
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
github
generative agents를 어떻게 하면 발전시킬 수 있을지 고민하며 이를 인용한 논문들을 읽다보니 Reflextion(리뷰는 여기)가 너무 많이 보여서 읽지 않을 수가 없었다.
일반적으로 강화학습의 기본으로 agent가 environment를 지속적으로 인식하고 이를 기반으로 next action을 정의하고, LLM을 사용한 agent를 다루는 선행 연구들은 Inner Monologue (IM)을 기반으로 계속 스스로 생각의 연쇄과정을 거치며 next action을 정의하는데 이 두 방법을 융합하는 방법을 제안했고 결과는 좋았다.
Introduction
인간 지능의 unique feature는 task-oriented actions과 verbal reasoning (or inner speech)를 융합한다는 것인데 이것이 인간의 인지를 self-regulation, strategization할 수 있다고 한다. 즉, acting과 reasoning의 시너지가 중요하고 이 부분을 강조한다.
최근 prompted large language models에 관련해서 성능을 높이는 방법으로 CoT(Chain of Thoughts)과 같은 방법이 주를 이루었는데 이렇게 prompt 자체만을 사용하는 방법론은 모델 내부의 지식만을 사용해 답을 생성하고 외부 세계의 지식을 사용할 수 없다는 단점이 존재한다. 또한 reasoning 과정에서 hallucination과 error propagation이 발생한다는 큰 문제가 있다.
저자는 이러한 문제점을 개선할 수 있는 방법 ReAct를 제안하였고 여러 language reasoning, decision making tasks를 수행함으로써 성능을 확인하였다.
ReAct: Synergizing Resoning + Acting
일반적으로 agent가 task solving을 위해 environment와 interact하는 방법은 각 time step 마다 observation 를 environment로부터 받는다. 그럼 action 를 policy 에 따라 결정한다. (
로 mapping하는 policy를 학습하는 것은 highly implicit하거나 extensive computation이 필요할 경우 특히 더 어렵다.
그럼 ReAcT는 어떤 방법을 썼느냐. agent의 action space를 로 확장시켰다. 이때 은 language 공간을 의미한다. action 는 language 공간에 속하고 저자는 이것을 외부 enviornment에 영향을 미치지 않는 thought or reasoning trace라 하고 현재 context 에 대해 reasoning을 수행할 때 유용한 정보 역할을 하거나, context를 update할 때 사용된다. 즉, 이다.
저자가 설명하는 ReAct의 unique features는 다음과 같다.
-
Intuitive and easy to desing: ReAct prompts를 디자인하는 것은 직관적이고 자연어를 사용하기 때문에 human annotators가 생각하는 정보를 직접 입력을 통해 쉽게 생성할 수 있다.
-
General and flexible: flexible thought space와 thought-action occurrence format으로 인해 ReAct는 다양한 task에 맞춰 유연하게 적용될 수 있다.
-
Performant and robust: ReAct는 새로운 task에 대해서도 1~6개의 in-context examples정도만 있어도 좋은 성능을 보인다.
-
Huma aligned and cotrollable: ReAct의 큰 강점인 interpretable sequential decision making, reasoning process를 보장한다는 점 덕분에 process 과정 중 잘못된 부분을 사람이 바로 해석이 가능하고 agent behavior를 control, correct할 수 있다.
