
자료 출처
Operating Systems: Three Easy Pieces
https://pages.cs.wisc.edu/~remzi/OSTEP/
위키피디아
개요
파일 시스템이란?
컴퓨터에서 파일이나 자료를 쉽게 발견 및 접근할 수 있도록 보관 또는 조직하는 체계(자료구조, 방법)를 가리키는 말이다.
파일 시스템은 통상 하드 디스크나 SSD, CD-ROM 같은 실제 자료 보관 장치를 사용하여 파일의 물리적 소재를 관리하는 것을 가리키나, 네트워크 프로토콜(NFS, SMB, 9P등)을 수행하는 클라이언트를 통하여 파일 서버 상의 자료로의 접근을 제공하는 방식이나, 가상의 형태로서 접근 수단만이 존재하는 방식(procfs 등)도 파일 시스템의 범위에 포함될 수 있다.
쉽고 간단한 file system overview
https://www.youtube.com/watch?v=KN8YgJnShPM&ab_channel=CrashCourse
파일이 뭐야?
컴퓨터에서 의미가 있는 정보를 담은 논리적인 단위
🙄파일 시스템?
파일 시스템이란 영속 저장 장치(persistent storage)에 해당하는 디스크(disk) 형식의 저장 장치들(하드 디스크 드라이브 or SSD)들에 담기는 영구적인 정보들을 다루는 순수한 소프트웨어다.
파일 시스템의 주 역할
- 파일의 할당 : 새로 생성할 파일을 디스크에 할당하는 방법
- 파일의 접근 : 사용자가 원하는 파일을 디스크에서 접근하는 방법 제공
- 파일의 보호 : 파일의 접근 권한을 관리
- 파일의 일관성 : 파일의 내용이 손상되지 않도록 보장
파일 시스템은 목적에 따라 다양성를 띈다. 간단한 예시로 대표적인 운영체제들 모두 다른 파일 시스템을 사용한다. 윈도우는 NTFS, 맥은 APFS, 리눅스는 ext4. 파일 시스템 설계의 재밌는 점은 자유롭다는 것이다.
파일 시스템의 두 가지 핵심 요소
1. 자료 구조
자신의 데이터와 메타데이터를 관리하기 위해 디스크 상에 어떤 종류의 자료 구조 있어야하나.
2. 접근 방법(access method)
파일에 접근하는 시스템 콜과 파일 시스템의 자료구조와의 관련성, 특정 시스템 콜에 대응하는 자료구조, 그리고 이 모든 과정이 동작하는 데 있는 효율성.
파일 시스템의 전체 구성
우선 디스크를 블럭(block)들로 나눈다. 이를 나눈는 이유는 가상 메모리의 page과 유사하다. (블록, 섹터 단락 참조)
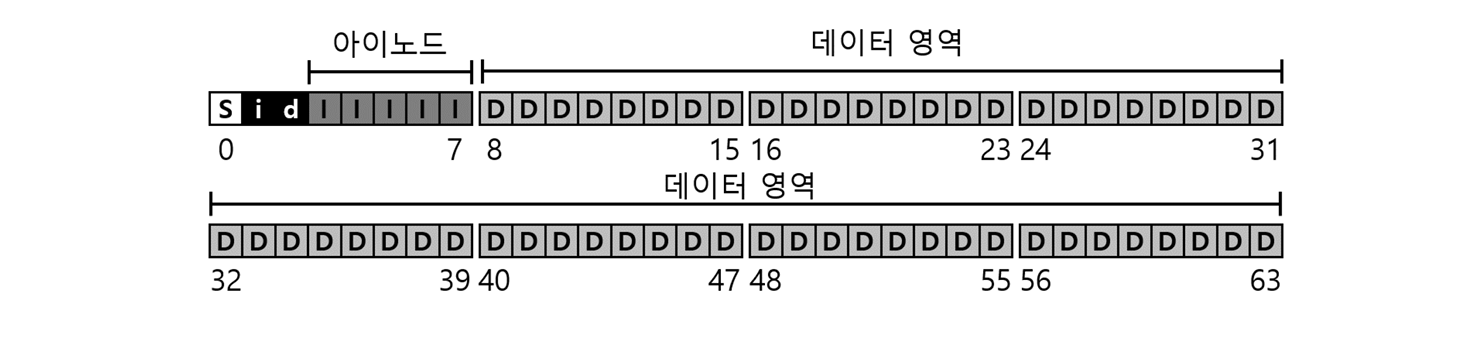
64개의 작은 블록들로 이루어진 디스크를 가정했을 때의 그림.디스크 공간은 총 세 가지 영역으로 나눈다.
