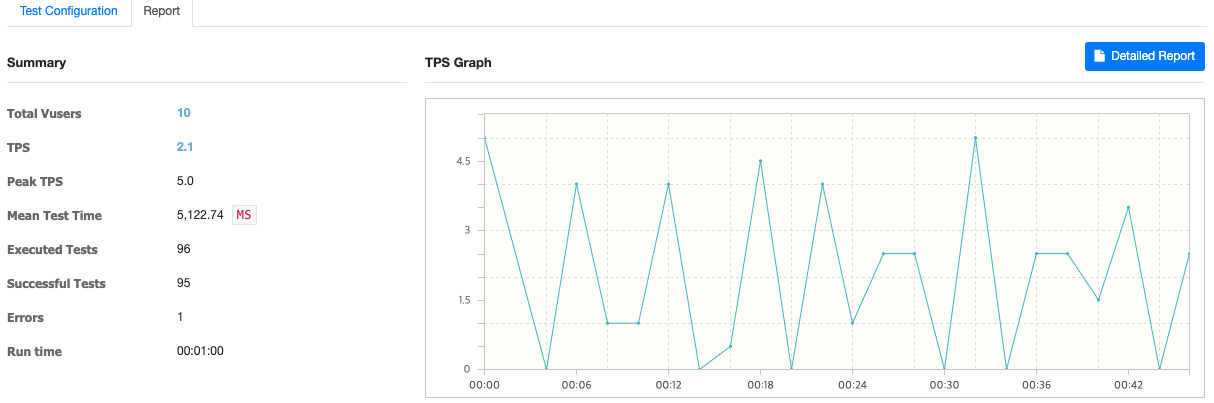
결과를 보면 알 수 있듯이 TPS가.. 단 2밖에 되지 않았고.. MTT(Mean Test Time)이 5000이 넘는 것을 확인할 수 있었다. 해당 api의 쿼리는 아래와 같았다.
List<RentArticle> content = jpaQueryFactory
.select(rentArticle)
.from(rentArticle)
.where(rentArticle.isDeleted.eq(false),
checkAddressAndTitle(searchCondition.getKeyword()),
checkAvailableOnly(searchCondition.getAvailableOnly()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize() + 1)
.orderBy(checkSortCondition(searchCondition.getSortedBy()))
.fetch();이건 아니다 싶어서(검색에 5초나 걸리는게 말이되냐!!!!!!!!!) 어디에서 시간이 오래 걸리는 걸까 찾아보니 sort가 문제(order by절의 checkSortCondition)라는 걸 발견했다.
checkSortCondition에서 몇가지 정렬 기준에 따라 반환해 주고 있었는데 해당 기준을 포함한 인덱스 생성하고 테스트 해보니 MTT가 1/10 정도로 줄어드는 것을 확인할 수 있었다. (아래 이미지 참고 - Mean Test Time: 609.23)
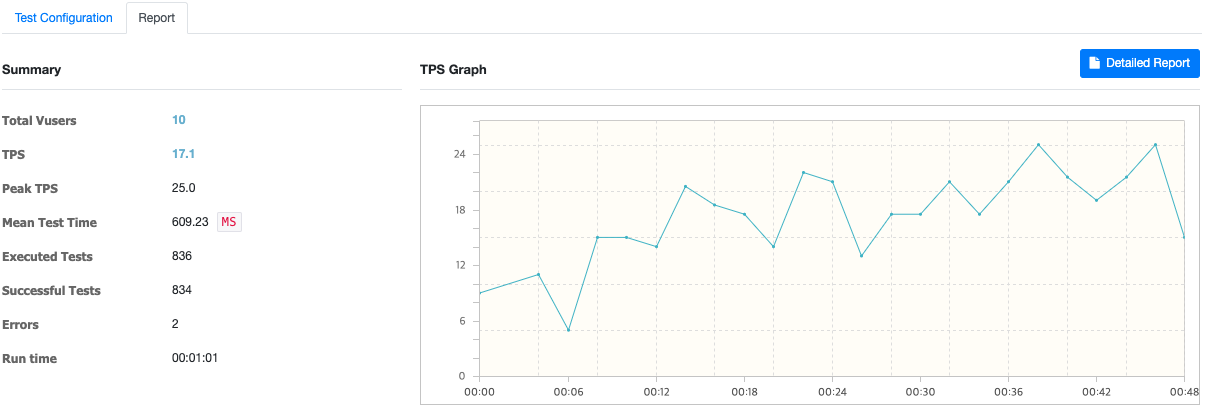
여기에서 멈출 순 없다..!!! 쿼리를 더 개선할 방법이 있을까? 하다가 레디스 캐시..를 도입하기로 하는데..
Redis Caching
먼저 다들 알고 있겠지만...
캐시란 서비스를 사용할 때 많이 사용되는 결과를 미리 저장해두고 이후에 빠르게 서비스 해주는 것을 의미한다.
일반적으로 메모리(RAM)를 사용하기 때문에 데이터베이스보다 훨씬 빠르게 데이터를 응답할 수 있다. 하지만 RAM의 용량은 HDD처럼 큰 것이 아니기 때문에 데이터를 모두 저장할 수는 없기에 전략을 잘 짜서 저장할 필요가 있다.
우리의 프로젝트에는 메인 화면이랄 것이 없어서 (메인화면에 서버에서 보내주는 데이터가 쓰이지 않음;) 어떤걸 캐싱할까 고민하다 자주 쓰이는 몇몇 단어로 검색한 결과(페이지 리스트)를 캐싱하기로 했다.
설정과 준비
사실 우리의 팀 프로젝트에서는 로그인 관련해서 레디스를 쓰고 있었기 때문에 크게 설정할 것은 없었다.
- application.yml
cache: redis //추가한 부분
redis: //원래 있던 설정
host: ${REDIS_HOST}
port: ${REDIS_PORT}
- RedisConfiguration.java
기본 저장 기간은 6시간으로 지정해두었다. aritcle(매물 조회한 페이지)은 6시간동안 저장, cacheCount는 3시간동안 저장되어 있도록 설정했다.
여기서 cacheCount는 해당 페이지 리스트가 반환된 횟수인데 예를 들어 사용자가원룸으로 검색을 한번 했을 때 cacheCount가 1 증가하게 된다. cacheCount가 n번 이상일 때 article을 저장하도록 구현했다 (서비스에서).
@Configuration
@EnableCaching //추가한 부분
중략
@Bean
@Override
public CacheManager cacheManager() {
RedisCacheManager.RedisCacheManagerBuilder builder = RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory());
RedisCacheConfiguration defaultConfig = RedisCacheConfiguration.defaultCacheConfig()
.entryTtl(Duration.ofHours(6L)); //default duration
builder.cacheDefaults(defaultConfig);
Map<String, RedisCacheConfiguration> additionalConfig = new HashMap<>();
additionalConfig.put("articles", defaultConfig.entryTtl(Duration.ofHours(6L)));
additionalConfig.put("cacheCount", defaultConfig.entryTtl(Duration.ofHours(3L)));
return builder.cacheDefaults(defaultConfig).withInitialCacheConfigurations(additionalConfig).build();
}
- Service
캐싱할 부분에 @Cacheable을 달아주면 된다! 여기서 주의해야 할 부분이 있다면..
우리의 경우 검색할 내용들을 DTO로 받아왔는데 key값을 어떻게 넣어줘야 할지 조금 헤맸다.. ^^;;
아래와 같은 형식으로 쓰면된다. (searchCondition - DTO명, keyword - 필드명)
하나 더..! n번 이상 검색되었을 때 저장하기로 했기에 condition을 아래처럼 설정해주었다.
@Cacheable(value="이름", key = "#searchCondition.keyword + #searchCondition.availableOnly", condition = "#count > n개")
public RentArticleListResponse getRentArticles (~~~~~~~~~~) {
...
중략
...
}cacheCount의 경우는 @Cacheput을 활용했다.
@CachePut(value="이름", key= "#searchCondition.keyword + #searchCondition.availableOnly")
public ~~~~~~ 중략이렇게 모든 준비를 끝내고 nGrinder로 다시 부하 테스트를 진행했다.
결과는..!!

