블로그 쓰기 겁나 빡세다
잠시 쉬어 가는 글을 쓰고자 한다.
하지만 다나오는 사이트를 크롤링 할 때 꼭 필요한 내용을 적을거다.
그럼 크롤링 얘기인데 왜 쉬어가는 글이냐고?

앞서 모듈에서 소개한 BeautifulSoup모듈이 한번 쓰이는데 이게 한 섹션으로 넣기엔 짧고, 섹션에 묻어가기엔(?)길어서 그냥 쉬어가는 척 적는거다.
사실 쉬어가기라기 보다 기본 내용에 별첨에 가깝다.
단시 별첨이 중간에 있을 뿐..
그러니까 뒤에 내용 이해하고 싶으면 이 포스팅도 꼭 봐야한다.

BeautifulSoup, 뷰티풀스프, 뷰숲 다양하게 불리는데 크롤링을 배우면 가장 먼저 배운다.
(이하 뷰숲 이라고 칭하겠다)
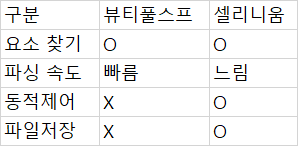
적어도 나에겐 계륵같아서 없으면 아쉽고 그렇다.
나는 주로 링크를 가져와서 쓸 때, 태그의 클래스나, id명이 같아서 박스 영역의 태그만 가져와야 할 때 주로 사용한다.
나머지는 거의 기존 selenium을 이용한다.
개인적인 이러쿵 저러쿵은 넘어가고,
간단한 뷰숲 소개와 뒤에 다나오는 사이트에 사용할 코드로 뷰숲 사용법 설명하고 포스팅 맺으련다.

포스팅..,
뷰티풀스프, 아름다운 비누
나는 왜 비누만 하면 이짤이 떠오를까..? 어디서 부터 잘못된걸까?

뷰숲을 불러오는 기본적인 문법은 ▼다.
BeautifulSoup(requests.get('url'), 'html.parser')사실 뷰숲은 requests모듈과 함께 짝을 이루는 모듈이다.
플로우는 ①requests로 http를 호출한다. 쉽게 말하면 사이트를 가져온다 ②BeautifulSoup로 사이트 내 html이라고 불리는 태그들의 모음에서 필요한 정보를 꺼낸다.
하지만 우리는 html을 셀레니움으로 호출했으니 requests가 아닌 셀레니움 객체로 호출해야한다.
설명이 어렵나?

바로 실전으로 들어가자!
다나오는 사이트로 회귀
사용 목적은 특정한 영역(박스)에 있는 특정 브랜드(태그) 개수 세기 이다.
① 셀레니움의 드라이버 객체 뷰숲으로 불러오기
② 뷰숲으로 영역 불러오고 객체에 저장
③ 영역 내 필요한 부분(브랜드들)가져오기
뒤에 포스팅 주제가 바로 브랜드들을 차례로 클릭하기 이다.
차례로 클릭하기 위해 for반복문을 쓸건데 그러려면 브랜드 개수를 알아야한다.
근데 class name이 똑같은게 많아서 특정 영역안에 있는 즉, 브랜드를 감싸고 있는 태그 안의 태그 개수만 셀거다.
셀레니움의 드라이버 객체 뷰숲으로 불러오기
뷰숲을 불러오는 기본 문법에 우리 기존에 만든 웹제어 기능 객체만 가져오면된다.
기억 안나는 변태들을 위해 말해준다.
우리가 기존에 만든 웹제어 기능 객체는 'driver'이다.
기존에 사용한다는 뷰숲에서 사용된 requests대신 driver를 사용해주면된다.
BeautifulSoup(driver.page_source, 'html.parser')▲를 soup이라는 변수에 저장하겠다.
이제, 뷰숲 사용 준비가 끝났다.
뷰숲으로 영역 불러오고 객체에 저장
다나오는 사이트 개발자가 똑같은 class명을 여러군데 사용해서 이렇게 복잡해진거니 나말고 그를 원망하자.

사용 준비를 마쳤으면 사용해줘야겠지.
뷰숲으로 태그를 가져와서 태그와 태그 내 요소(속성)와 그 값을 딕셔너리 형태로 특정 영역을 불러오면 된다.
▼이렇게 말이야.

요소를 찾는 일종의 공식인데 절대 외우지마 나도 뷰숲, 셀레니움 번갈아가면서 쓰다보면 헷갈려;
어렵지? 이럴 땐 실전예제가 채고지!

뒤 섹션에 실제 사용할 태그로 영역 선택 객체를 만들어보겠다
뷰슢객체 : 아까 우리 방금 soup이라는 변수에 할당했다 그치?
find : 요소 하나를 찾아달라는 명령어이다.
태그명 : 우리가 찾을 영역인데, 몇번 말하지만 이건 html에 대한 이해가 조금 있어야해
요소 : class로 찾기로 하였다.
요소값 : F12를 눌려 찾아 보니 ▼이렇게 위치가 나와있다.
item_list item_list_all
객체 할당 : 아무 변수명으로 넣어주면 된다. 난 item_list 라고 하겠다.
일종의 공식이라 말한 거에 그대로 대입해보자.
item_list = soup.find('ul', attrs = {'class':'item_list item_list_all'})이제 영역 내의 브랜드 개수만 셀 수 있게됐다!

영역 내 필요한 부분(브랜드들)가져오기
사실 이건 설명할 필요가 없는데;
위 영역을 선택하는 공식과 똑같다.
다만, 방금 지정한 영역내에서만 찾을 거라서 영역 객체를 가져다 써야한다.
▼이렇게 말이야
영역객체.find('태그명', attrs={"요소":"요소값"}){어려워 짤}
그리고 두가지만 바꿔주면 된다.
① find에서 find_all : 브랜드를 찾는게 아니라 브랜드들!을 찾을 거라서 all을 붙여줘야한다.
② 태그명, 요소값 변경 : 아까 우리가 찾은 값은 영역이고, 이제 찾을 건 브랜드이기 때문에 당연히 바꿔줘야한다.
▼이렇게 위치가 나와있다.
li태그 내 class 이름은 sub_item normal_item이다.
이거도 그대로 대입해보자
item_list.find_all('li', attrs = {'class':'sub_item normal_item'})위 요소를 개수 세기 함수로 세어주면 끝이난다.
class명이 같아서 특정 요소 개수만 세기 위해
① 특정 영역을 선택해
② 영역 내 요소만 선택하는 작업을 해보았다.
아 이쯤 되면 질문이 나올법 하다.
"그냥 셀레니움으로는 특정 영역안에 브랜드(태그) 개수 못세냐?"
"야 반말하냐?"
"못세나..요?"
"대답은 다음시간에 해주겠다."
'ㅅㅂㄻ...'

낄낄
(다음 섹션 중간 쯤 위 답변이 나오지 않을까 싶다. 내 벨로그 또 들어와야겠네?)
여기까지 읽은 변태들은 없겠지만 있다면 고맙다.
오늘도 열심히 포스팅한 나는 수고했고, 너네는 다 읽었으면 썩 꺼져라

오늘의 코딩
soup = BeautifulSoup(driver.page_source, 'html.parser')
item_list = soup.find('ul', attrs = {'class':'item_list item_list_all'})
sub_items = item_list.find_all('li', attrs = {'class':'sub_item normal_item'})
print(len(sub_items))