- 데이터 영역
사용자 데이터가 있는 디스크 공간으로 대부분의 공간이 이로 이루어져있다. (또한 그렇게 되어야 한다.)
- 아이노드 테이블 영역
파일 시스템의 메타데이터를 저장하는 자료구조로 아이노드를 사용할때, 아이노드들을 배열 형태로 저장하는 영역이다. 아이노드는 index node의 약자다.
- 그 외. 슈퍼셀, 비트맵
파일 시스템 전체의 정보를 담는 슈퍼 블럭과(ex 파일 시스템에 몇개의 아이노드와 데이터 블록이 있는지, 아이노드 테이블은 어디서 시작하는지 등등) , 블록이 사용 중인지 아닌지를 표현하기 위한 할당 구조(allocation structure)인 아이노드 비트맵, 데이터 비트맵 등이 있다.
메타 데이터란?
파일 시스템의 경우, 아이노드에는
1. 파일의 종류 (ex 일반 파일, 디렉터리 등)
2. 크기
3. 할당된 블럭 수
4. 보호 정보 (파일의 소유자, 접근 권한등)
5. 시간 정보 (접근 및 변경 시각등)
6. 데이터 블럭이 디스크 어디에 존재하는지 (ex 포인터의 일종)
간단히 말해 데이터를 위한 데이터
파일 시스템을 마운트할 떄, 운영체제는 우선 슈퍼블럭을 읽어들여서 파일 시스템의 여러가지 요소들을 초기화하고, 각 파티션을 파일 시스템 트리에 붙히는 작업을 진행한다.
아이노드 설계
🛑아이노드는 자료구조다. 데이터와 관련 내용들을 효율적으로 읽고 쓸 수 있다면, 어떤 방식도 사용가능하다. 파일 시스템 소프트웨어는 손쉽게 변경 가능하다.
디스크 파일들의 메타 데이터를 저장하는 자료구조인 아이노드를 설계 시 가장 중요한 결정 중 하나는 데이터 블록의 위치를 표현하는 방법이다.
|
간단한 방법은 포인터 기법을 이용하는 것이다.
|
이 때 포인터의 개수에 따라 파일 크기가 제한된다. (포인터의 개수)*(블럭 크기)
블럭이 4kb, 디스크 주소를 4바이트로 가정한다. - 직접 포인터 (direct pointer)
각 포인터는 파일의 디스크 블럭 하나를 가리킨다.
- 간접 포인터 (indirect pointer)
간접 포인터가 가리키는 블럭에는 데이터 블럭을 가리키는 포인터들이 저장된다.
한 블럭에 총 1024개의 주소 저장. 최대 파일 크기 = 1024 * 4kb = 4096 kb- 이중 간접 포인터 (double indirect pointer)
간접 포인터가 가리키는 블럭에는 간접 포인터들이 저장.
최대 파일 크기 = 1024 * 1024 * 4kb = 4096 mb = 4GB- 삼중 간접 포인터 (triple indirect pointer)
최대 파일 크기 = 1024 * 1024^2 * 4kb = 4096 gb = 4TB이를 통해 디스크 블럭들은 일종의 트리 형태로 구성된다. 이를 멀티 레벨 인덱스 기법이라 한다.
일반적으로 사용되는 파일 시스템인 Linux의 ext2[Poi97], ext3, NetApp의 WAFL등의 많은 파일 시스템이 멀티 레벨 인덱스를 사용한다.
보면 할 수 있다 싶이 트리의 형태가 매우 편향적이다. 파일 크기가 클 경우, 파일 끝 부분의 블럭들은 포인터를 세번 따라가야한다.

많은 연구자들이 파일 시스템의 사용 형태를 분석해서 발견한 아주 중요한 '사실'이 있다.
🛑대부분의 파일의 크기는 작다
대부분의 파일들이 작다면, 작은 파일들을 빨리 읽고 쓸 수 있도록 파일구조를 설계해야한다.
익스텐트(extent) 기반의 접근법
익스텐트는 단순히 디스크 포인터와 길이 (블럭 단위)로 이루어져있다. 파일의 모든 블럭에 대해서 포인터를 써야하는 대신에, 디스크 상의 한 파일의 위치를 가리키기 위한 하나의 포인터와 길이만 표현하면 된다. 다만 디스크 상의 충분히 크고 연속적인 비어있는 공간을 갖는 것이 제한적이기에 익스텐드 기반의 파일 시스템은 하나 이상의 익스텐트를 갖는 것을 허용한다.
