coroutine 에 대해 잘 설명돼있는 블로그 글을 보고 정리한 내용이다.
구성 요소
coroutine
an instance of a suspendable computation
- 실행할 suspendable 코드 블록을 가지며 동시에 실행
- 중단을 거치면서 여러 스레드에 걸쳐 실행될 수 있다.
- coroutine 은 다음 class/interface 를 상속한다.
- Job, JobSupport, Continuation, CoroutineScope
coroutine builder
- coroutine 을 만드는 역할을 한다.
종류
launch
async
runBlocking
- coroutine scope 가 아닌 곳에서 coroutine 을 만들어준다.
fun main() = runBlocking {...}- 현재 스레드를 Block 한다.
suspending function
- coroutine 을 중단하는 함수이며, 그 자체로 coroutine 은 아니다.
suspend fun main()은 특수한 상황으로, 컴파일러가 main 함수를 coroutine 으로 실행시킨다.
- 스레드를 blocing 하지 않으며, 다음 coroutine 이 실행되도록 한다.
- suspending function 이나 coroutin 내에서만 수행된다.
- suspending function 이 호출되면, 그 시점에서의 실행 정보들을 Continuation 객체로 만들어 캐시해두었다가 실행이 재개(resume)되면 저장된 실행 정보를 기반으로 실행을 다시 이어 나간다.
- 그리고 그 실행정보를 받을 수 있도록 Kotlin 컴파일러는 자동으로 suspending function 에 Continuation type 의 parameter 를 추가한다.
coroutine context
- suspending function 을 실행할 수 있는 클래스라는 것처럼 보임
- CoroutineContext 를 상속한 Element 들을 고유한 Key 로 등록할 수 있음.

그림 출처
coroutine scope
- 인터페이스는 단순히 CoroutineContext 프로퍼티 하나로 구성됨.
public interface CoroutineScope {
public val coroutineContext: CoroutineContext
}- coroutine builder 나 scope builder 는 CoroutineScope 의 확장함수로 정의됨.
- 즉, builder 들에 의한 coroutine 생성은 소속된 CoroutineScope 에 정의된 CoroutineContext 를 기반으로 이루어지는 것이다.
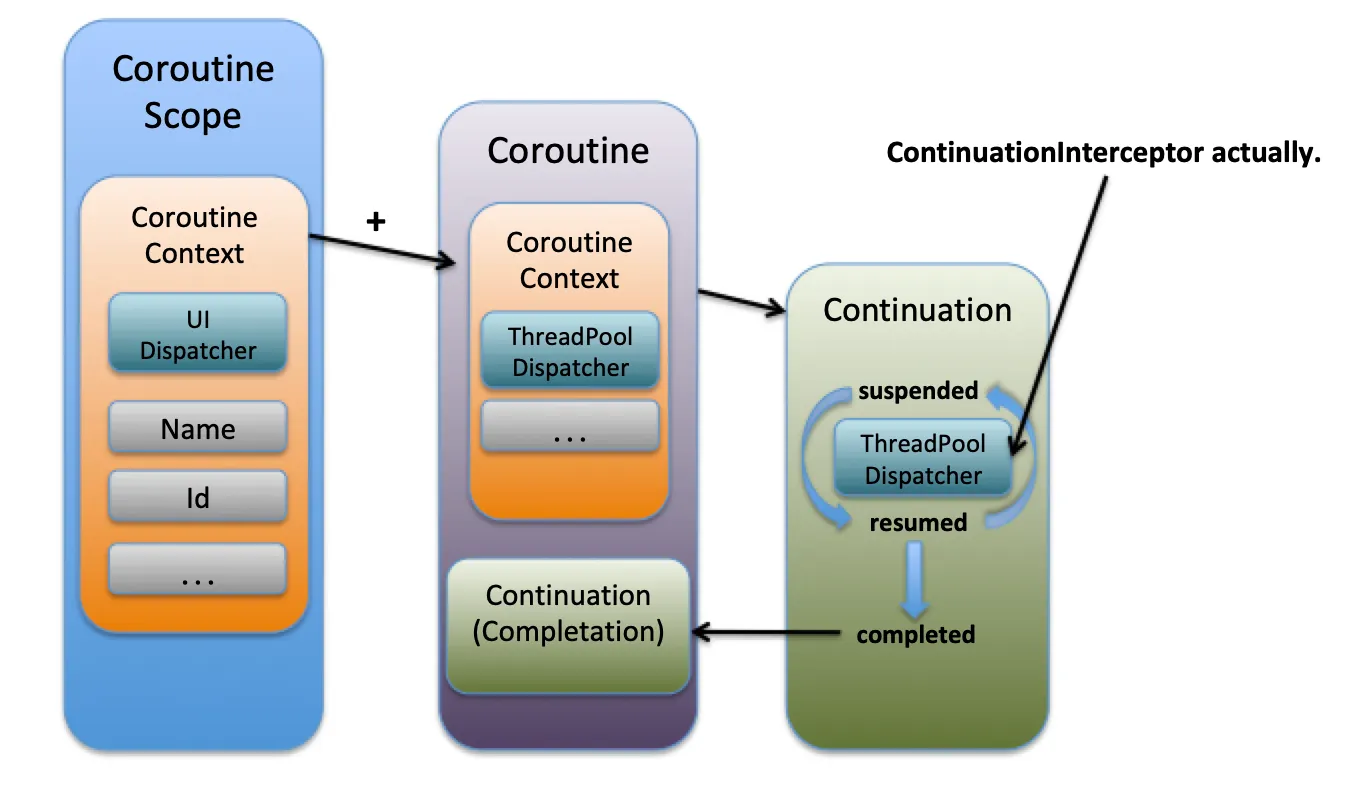
- coroutine 은 coroutine scope 안에서만 실행된다.
- 가장 왼쪽에 UI Dispatcher 는 현재 scope 에서 실행되는 suspending function 은 UI Thread 에서 수행된다는 것을 의미한다.