Methods
ReAct Prompting
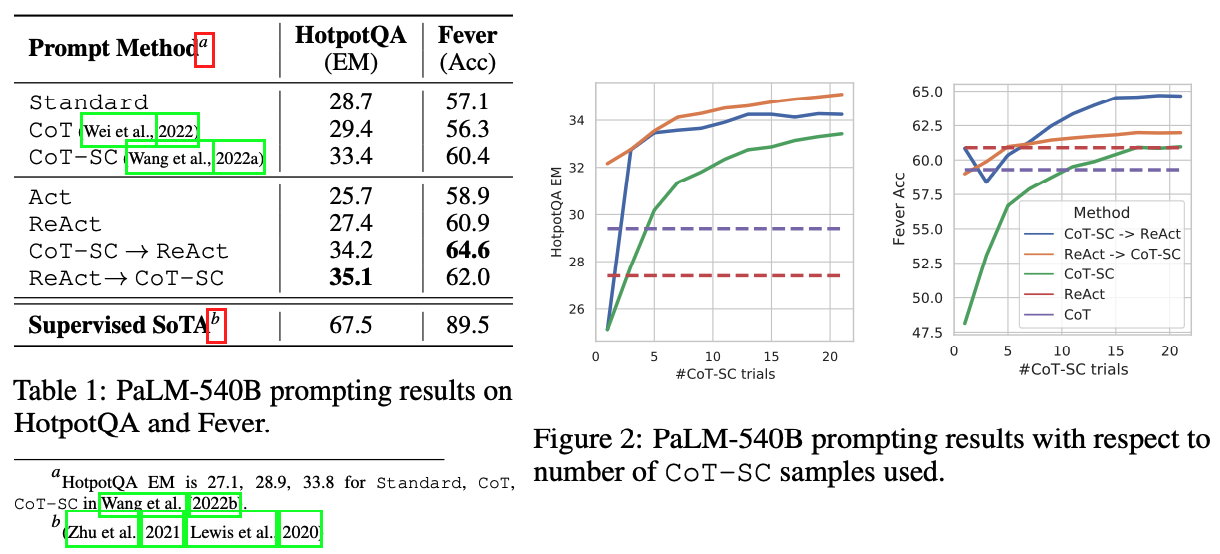
HotpotQA와 Fever 두 task에 대해 각각 무작위로 6개와 3개의 case를 선택하여 훈련 셋을 선정하였고 ReAct-format을 구성하였다. 이 prompting의 특징은 combination of thoughts를 사용하여 여러 기능을 수행하였다.
-
decompose questions ("I need to search x, find y, then find z")
-
extract information from Wikipedia observatoins ("x was started in 1844", "The paragraph does not tell x")
-
perform commonsense ("x is not y, so z must instead be...")
-
arithmetic reasoning ("1844<1989")
-
guide search reformulation ("maybe I can search/look up x instead")
-
synthesize the final answer ("...so the answer is x")
Combining Internal and External Knowledge
앞서 언급한대로 ReAct는 외부 지식을 활용할 수 있다고 하였는데, (기존 CoT는 internal knowledge만을 사용) 이 특징은 hallucinated facts로 인한 문제를 크게 개선하는데 도움을 주었다. 저자는 ReAct와 CoT-SC를 결합한 방법을 제안했는데 이다.
Result
 HotpotQA에 대한 ReAct와 CoT의 success, failure types
HotpotQA에 대한 ReAct와 CoT의 success, failure types
HotpotQA에 대한 실험 결과에 대한 세가지 해석을 하였다.
-
Hallucination은 CoT의 중대한 문제점이다. ReAct 대비 false positive rate이 6%, 14%로 큰 차이를 보이고, 주요 failure 원인이 hallucination으로 56%를 차지한다.
-
interleaving reasoning 과정에서 action & observation steps이 ReAct의 groundedness와 trustworthiness를 향상시키지만 flexibility in formulating reasoning steps를 감소시킨다. CoT에 비해서 ReAct가 가지는 error패턴이 있었는데 이를 "reasoning error"라 정의하였는데, 적절한 next action으로 이동하지 못하고 계속 loop를 도는 현상으로 인한 error를 말한다.
-
ReAct의 경우 search 과정에서 성공적인 informative knowledge를 retrieving하는 것이 critical하다. search 과정에서 noninformative information을 가져오는 경우가 error casesdml 23%를 차지한다.
실험 결과 ReAct + CoT-SC가 가장 좋은 성능을 보였다. 이러한 결과는 internal knowledge (CoT의 그것)과 external knowledge (ReAct의 그것)을 적절히 조합하는 것이 좋은 성능을 낸 원인이라 할 수 있다.
