
오늘은 필요성을 느껴 입문하게된 R언어로 Data preprocessing을 블로깅 하려 한다.
R studio
R언어를 배우게 되면서 R studio도 같이 설치를 해보았는데 ui자체가 다소 난해하다는 느낌이 들지만 이또한 사용하다보면 익숙해질거라 생각이 들어 우분투버전으로 설치후 R언어로 datapreprocessing을 시작해 보았다.
dataset load하기
dataset을 로드하는건 너무나도 간단하였다.
files -> 본인이실행할 dataset을 작업디렉토리로 설정

여기 environment에 내가 사용할 dataset을 지정해 주기만 하면 가능했다.
dataset = read.csv('Data.csv')
이렇게 작성후 코드를 실행하는 방법이 조금 특이했다고 느겼는데 커맨드 후 alt+enter를 누르면 해당 커맨드라인의 코드가 실행되는 식이였다. 아직 낯설어서 버벅대기는 하였지만 이또한 반복하다보면 금방 익숙해질거라 생각한다.
누락된 데이터 채워주기
R언어에서의 index는 1부터 시작한다는 점은 python이 0부터 시작하는 것과 달라 흥미롭게 다가왔다. 누락된 데이터를 어떻게 처리할까 생각을 하다가 해달 컬럼의 평균값을 누락된칸에 채워주는 방식을 선택하였다. 해당하는 과정이 나의첫 R언어 프로그래밍이였다!

ifelse 함수에는 세게의 피라미터가 필요한데 그 순서는
- if조건문
- if조건문이 참일때 실행할 값
- if조건문이 거짓일때 실행할 값
이렇게 3가지의 파라미터가 필요하다.
달러사인 을 이용하여 해당하는 csv파일의 colum에 접근한뒤 is.na 함수가 누락된값을 찾아낸다면, ave라는 함수로 해당하는 colum의 평균값을 구한뒤 na.rm = TRUE라는 구문으로 해당한값(누락된 데이터를 제외한 평균값)으로 채워주게 된다. 그리고 3번째 조건인 거짓일때는 즉 '해당하는 값이 누락되지 않은 열에대한 실행부'는 dataset$Age 즉 그대로 유지하도록 해주면 된다.

datasetAge를 datasetSalary로 바꿔주면 똑같이 Salary의 누락된 값도 처리할 수 있다.
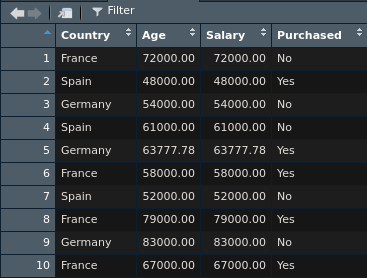
(누락된값이 평균값으로 채워진 dataset)
범주형 데이터 인코딩(text to number)
다시 데이터셋을 살펴보면 Country Colum과 Purchased Colum은 text로 되어있기에 인코딩이 필요하단걸 알 수 있다.
우리는 'factors'함수로 범주형 변수를 숫자로 바꿔줄 것인데 R언어를 배워본 사람들이라면 절대모를수 없을만큼 실용적인 함수이다.
우선Country colum부터 인코딩을 시잘하려면 해당 열을 가져와야한다.