포인터 VS 익스텐트
포인터 기반의 접근법은 가장 자유도가 높지만 각 파일당 많은 양의 메타데이터를 사용한다.
익스텐트 기반의 접근법은 자유도가 낮은 대신의 좀 더 집약되어있다. 디스크에 여유 공간이 충분히 있고 파일들을 연속적으로 배치할 수 있을 때 잘 작동한다.
디렉터리 구조
간단한 파일시스템에서 디렉터리는 다른 많은 파일 시스템에서 그러하듯이 간단하다.
디렉터리는 항목의 이름, 아이노드 번호 쌍의 배열로 구성되어 있다. 디렉터리의 데이터 블럭에는 문자열과 숫자가 쌍으로 존재하며, 문자열 길이에 대한 정보도 있다.

. 디렉터리는 현재 디렉터리, ..는 부모 디렉터리를 가리킨다.
디렉터리는 자신의 데이터 블록을 갖고 있으며, 이들의 블럭 위치는 일반 파일과 마찬가지로 아이노드에 명시되어있다.
빈 공간의 관리
파일 시스템은 아이노드와 데이터 블럭 사용 여부를 관리 해야한다. 그래야 새로운 파일이나 디렉터리를 할당할 공간을 찾을 수 있다. 빈 공간 관리(free space management)는 모든 파일 시스템에서 중요하다.
빈 공간을 관리하는 여러가지 방법이 있는데 그 중에 하나가 비트맵이다. 초기의 파일 시스템들은 프리 리스트를 사용하여 슈퍼블럭 안의 한 포인터가 첫번째 프리블럭을 가리키도록 하였다. 현대의 파일 시스템은 좀 더 정교한 B-tree의 일종과 같은 자료구조를 사용한다.
실행 흐름: 읽기와 쓰기
파일 시스템이 어떻게 동작하는지 이해하는 것은 중요하다. 이러한 실행 흐름(access path)를 간단한 파일 시스템의 경우 아래의 그림과 같이 행동한다.

경로명을 따라가는 것(traverse)은 항상 파일 시스템의 루트 디렉터리에서 시작한다.
파일 시스템이 디스크에서 가장 먼저 읽을 것은 루트 리렉터리의 아이노드다.
그 후 open의 경우 아이노드->데이터블럭->다음아이노드->데이터블럭의 연속
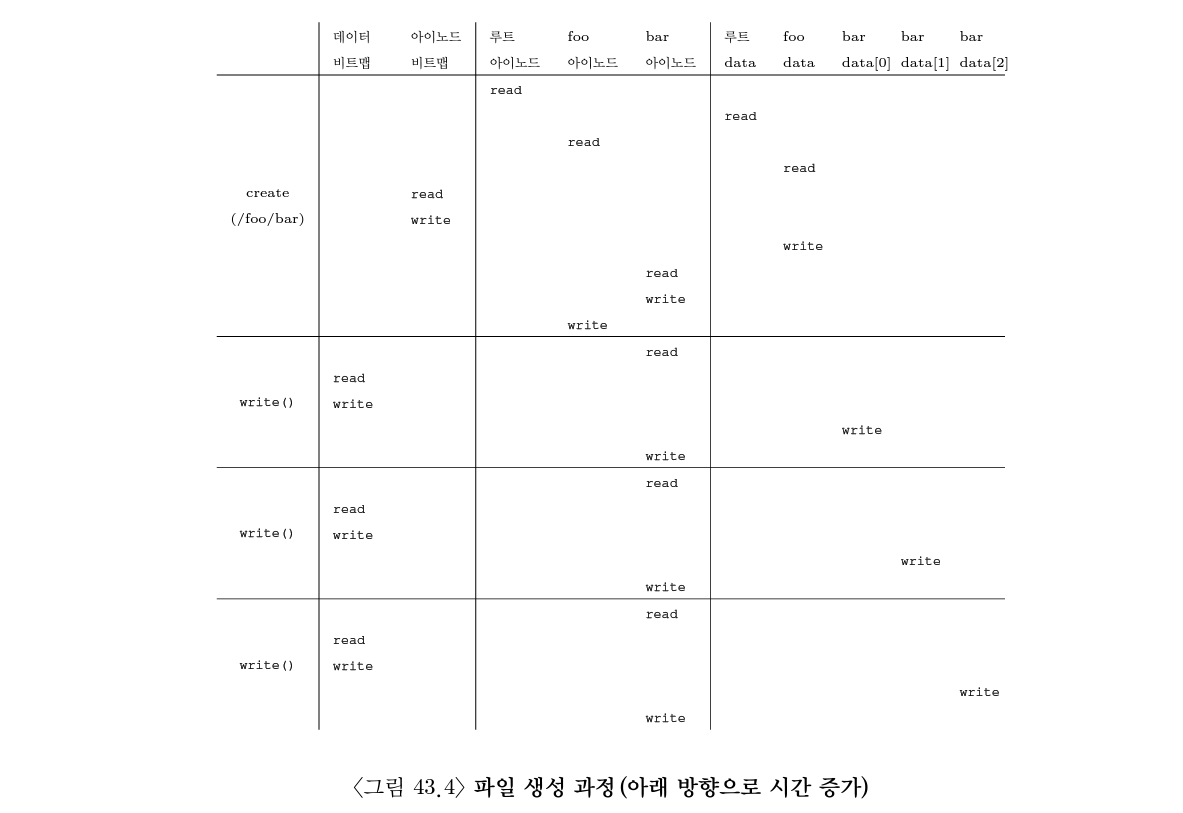
여담: FAT (file allocation table)
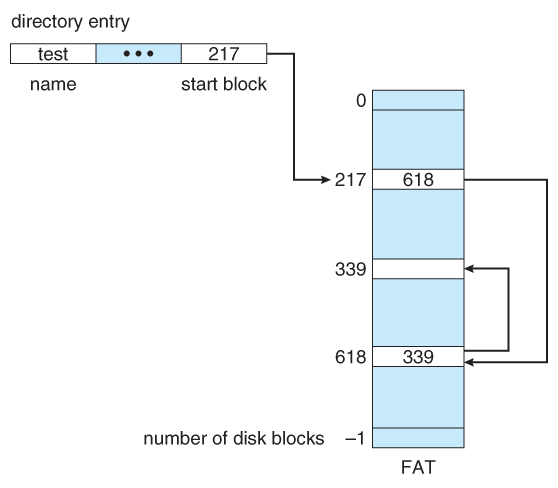
