이번 시간에는 직접 ANN신경망을 구축해보는 실습을 해보려한다.
Importing the libraries
np,pd,tf세가지 라이브러리만 임포트해주면 된다.
Importing the dataset
우선 데이터 세트를 살펴보면
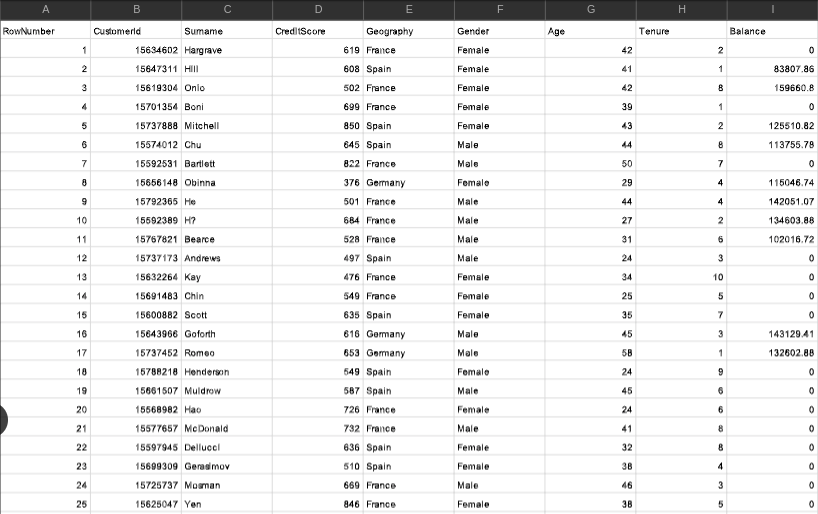
이렇게 각변수의 넘버, 고객id, 고객의성은 실제로 유의미한 종속변수가 아니기때문에 해당칼럼들을 제외한 상태로 x,y데이터를 분할해 준다.
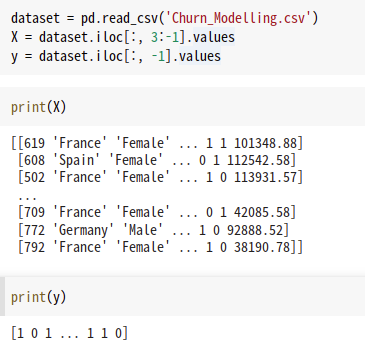
여기서의 y는 마지막칼럼(EXited) 으로 고객의 이탈 유무를 우리가 예측하고 싶기에 y데이터에 할당했다고 생각하면 된다.
Encoding categorical data
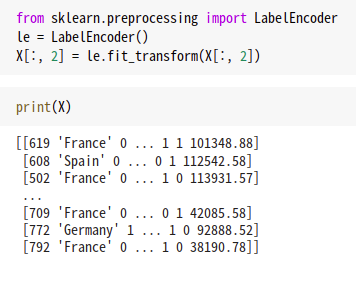
성별을(2번 인덱스) 인코딩 하기위해서는 le objects를 사용하게 되는데, 라벨인코더 클래스의 인스턴스로 성별에 대한 인코딩을 수행해주게 된다.
One Hot Encoding the "Geography" column
원-핫 인코딩이 필요한 이유는 scikit-learn에서 제공하는 머신러닝 알고리즘은 문자열 값을 입력 값으로 허락하지 않기 때문에 모든 문자열 값들을 숫자형으로 인코딩하는 전처리 작업(Preprocessing) 후에 머신러닝 모델에 학습을 시켜야 하기때문에 우리는 Geography(국가)를 원-핫 인코딩을 해야하는 것이다.
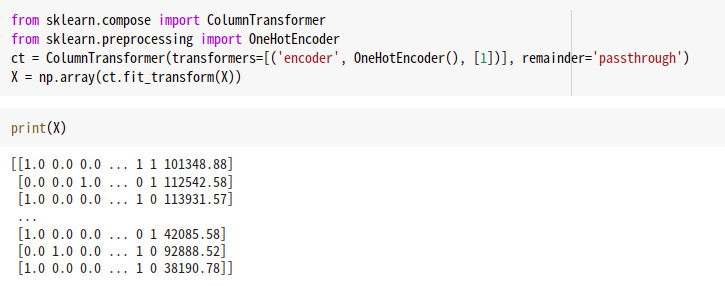
위처럼 sklearn에서 OneHotEncoder를 임포트하여 적용후 np array형태로 바꿔주기만 하면 간단히 작업을 마칠 수 있다.
Splitting the dataset into the Training set and Test set

늘 헷갈리지만 python은 test set을 명시해야하고, R은 training set을 명시해야 한다.
Feature Scaling
Feature Scaling이란 Feature들의 크기, 범위를 정규화시켜주는 것을 말하는데 잠깐 예를 들어보자면 수능영어에서의 100점과 토익에서의 100점은 하늘과 땅차이라는것을 우리는 알 수 있다. 왜냐하면 두 시험의 만점의 기준이 다르다는 것을 우리는 사전에 알고 비율로 치환하여 생각하기 때문이다. 이를 컴퓨터는 알 수 없다.(우리가 알려주기 전까지는) 그래서 해당하는 분야에서의 범위를 정규화 시키는 기준을 학습시키는 단계가 바로 Feature Scaling이라고 생각하면 된다.

위처럼 StandardScaler를 사용하여 간단히 수행할 수 있다.
