
오늘은 지난 블로깅에 이어 한번더 복습하는 개념으로 실습해 보려한다!
준비물 챙기기

지난시간과 동일하게 selenium으로 진행할 것이기에 import를 해온다!
크롤링할 페이지를 띄우자!
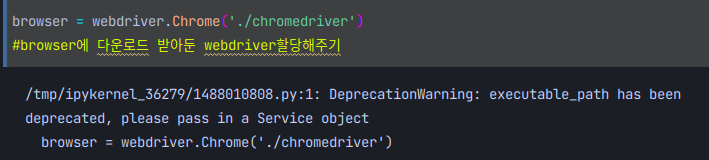
로컬에서의 chromedriver의 경로를 적어주고 그걸 Chrome으로 열겠다는걸 알려주는 구문이다. 사실상 여기 까지는 이해 보다는 손이 기억하는 기분이다.
크롤링할 사이트 지정해주기

url이라는 변수에 우리가 오늘 크롤링할 사이트를 할당해주면
해당사이트에 get 방식으로 접근이 가능하다!
해당 페이지의 source를 담아주자!
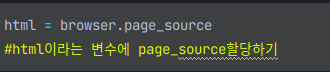
이렇게만 하면 html의 type은 str이 된다고 했다.

html은 html로 읽어야 하니까

이렇게 하고난뒤 다시 html의 타입을 찍어보면
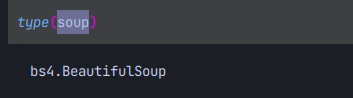
이렇게 되면 프로그램이 str이 아닌 html단위로 읽어오기 시작한 것이다!
select() 기본문법
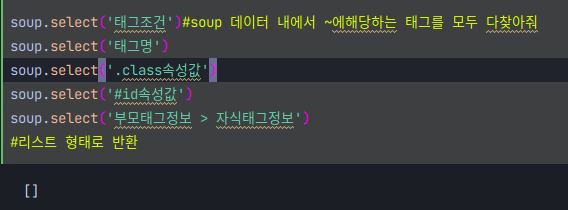
제목을 가져와보자!
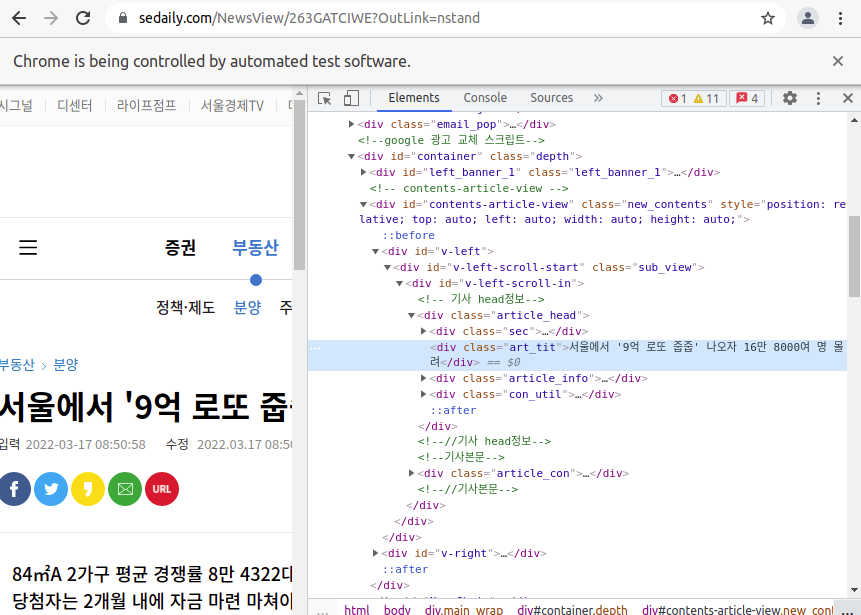
크롤링에는 정말로 정답이 없기때문에 해당하는 페이지의 형식에 맞게 내가 가져오고 싶은 정보를 가져오면된다!
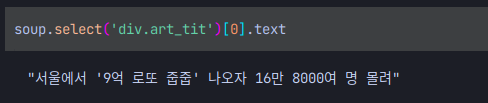
img를 가져오고 싶어요!
서울경제 라는 부분을 가져오고 싶었는데 해당하는 태그는 img태그로 이루어져 있다. 해당하는 img url을 가져오려고 우리가 평소에 하던대로 해본다면

왜 빈스트링이 나오는 걸까???
그 이유는 바로
.text의 작동원리에 있다
.text가 우리의 예상처럼 작동하지 않은 이유는 바로 img태그에는 닫는 태그가 없기 때문!
html의 기본 문법에 대해서 안다면 img태그는 닫는 태그가 없다는걸 알고 있을 것이다. 하지만 .text는 <태그>anything</태그> 이렇게 <태그>,</태그> 를 기준으로 안에있는 텍스트만 뽑아오기에 닫는 태그가 없는 img 태그는 ' ' 이처럼 빈스트링으로 출력이 된것이다.
그렇다면 우리는 img태그의 url은 평생 크롤링하지 못하는 걸까?
너는 계획이 다 있구나

사실 우리는 태그.text로 계속 해당하는 정보에 접근했지만 다른 방법으로 접근 할 수 밖에 없는 예를 들어 자연스럽게 소개하기 위함 이였다!바로
태그['속성명']
이렇게도 해당하는 정보에 접근 할 수 있다는걸 소개하고 싶었다! 바로 적용해보도록하자!
 src가 속성명이니 src로 접근을 해보자!
src가 속성명이니 src로 접근을 해보자!
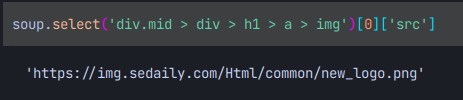
우리가 원하던 img의 url을 가져 오는데 성공하였다!
오늘은 이처럼 태그의 특성에 따라 일어날수있는 예외처리를 어떻게 처리하면 좋을지 함께 고민하고, 결국 원하던 img의 url을 가져오는 시간을 가져보았다!
글을 마치며
사실 실력있는 개발자와 그저그런 개발자는 디버깅을 하는 방법론에서 가장 큰 차이를 보이는것 같다는 생각이 든다. 개발을 하다보면 사실상 개발을 한다는 느낌 보다는 "디버깅 한다"라는 기분이 들 때가 정말 많은데, 그럴때 마다 눈감고 디버깅(대충 이거겠지~) 하기보다는 문제의 발생원인 , 해결방법등을 직접 생각해보며 개발을 이어나가는 습관을 가지려고 노력하는데. 오늘도 그러한 방법으로 접근해 보았다.
"왜 .text가 안먹지? 이러면 나온다고 했는데!"
라는 생각 보다도
".text의 작동원리가 어떻게 되길래 빈스트링이 출력되지?"
라는 식으로 생각하면서 개발을 하고있다는 말을 하고싶은 것이다. 절대로 자랑이 아닌 우리모두가 가져야할 마음가짐 아닐까 생각을 한다. 정말 정말 개발의 95%는 디버깅 이고, 5%는 나의 키보드를 내리치지 않는 인내심이라 생각하고 개발을 하는 사람으로써 모두에게 추천하고 싶은 방법이다. 우리모두 대한민국이라는 국적 으로써 세계에 내놔도 부끄럽지 않을 개발자가 되기를 소망하며 오늘 포스팅을 마치겠다!