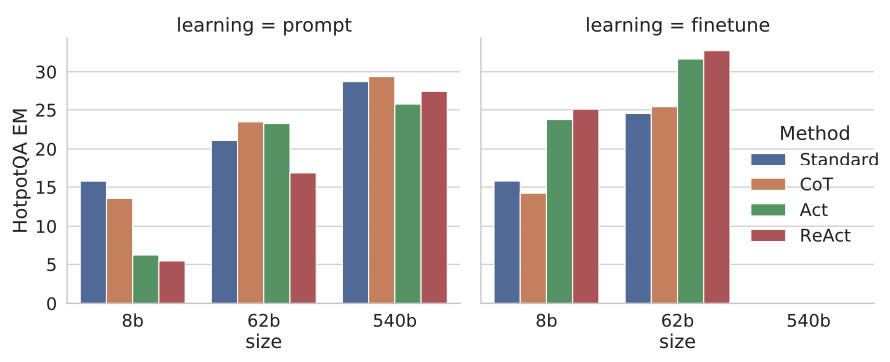 HotpotQA에 대한 prompting & fintuning scailing results
HotpotQA에 대한 prompting & fintuning scailing results
HotpotQA에 대해 (Standard, CoT, Act, ReAct) 4가지 방법을 사용해 prompting과 finetuning을 수행한 결과이다. prompting의 경우 ReAct가 낮은 성능을 보였는데, in-context examples 몇가지로는 reasoning과 acting 두가지를 동시에 학습하기에는 어렵다는 해석을 하였다. 하지만, 3000개의 example을 가지고 finetuning한 결과 가장 좋은 성능을 보인 반면, Standard와 CoT는 오히려 성능이 떨어졌다. 이 현상에 대한 원인으로 Standard와 CoT는 학습을 memorize (potentially hallucinncated)에 초점을 뒀지만 ReAct의 경우 generalizable skill for knowledge reasoning을 학습했기 때문으로 해석하였다.
Decision Making Tasks
language-based interactive decision-making task인 ALFWorld, WebShop을 가지고 평가하였다.
ALFWorld
text-based game으로 6가지 타입의 tasks가 존재한다. 외부 환경과 자연어로 navigating과 interacting을 한다. (e.g. go to coffetable 1, take paper 2, use desklamp 1)
ReAct를 prompt하기 위해 각 task type에서 무작위로 training sample을 선정해 3개의 trajectories를 만들었다. 각 trajectory는 sparse thoughts를 가지는데 (1) decompose the gole, (2) track subgoal completion, (3) determine the next subgoal, (4) reason via commonsense이다.
WebShop
WebShop은 ALFWorld와 달리 엄청 다양한 structured & unstructured texts (상품명, 상품 설명, 옵션 등을 포함한 Amazon에서 크롤링 된 데이터)를 가지고 있으며 1.18M real-world products와 12k human instructions를 가지고 있다. 이 task는 user instruction (e.g. "I am looking for a nightstand with drawers. It should have a nickel finish, and priced lower than $140.")에 따라 적합한 상품을 구매하는 것이다.