아이노드를 설계할 때 연결 리스트(linked list)를 사용할 수도 있다. 아이노드 안에 다수의 포인터를 두지 않고 파일의 첫 번쨰 블럭을 가리키는 포인터만 하나 둔다. 하지만 링크 기반의 파일 블럭 구성은 특정 워크로드에 대해서 성능이 좋지 않을 수 있다.
링크드 리스트 기반 구성의 성능을 개선하기 위해, 데이터 블럭 내에 다음번 블럭의 위치를 저장하지 않고, 링크드 리스트의 포인터 정보들만 모아 테이블로 관리 할 수 있다. 그러면 이 테이블을 메모리에 상주 시킬 수도 있고, 각 블럭을 따로 읽는 연산은 발생하지 않는다. 테이블의 항목은 데이터 블럭 D의 주소로 인덱스 된다. 각 항목의 내용은 D의 다음 블럭을 가리키는 포인터, 즉 파일의 D 다음에 오는 블럭의 주소를 저장한다. 다음 포인터를 저장하는 테이블을 사용하면 연결식 할당 방법에서도 임의의 파일 접근을 효율적으로 할 수 있게 된다.
이러한 테이블이 그 유명한 FAT (file allocation table) 파일 시스템의 기본 구조다. 하지만 아이노드가 없기 때문에 파일의 메타데이터가 디렉터리 파일에 저장되어 하드링크를 만드는 것이 불가능하다. 하지만 가장 광범위하게 사용되었던 파일 시스템이다.
fat 설명글
https://velog.io/@tpclsrn7942/FAT-FAT-FILE-SYSTEM
💵캐싱(caching) 과 버퍼링
앞의 예제에서 볼 수 있듯이 파일을 읽고 쓰는 것은 많은 I/O를 발생시킨다. 이는 컴퓨터의 전체 성능에 중요한 영향을 미친다.
성능 개선을 위해 대부분의 파일 시스템들은 자주 사용되는 블럭들을 메모리(DRAM)에 캐싱한다.
앞의 예제에서 보다 싶이 캐싱을 하지 않는다면 파일을 여는 동작은 디렉터리르 레벨마다 최소한 두번의 읽기가 필요하다.
초기의 파일 시스템에서는 자주 사용되는 블럭들을 저장하기위해 캐시를 도입하였다. LRU와 기타 다른 캐시 교체 정책들이 캐시에 어떤 블럭들을 남길지 결정해야한다. 이 고정 크기의 캐시는 일반적으로 부팅 시에 할당되며 전체 메모리의 약 10%를 차지한다.
하지만 고정 크기의 캐시를 사용하는 정적 기법은 낭비가 많다.