MTT가 또 1/10으로 줄어들었다..!!!!!!!!
정리하자면..
1차적으로 인덱스를 활용하니 MTT가 기존의 1/10 정도로 많이 줄어들었고 이후에 캐싱을 사용하니 1/10으로 줄었던 MTT의 1/10으로 또 줄어들었다..!
(5122 -> 476 -> 48)
(아쉬운 점이 있다면 로컬에서 돌려서인지 캐싱을 적용 한 뒤에는 자꾸만 테스트 도중에 죽어버렸는데.. 해결은 하지 못했다고 한다 ㅠㅅㅠ.. 이후에 해결 완료! 요청을 실행하기 위해선access-token을 넣어줘야 했는데 쓰레드를 생성할 때가 아닌 프로세스 생성할 때에 헤더에 access-token 값을 넣어주니 에러가 없어졌다!)
실제 서비스에서는 성능 개선을 위해 쿼리 튜닝이라든지 인덱스, 캐싱을 적절하게 사용하고 있겠구나 싶었지만 이렇게 실제로 경험해보니 색달랐다. 신기하기도 하고.. ㅎㅎ..
물론 지금 적용해 놓은 건 정말 초보자가 어째저째 돌아가게 만드려고 해놓은 누더기.. 에 불과하겠지만.. 취업하고 실제 서비스에 어떻게 적용되어 있을지 꼭 확인하고 싶어졌다 ㅎㅎ
글로 정리하자니 너무 짧아져 그간 고생이 다 담기지 않은 것은 아쉽다.. 하지만 재미있었다..!! (깊이 있게 이해한 것 같지는 않아서 앞으로도 꾸준히 학습해야겠다..!!)

참고
https://leezzangmin.tistory.com/42 (갓짱민;)
https://hamryt.tistory.com/11
https://brownbears.tistory.com/26
https://m.blog.naver.com/qjawnswkd/222404574159
https://prodo-developer.tistory.com/157

대박 꿀잼아티클;;;
order by 인덱스 최적화 한 경험은 다른 글에서 더 자세히 다뤄주시는 거죠!!!!!!!!!!!!!!