Act prompt: search, choose product, choose options, buy
ReAct prompt: reasoning 과정을 추가해서 what to explore, when to buy, what products options are relevant to the instruction
Result
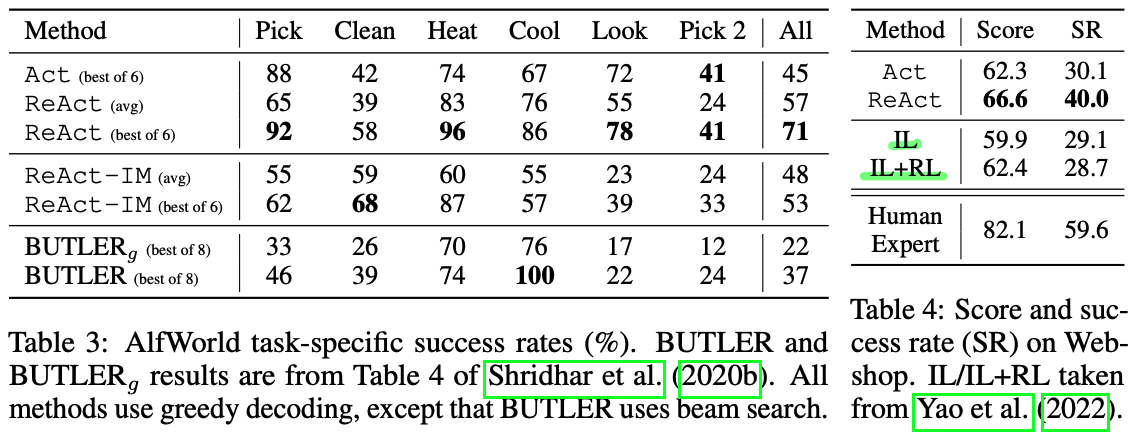 ALFWorld 와 WebShop에 대한 실험 결과
ALFWorld 와 WebShop에 대한 실험 결과
WebShop의 경우 one-shot Act prompting만으로도 IL과 IL+RL methodsf를 이미 넘어서는 성능을 보였고 ReAct의 경우 Act에서 추가적으로 10% 정도의 성능향상을 보였다. example들을 분석한 결과 ReAct가 instruction과 관련된 상품을 선택하는 것과, noisy observations과 actions사이의 gap을 줄여주는 역할에 기여를 하는 것으로 보였다.
하지만 아직도 human expert 대비 15%정도의 괴리가 있으므로 개선할 여지가 있다고 보인다.
On the value of internal reasoning vs. external feedback
LLM을 사용한 본 시스템과 유사한 prior work는 Inner Monologue(Huang et al. 2022) (IM)인데, IM은 environment state와 what needs to be completed by the agent for the goal to be satisfied에 대한 observations이 limited되어있다는 한계점을 가지고 있다. 반면 ReAct의 decision making은 flexible하고 sparse하기 때문에 diverse reasoning type을 가능하다는 차별점이 있고 다양한 task에 적용하기 용이하다.
이러한 주장 (두 방법론의 차이점)을 증명하고 internal reasoning vs. simple reactions to external feedback의 중요성을 보이기 위해 ablation 실험을 진행하였다. Table 3를 보면 ReAct가 IM-style prompting (ReAct-IM)의 성능을 한참 웃돌았다. 실험 중 ReAct-IM이 subgoals이 완료되었는지에 대한 판단 실수를 하거나 다음 subgoal이 무엇이 되어야할지 판단할 때 실수가 발생하는 것을 관찰하였다고 한다. ALFWorld 환경에서는, (IM이)commonsense reasoning이 부족하기 때문에 어떤 item이 어디에 있어야하는지 헷갈려하는 모습을 보였다.
Conclusion
저자가 제안한 ReAct는 유연하고 (여러 task에 적용 가능), 해석가능하며 (자연어를 통해 구동되므로 직관적으로 에러 파악이 가능), multi-hop QA, fact checking, interactive decision-making과 같은 reasoning과정이 필요한 task에서 높은 성능을 보였다.
느낀점 & 추가로 공부해야할 점
사실 method 자체보단 implementation을 확인해보는게 더 중요할 것 같다. 또한 본 논문에서 사용한 ALFWorld는 일종의 갇힌 방 안에서 진행되는 task이므로 어느정도 "닫혀있는" 환경으로 보는게 맞을 것이다. 즉, interaction하는 대상에 어떤 action을 취하는지는 agent 마음이지만 (물론 이상한 action을 수행하면 nothing happens가 output으로 나오긴 한다.) 반대로 environment 자체에도 ReAct와 같은 메커니즘을 적용할 수 있다면 내가 궁극적으로 기여하고자 하는 open world에 더 가깝지 않을까? 이걸 구현할 수 있으면 "열린" 공간에 관한 벤치마크를 만들거나 할 수도 있을 것 같다.