현대의 시스템은 동적 파티션을 사용한다. 현대의 많은 OS들은 가상 메모리 페이지들과 파일 시스템 페이지들을 통합하여 일원화된 페이지 캐시(unified page cache)를 사용한다.
정적 대 동적 파티션 이해하기
서로 다른 사용자 간의 자원을 나누는데 있어서 정적 파티션(static partitioning)과 동적 파티션(dynamic partitioning)을 사용할 수 있다.
|
정적 파티션은 고정된 크기로 자원을 한번만 나눈다. 동적 방식은 좀더 유동적이라 땡에 따라 다른 양의 자원을 나누어 줄 수 있다.
각 접근법은 각자의 장점이 있다.
정적 파티션
각 사용자가 자원의 일부를 나누어쓰도록 하기 때문에 일반적으로 예상가능한 성능을 얻을 수 있고, 구현하기 쉽다.
동적 파티션
활용률 측면에서 더 좋기는 하지만, 구현하기에 더 복잡할 수 있다. 사용자가 갖고 있던 놀던 자원을 다른 사용자에게 줬디만, 실제로 필요로 할 때에는 돌려받기 위해서 오랜 시간이 걸릴 수 있다.
언제나 그렇듯 최선의 방법은 없다.
🎆쓰기 버퍼링
쓰기는 데이터의 영속성을 유지하기 위해 수정된 해당 블럭들을 메모리에서 디스크로 내려야 한다. 쓰기 버퍼링은 캐시가 디스크에 쓰기 시점을 연기하는 역할을 한다.
쓰기 버퍼링 장점
- 다수의 쓰기 작업들을 적은 수의 I/O로 일괄처리(batch) 할 수 있다.
- 여러 개의 쓰기 요청들을 모아둠으로써 다수의 I/O를 스케줄하여 성능을 개선할 수 있다.
대부분의 파일 시스템들은 쓰기 요청을 메모리에서 약 5초에서 30초 정도동안 버퍼링한다. 여기서 문제가 생기는데 디스크에 쓰기 요청이 기록되기 전에 시스템이 크래시되면 내용은 손실된다.
이러하기에 데이터의 영속성과 시스템의 성능은 동전의 양면과 같다.
영속성을 보장하기위해 fsync()등의 캐시를 사용하지않는 direct I/O 인터페이스를 사용하거나 디스크 인터페이스를 사용하여 파일 시스템을 건너뛰고 직접 디스크에 기록하는 경우가 있다.
🧱블록, 섹터

섹터는 하드디스크에서 물리적으로 저장하는 단위를 말한다. 크기는 거의 대부분 512byte 입니다.
따라서 파일 시스템이 디스크에 접근 할 때 사용되는 최소 단위이기도 하다. (바이트 단위의 접근은 불가하다.)
블록은 파일시스템에서, 파일이 저장되는 단위를 말한다.
섹터크기의 정수배이며, 파일시스템의 크기에 따라서 자동으로 결정되지만, 사용자가 직접 결정할 수 도 있습니다.
블록, 섹터는 가상 메모리의 page, 물리 메모리의 frame과 아주 유사하다.
일반적으로 4kb 정도의 크기의 블록으로 디스크를 나눈다.
파일 시스템은 일반적으로 크기가 일정한 블록들의 배열에 접근할 수 있는 자료 보관 장치 위에 생성된다.
이러한 배열들을 조직함으로 파일이나 디렉터리를 만들며 어느 부분이 파일이고 어느 부분이 공백인지를 구분하기 위하여 각 배열에 표시를 해 둔다.
또한 자료를 '클러스터' 또는 '블록'이라고 불리는 일정한 단위(이것은 각 디스크 배열들에 대한 식별할 수 있는 번호를 제공하는데 통상 1부터 64까지가 쓰인다)에 새겨 넣는데 이것이 바로 파일 하나가 필요로 하는 디스크의 최소 공간이다.
📀저장 장치
각각의 저장 장치들은 용량, 비용, 접근시간에 비례하는 계층 구조를 가진다.
CPU 레지스터들은 가장 자주 이용하는 데이터를 보관
캐시 메모리는 작고 빠르며 CPU 부근에서 비교적 느린 메인메모리에 저장된 데이터와 인스트럭션들의 부분집합에 대한 준비 장소로 사용된다.
메인 메모리는 크고 느린 디스크들에 저장된 데이터를 준비하는데 사용.
디스크들은 네트워크로 연결된 다른 장치들의 디스크나, 반영구적인 데이터 보관을 위해 사용되는 하나의 컴퓨터 상에선 최하단의 계층이다.
