
어간 추출(Stemming)과 표제어 추출(Lemmatization)
정규화 기법중 코퍼스에 있는 단어의 개수를 줄일 수 있는 기법으로는 Stemming과 Lemmatization이 있다. 자연어 처리에서의 정규화는 항상 주어진 코퍼스로 부터 복잡성을 줄이는 일이라고 생각하자!
Lemmatization
표제어추출은 단어들로부터 표제어를 찾아가는 과정을 말하게 된다. am,are,is가 be를 표제어로 갖는걸 예로 들수 있다.
표제어 추출을 하는 가장 세분화된 방법은 단어를 형태학적 파싱하는 과정으로 볼수 있다. 형태소는 어간과 접사를 아울러 말하는 단어이다.
어간
단어의 실질적 의미를 담고있는 부분
접사
단어에 추가적인 의미를 주는 부분.
이 두가지를 나누는 것이 형태학적 파싱 작업이다.
NLTK에서는 표제어 추출을 위한 도구 WordNetLemmatizer를 지원하는데 이를 통해서 간단히 실습해보며 익혀보도록 하자!
실습
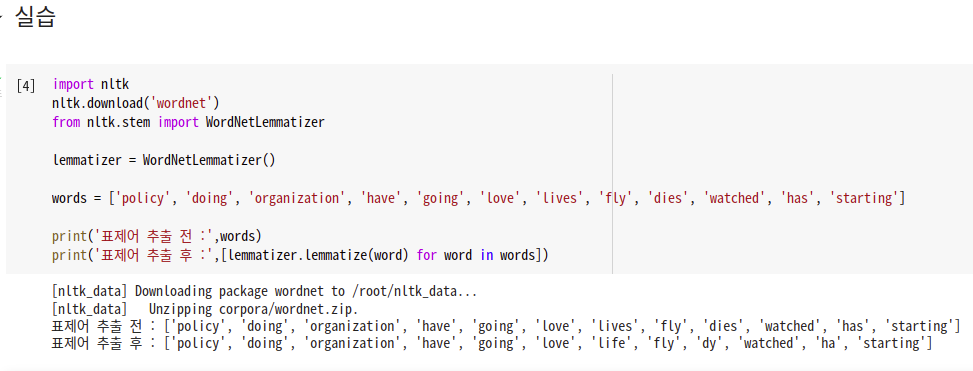
다소 부정확한 단어를 추출해 내는것을 볼수 있다. 이는 lemmatizer가 본래 단어의 품사정보를 알아야만 정확한 결과를 얻을수 있기 때문이다.
WordNetLemmatizer는 입력으로 단어가 동사 품사라는 사실을 알려줄 수 있다. 다시 한번 품사정보를 알려주고 난뒤 결과를 출력해 보도록 하자!

정확하게 추출되는 것을 알 수 있다!
Stemming
어간(Stem)을 추출하는 작업을 어간 추출(stemming)이라고 한다! 어간 추출을 할 때는 알고리증을 사용하는데 알고리즘이라는 단어에서 알수 있듯이 정해진 규칙에 기반하여 실행되다 보니 그리 섬세한 작업은 아니다! 예제를 보고 쉽게 이해해 보도록 하자!
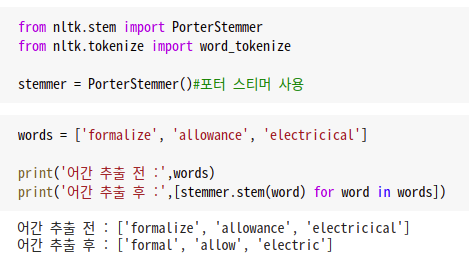
위의 예제에서 알 수 있듯이
ALIZE → AL
ANCE → 제거
ICAL → IC 이러한 규칙을 따르는걸 알 수 있다!
Stemming과 Lemmatization 차이 정리
Stemming am → am the going → the go having → havLemmatization
am → be
the going → the going
having → have