- 이제 이 scope 에서 coroutine 을 하나 생성했다. 이 때, 자신이 속한 scope 의 context 를 그대로 상속한다.
- 단, Dispacther 를 ThreadPoolDispacher 로 재정의했다.
- 이 coroutine 에서 수행되는 suspending 함수는 워커(백그라운드) 스레드에서 수행된다.
launch {}와 같은 coroutine builder 로 넘긴 실행할 code block Continuation 이라는 단위로 만들어짐.- Continuation 은 suspend 상태로 생성되었다가
resume()호출로resumed상태로 전환되어 실행된다. resume()이 호출될 때, 현재 context 의 dipacher 에게 스레드 전환(dispacth) 가 필요하다면dispatch()함수를 호출하여 적합한 스레드로 전달하여 수행한다.
Coroutine 은 light-weight thread?
공식 가이드에서 Coroutine 은 light-weight thread 라고 말한다. 이를 분석해보자.
fun main(args: Array<String>) = runBlocking {
repeat(100_000) {
launch {
delay(1000L)
print(".")
}
}
}위 코드에서 Dispatcher 를 재정의하지 않고 launch {} 를 사용한다. 따라서, runBlocking 이 사용하는 GlobalScope 를 상속 받아 사용하게 된다. 이 scope 에서 BlockingDispatcher 를 사용하는데, 이는 이벤트 루프 형태의 Dispacher 구현이다. 즉, 위 코드는 이벤트 루프 기반으로 10만번의 이벤트를 발생하여 . 을 출력하게 되며 스레드 부하가 없다. 따라서, OOM 을 피할 수 있게 된다.
scope builder
- 사용자 정의 coroutine scope 를 정의할 수 있다.
coroutineScope를 통해 생성된 scope 는 자식 coroutine 이 끝날 때까지 종료되지 않는다.- runBlocking 은 자식 coroutine 이 끝날 때까지 blocking 되지만, coroutineScope 는 그렇지 않다.
- 여기서 coroutine, coroutine scope 의 차이점이 햇갈린다. 혹은, coroutine builder, scope builder 의 차이점이 햇갈린다.
- coroutine is coroutine scope 라는 점에서 비슷해보인다...
continuation
이 부분은 정확히 알지 못해 이 블로그 글에서 옮겨 적었다.
- CPS(Continuation Passing Style) 에서 이야기하는 Continuation 개념의 구현체
- 어떤 일을 수행하기 위한 일련의 함수들의 연결을 각 함수의 반환값을 이용하지 않고 Continuation 이라는 추가 파리미터(callback)를 두어 연결하는 방식이다.