이렇게 입력후 f1을 누르면 Factors에대한 설명이 나오는데
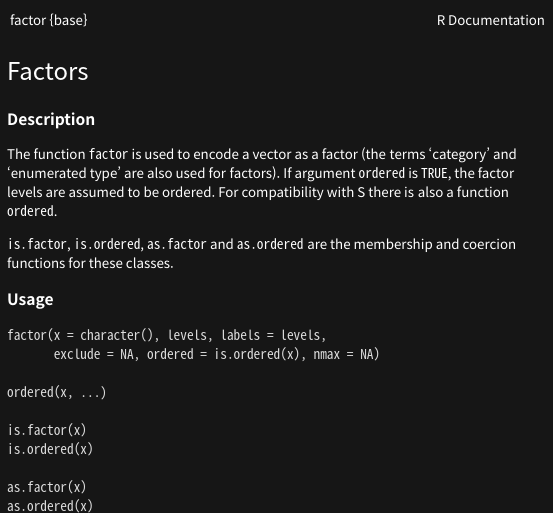
세가지 argument가 필요하다 그 세가지의 순서는 다음과 같다.
- 바꾸고 싶은데이터
- levels
- labels
위를 기반으로 코드를 작성해보면.
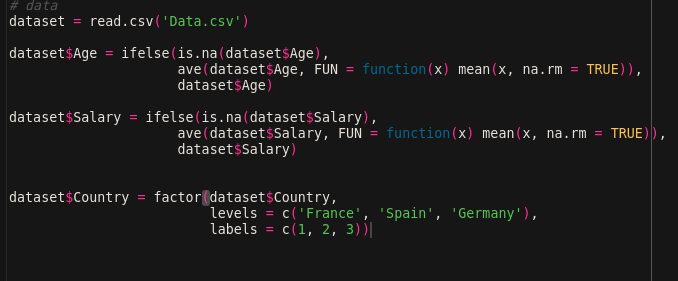
이와같이 작성할 수 있고 이코드를 실행시켜보면
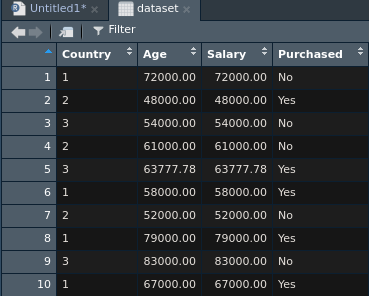
이와같이 Country Colum이 인코딩 된것을 확인할 수 있다.
똑같이 Purchase colum에도 코드를 적용하면

이렇게 작성후 코드를실행하면
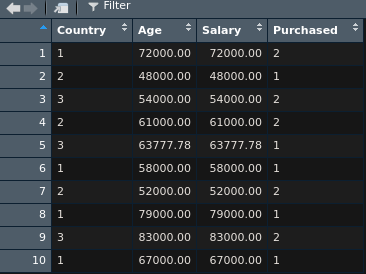
이와같이 purchase도 인코딩 된것을 확인할 수 있다.
데이터 분할
데이터셋 분할과정에서 caTools라는 패키지가 필요한데 위와같이 다운로드후 활성화를 진행하면 바로 사용할 수 있다.

이렇게 set.seed라는 함수로 seed를 설정하고 위와같은 syntax로 훈련에쓸 데이터셋의 비율을 작성해주면(파이썬에서는 테스트에 사용할 데이터비율을 작성해야하는 차이점이 있다.) 콘솔창에서 split을 입력시 10개의 출력값이 나오게 된다.
 TRUE는 관측값이 훈련세트에 간다는 것을 뜻하고, FALSE는 관측값이 테스트 세트로 간다는 것을 뜻하게 된다.
TRUE는 관측값이 훈련세트에 간다는 것을 뜻하고, FALSE는 관측값이 테스트 세트로 간다는 것을 뜻하게 된다.

이렇게 두줄만 작성하고나서 실행을시키고 나면
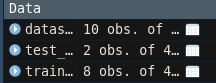
이처럼 학습용데이터와 검증용 데이터로 분할된 것을 확인할 수 있다.
피처 스케일링
피쳐스케일링이 가장 간단하게 느껴졌었다.

이렇게 age와 salary를 정규화할 것이기 때문에 각각의 데이터셋에 [,2:3]라는 범위를 추가해주고 (R은 index가 1부터 시작하기때문에) 실행을 하고나면
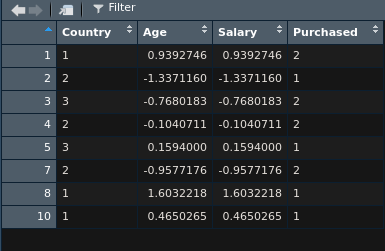
이처럼 정규화가 된것을 확인할 수 있다.