메모리 계층구조는 잘 작성된 프로그램이 어느 특정 수준의 저장장치를 다음 하위 수준의 저장장치보다 좀 더 자주 접근하는 경향을 갖기 때문에 작동한다. 이를 지역성(locality)라고 한다.
프로그래머로서 우리들의 응용 프로그램 성능에 큰 영향을 주기 때문에 메모리 계층구조를 이해하는 것이 필요하다. 이 내용은 주로 캐시에 대한 것이고 이 페이지에선 다루진 않는다.
당신의 프로그램이 필요로 하는 데이터가 각각의 저장 장치에 저장되어있을때 접근 시간은?
CPU 레지스터 : 0사이클 (WOW)
캐시 : 4~75 사이클
메인메모리 : 수백 사이클
디스크 : 수천만 사이클!!!!
컴퓨터 기술 중의 대부분의 성공은 저장장치 기술의 엄청난 발전에 기인하기에 그만큼 중요한 영역이다!
📲랜덤 접근 메모리 (RAM - random access memory)
RAM이란 내부의 임의의 영역에 동일한 시간이 걸리게 접근 할 수 있는 휘발성 메모리다. (그래서 random이란 명칭을 부여받음)
RAM의 두가지 종류
- 정적 램 : SRAM
- 동적 램 : DRAM
SRAM은 캐시 메모리로 사용되며 CPU 칩 내부 혹은 외부에 장착된다.
DRAM은 메인 메모리와 그래픽 시스템의 프레임 버퍼로도 사용된다.
📲static RAM, SRAM
SRAM은 각 비트를 이중안정 (bistable) 메모리 셀(cell)에 저장한다.
이중안정 메모리 셀은 아래의 그림에 나온 역진자(inverted pendulum)와 유사하다.
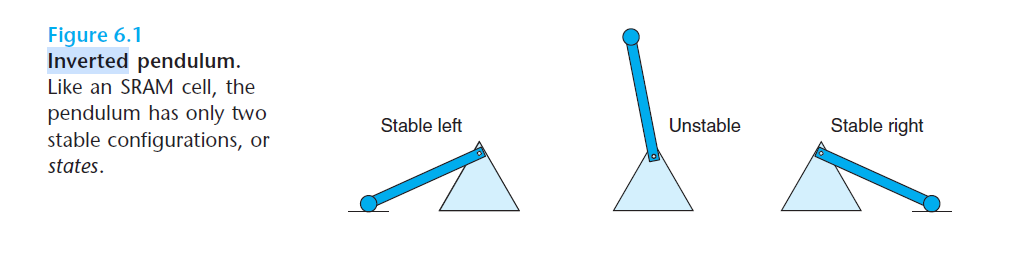
이중안정 본성으로 인해 SRAM 메모리 셀은 자신의 값을 전원이 공급되는 한 무한히 유지한다.
📲dynamic RAM, DRAM
DRAM은 각 비트를 전하로 캐패시터에 저장한다. 이는 매우 작고, DRAM 셀은 SRAM과 달리 외란에 대해서 매우 민감하다. 캐패시터 전압이 달라지면 다시 회복할 수 없다.
여러가지 원인의 누수전류는 DRAM 셀이 10~100밀리초 사이에 전하를 상실하게 한다.
- 하지만 다행스럽게도 나노초 클럭 사이클 시간으로 동작하는 컴퓨터에 대해서 이 유지시간은 꽤 긴 것이다.
따라서 DRAM의 메모리 시스템은 주기적으로 메모리의 모든 비트를 읽었다가 다시 써 주는 방식으로 리프레시 해야한다.
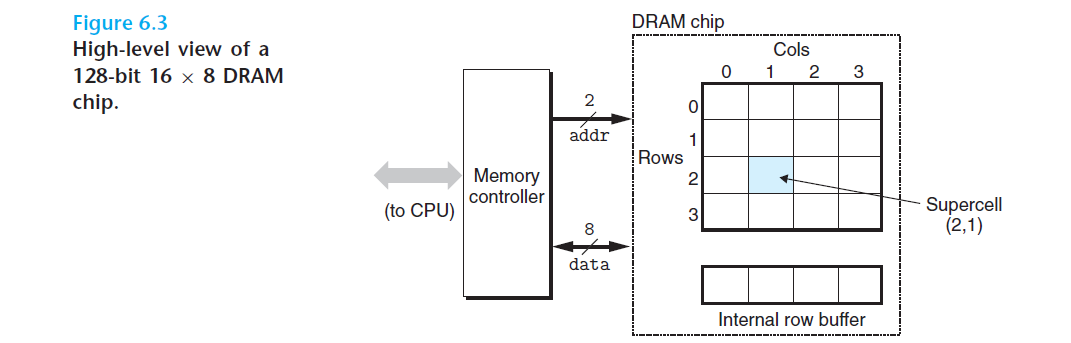
44 = 16 슈퍼셀, 각 슈퍼셀마다 8개의 셀, 총 168 = 128개의 셀 = bit 저장 가능한 dram 칩 그림.