- Continuation 단위로 dispacther 를 변경한다거나 실행을 유예한다거나 하는 플로우 컨트롤이 용이해지는 장점이 있다.
Continuation이란?
1. 한줄 정의
- 중단된 계산을 이어서 실행하기 위해 필요한 스냅샷(상태 + 다음 실행 위치 + 컨텍스트)
- 컴파일러가 하는 일
suspend함수는 컴파일 단계에서 다음과 같이 바뀜
- 상태머신(state machine) 으로 변환: 각 suspend 지점(예: delay, 다른 suspend 호출)은 label 로 구분된 상태 번호가 됨.
- 마지막 파라미터로 Continuation 추가: 결과 타입 T를 담아서 resumeWith(Result) 로 콜백.
- 지역 변수 저장: 다음 재개 시 필요하도록 로컬 변수들을 컨티뉴에이션의 필드에 저장.
- 재개 지점 복원: resumeWith 호출 시 저장된 label 에 따라 정확한 위치부터 다시 실행.
- Continuation 구성
- context: CoroutineContext
- Job(취소/구조화), Dispatcher(스레드/큐), CoroutineName 등 메타데이터 묶음
- resumeWith(result: Result)
- 중단된 계산을 성공값 또는 예외와 함께 재개
- 예제
suspend fun fetch(): String { delay(100) // ⟵ suspend 지점 1 val a = apiCall() // ⟵ suspend 지점 2 (가정) return a.uppercase() }컴파일 후 개념적으로
fun fetch(cont: Continuation<String>): Any { when (cont.label) { 0 -> { cont.label = 1 // delay(100)를 시작하고, 완료되면 cont.resumeWith(Result.success(Unit)) return SUSPENDED } 1 -> { cont.label = 2 // apiCall() 비동기 시작, 완료되면 cont.resumeWith(Result.success(value)) return SUSPENDED } 2 -> { // 이전 단계에서 저장해둔 value를 꺼내 uppercase 후 return "VALUE".uppercase() } else -> error("invalid state") } }
## dispatcher
- coroutine 이 어떤 스레드(`Worker`)에서 처리될지 스케줄링 요청을 보내는 책임
- coroutine scope 에 어떠한 dispacher 도 설정돼있지 않다면, `Dispachers.Default` 를 사용한다.
- 사전 정의/커스터마이징 dispacher 를 coroutine context 에 지정해서 사용할 수도 있다.
- Main dispacher 는 애플리케이션 메인 스레드(single thread)에서 이벤트 루프를 이용해 coroutine 의 실행을 스케줄링함.
- Unconfined 는 continuation 이 재개되는 스레드에서 바로 실행함.
### coroutine 스케줄링
Kotlin/JVM 에서는 백그라운드 작업을 수행하기 위해 이 두 가지 dispacher 를 제공
- 주로 CPU 사용하는 작업은 `Default` 를, 주로 Network, Disk I/O 를 사용하는 작업은 `IO` 를 사용한다.
- `Defalult` 와 `IO` 는 `CoroutineScheduler` 라는 동일한 스케줄러를 공유한다.
- coroutine 들은 dispatcher 를 통해 `CoroutineScheduler` 로 요청될 때, `Task` 라는 형태로 래핑되어 요청된다.
- `Default` 를 사용하도록 설정된 coroutine 은 `NonBlockingTaskContext` 으로 표시되며, `IO` 를 사용하도록 설정된 coroutine 은 `ProbablyBlockingTaskContext` 로 표시된다. 따라서, 각각 CPU intensive, I/O intensive 한 작업에 적합하다.
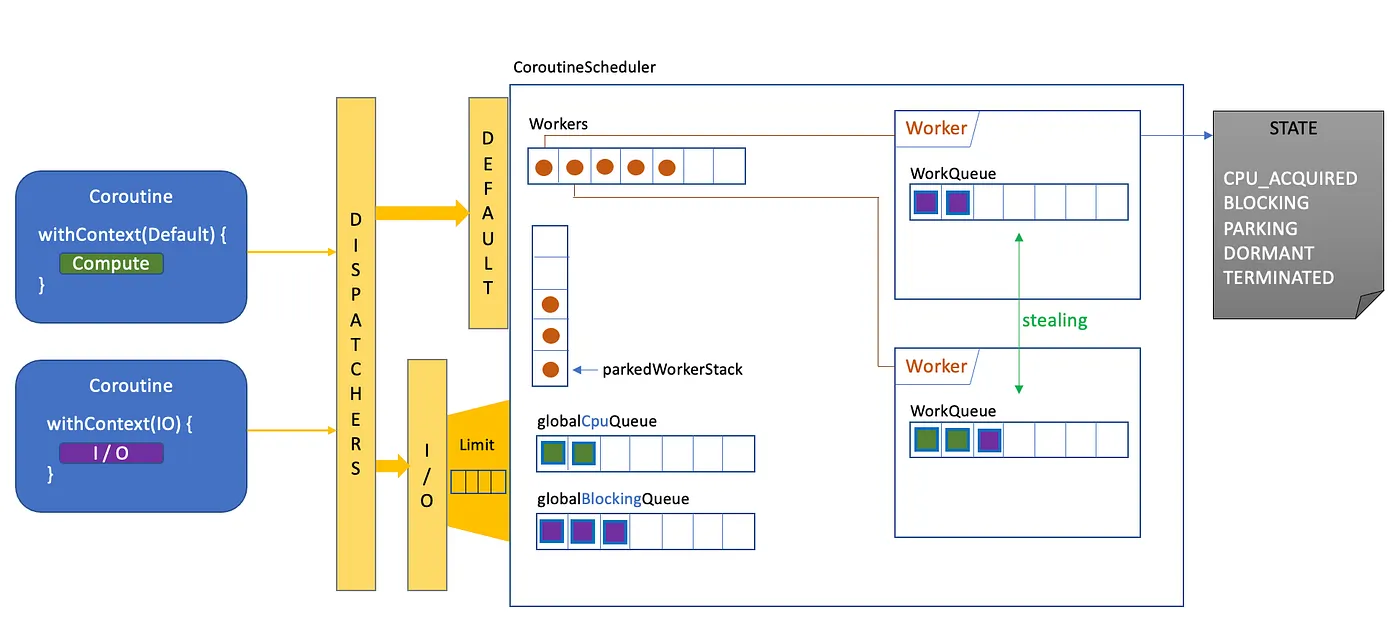
[그림 참조](https://myungpyo.medium.com/코루틴-디스패쳐-조금-더-살펴보기-92db58efca24)
dispacth to `CoroutineScheduler`
- `Deafult` 는 바로 coroutine 을 `Task` 로 래핑하여 `CoroutineScheduler` 에게 넘긴다. `IO` 는 `LimitingDispatcher` 로써 병렬 제한치(parallelism limit)라는 버퍼를 두고 스케줄링 요청을 할지, 자체적으로 갖는 `Task` 큐에 대기시킬지 결정한다.
`WorkerQueue`
- `CoroutineScheduler` 는 `Worker`(스레드)를 배열로 관리(생성/갱신/제거)한다.
- `Worker` 는 수행해야할 Task 들을 완료하고 나면 대기 상태에 들어가고 `parkedWorkerStack` 에 push 되어 대기하게 된다.
- 활성된 `Worker` 들이 바빠서 요청된 `Task` 를 수행할 수 없으면 이 대기 상태의 `Worker` 깨우고 `Task` 를 수행하도록 한다.
- stack 을 사용하여 LIFO 방식으로 `Worker` 들을 깨우는 이유는 최근까지 사용된 `Worker` 부터 재사용함으로써 메모리 footprint(용량) 감소와 referaence locality 면에서 이득 때문이다.
`WorkQueue`
- `Worker` 는 내부적으로 할당된 `Task` 를 담고 있는 `WorkQueue` 를 갖고 있다.
- 이 큐는 SPMC(Single-Producer, Multi-Consumer) 자료 구조로 사용된다.
- Producer 는 해당 큐를 소유한 `Worker` 이며 Consumer 는 다른 활성 `Worker` 들이다.
- 자신의 `Task` 를 마친 `Worker`는 parked 되기 전에, 다른 활성 `Worker` 를 살펴보고 `Task` 를 빼앗아 수행하는 Task Stealing Algorithm 이 적용되어 있다.
`globlaCpuQueue`, `globalBlockingQueue`
- `Worker` 에 할당되지 못한 `Task` 의 경우, 각 `TaskContext` 에 맞는 queue 에서 가용한 `Worker` 에 할당될 때까지 기다림