DRAM 칩 내의 셀들은 d 개의 슈퍼셀들로 나누어지며 각각은 w개의 DRAM 셀들로 이루어진다.
d * w DRAM은 총 dw 비트의 정보를 저장한다. (앞뒤 둘다 곱이라는 거 겠지? 책에 진짜 이렇게 적혀있다..)
슈퍼셀 용어에 대하여
저장장치 커뮤니티는 DRAM 배열 원소에 대한 표준이름을 합의한 적이 한번도 없다.
DRAM 저장 셀이라는 용어를 중복해서 사용해 셀cell이라고 부르기도 하고, 워드라고 부르기도하고, 우리는 혼란을 피하기위해 슈퍼셀이라고 부른다.
메모리 모듈의 기본 아이디어
💿비휘발성 메모리
전원이 꺼져도 정보를 유지하는 메모리. 대표적으로 disk가 있다.
역사적인 이유로, 이들 모두를 ROM(read-only memory)라고 부른다.
비휘발성 메모리 종류
- PROM
- EPROM
- Flash memory
막간: SSD (solid state disk)
종래의 회전하는 디스크보다 빠르고 견고하며, 전력을 덜 소모하는 flash 기반 디스크 드라이브.
🎐메모리 접근하기
데이터는 '버스'라고 하는 공유된 전기회로를 통해서 프로세서와 DRAM 메인 메모리 간에 앞뒤로 교환된다.
CPU와 메모리 간의 매 전송은 버스 트렌잭션(bus transaction)이라고 부르는 일련의 단계를 통해서 이루어진다.
버스는 주소, 데이터 제어신호를 포함하는 병렬 선들의 집합이다.
제어 라인들은 트랜잭션들을 동기화하고 현재 어떤 종류의 트랜잭션이 수행되고 있는지 알려주는 신호들을 전송해준다.
읽기 트랜잭션 예:
movq A, %rax : 주소 A의 내용을 레지스터 %rax에 로드

쓰기 트랜잭션 예:
movq %rax, A : 레지스터 %rax의 내용을 주소 A에 기록.

💿디스크 저장장치
디스크는 엄청난 양의 데이터를 저장하는 대표적인 비휘발성 저장장치다. 하지만 정보를 읽는 속도가 SRAM, DRAM에 백만,십만배 느리다.
디스크의 구조
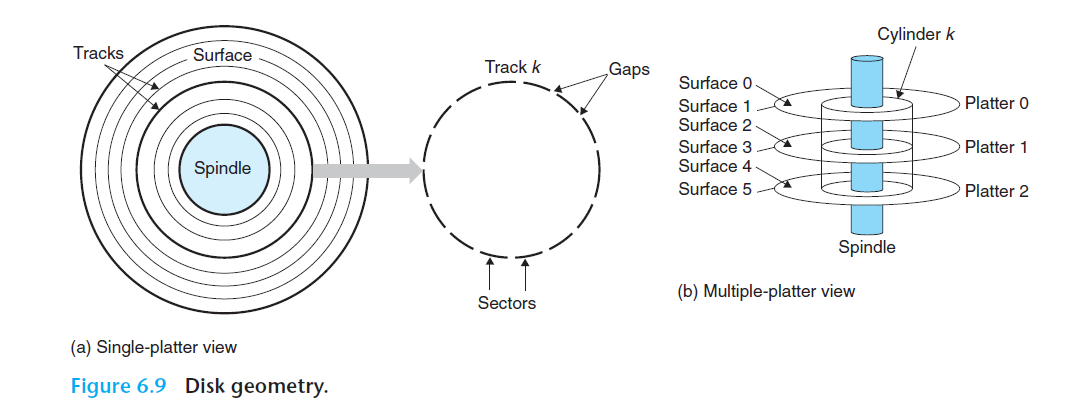
디스크들은 원판(platter)들로 구성된다. 각 원판들은 두개의 옆면 즉 표면으로 이루어져 있으며 자성을 띈 기억 물질로 코팅되어있다.
원판 중심부에 있는 최전하는 축(spindle)은 원판을 고정된 회전율로 회전시켜준다. 대략 분당 5400회에서 15000회의 RPM을 가진다.
디스크는 일반적으로 한 개 이상의 원판들을 갖는다.
각 표면은 트랙이라고하는 여러개의 동심원들로 이루어져 있다. 각 트랙은 섹터들의 집합으로 나누닌다. 섹터들은 아무 데이터도 기록되지 않는 갭으로 분리되어있다. 갭은 섹터를 식별하는 포맷팅 비트를 저장한다.
여러개의 디스크를 조립한 전체를 종종 디스크 드라이브라고 부른다.
다중 원판 드라이브를 실린더라는 용어로 설명한다. 실린더란 축의 중심으로부터 동일한 거리를 갖는 모든 표면의 트랙들을 합한 것을 말한다.
그림의 경우, 실린더 k는 여섯 개의 트랙들을 합친 것을 말한다. (디스크 세개 표면 두개 총 6개, 한 실린더에)
디스크의 동작
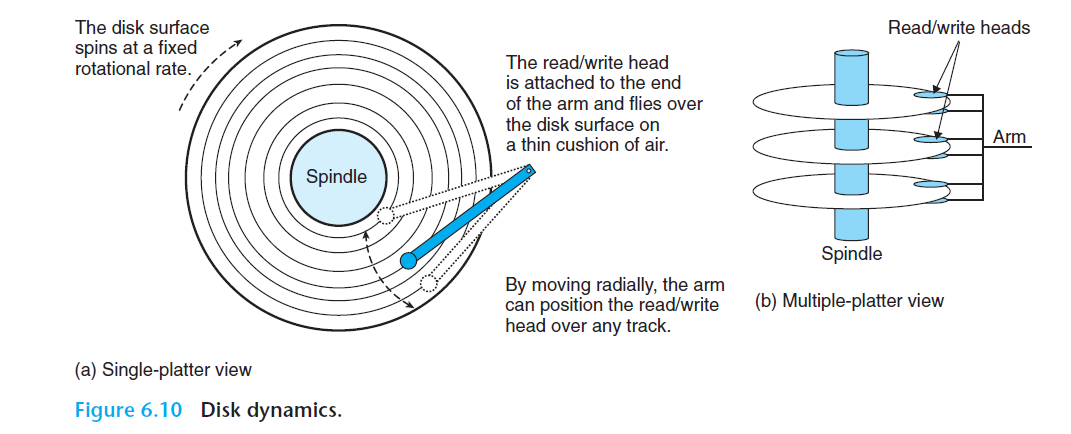
팔은 시속 80킬로미터의 속도로 (문자 그대로) 디스크 표면 위의 얇은 공기 쿠션 위를 날아간다. 이때 먼지라도 있으면 큰일이 나기에 디스크들은 언제나 공기 밀폐 용기에 넣어서 밀봉된다.
여담: fragmentation, defragmentation, 그리고 디스크 조각모음
file system fragmentation, 혹은 file system aging이라 불리는 이 현상은 아래 그림을들 참조하면 쉽게 이해 할 수 있다.
file을 지속적으로 읽고 쓰고 지우고 생성하고 수정하고 를 반복하면서 자연스럽게 파일의 블럭들이 디스크 상에 연속적으로 배열되지 않고 이곳 저곳 퍼져있게 되는 것이 fragmentation이다.



위와 같은 상황을 해결 해주는 것이 바로 디스크 조각 모음이다 = defragmentation
디스크 상에 하나의 파일에 할당된 블럭들이 연속적으로 배열되어야 파일 시스템이 파일의 정보에 더욱 빠르고 효율적으로 접근할 수 있기에 이는 성능과도 연결되어있다.
💻CS에서 사이클이란?
정확히는 clock cycle로 CPU가 행동하는 최소 단위!
A clock cycle, or simply a "cycle," is a single electronic pulse of a CPU.
During each cycle, a CPU can perform a basic operation such as fetching an instruction, accessing memory, or writing data.
1초당 몇번의 사이클이 있는지는, "hertz" 단위로 표현한다. cycles per sec.
https://techterms.com/definition/clockcycle
클럭 속도는 CPU 주요 사양의 한 요소입니다. 하지만 이게 실질적으로 어떤 의미인지 알고 계십니까?1
이는 우리가 흔히 프로세서(인텔, AMD 칩등등)의 성능을 나타내는 3.0Ghz 같은 개념과 바로 맞닿아있는 그놈이다!
프로세서의 좋은 성능 지표로 사용되는 것이 바로 이 클럭 속도/clock speed => cycle per sec 인 것이다! 와우
