정보 단위
- 비트: 0과 1을 나타내는 가장 작은 정보 단위
- 바이트: 여덟 개의 비트를 묶은 단위
- 워드: CPU가 한 번에 처리할 수 있는 데이터의 크기 (CPU에 따라 달라짐)
이진수의 음수 표현
- 2의 보수: 어떤 수를 그보다 큰 에서 뺀 값
ex) 의 보수:
혹은, 모든 0과 1을 뒤집고 거기에 1을 더한 값으로도 생각할 수 있다.
ex)
Q. 이 의 음수표현인지 십진수 1의 이진수 표현인지 어떻게 구분할까?
A. 플래그 사용
16진수 2진수
16진수 한 글자 4 비트 이진수
ex)
, , ,
p.65 확인문제
3번
의 음수를 2의 보수 표현법으로 구해보기
문자 인코딩/디코딩
- 인코딩: 문자 0과 1로 변환
- 코드 포인트: 글자에 부여된 고유한 값 - 디코딩: 0과 1 문자로 변환
-
아스키 코드
영어 알파벳, 아라비아 숫자, 일부 특수 문자로 구성된 총 128개 문자 집합
각 문자는 7비트로 표현 가능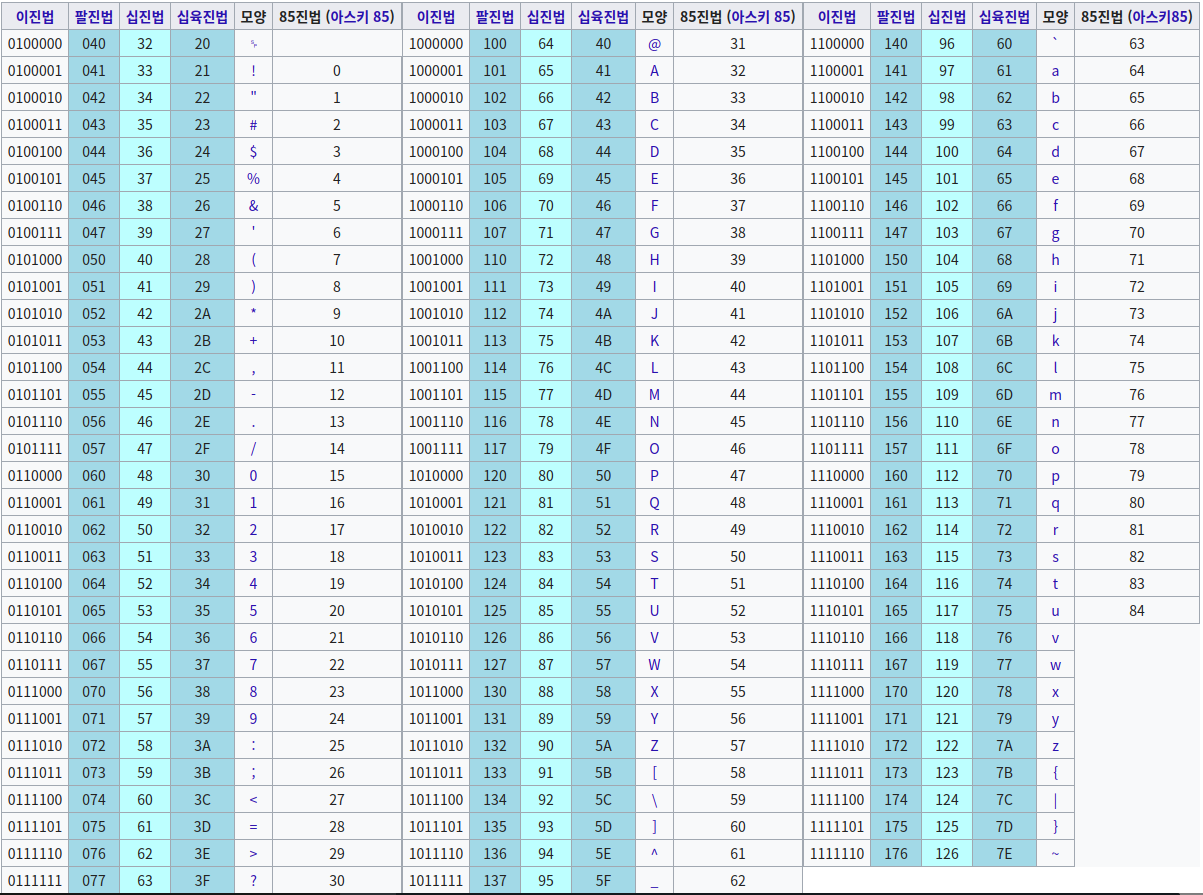 https://velog.io/@exploit017/%EC%95%84%EC%8A%A4%ED%82%A4-%EC%BD%94%EB%93%9C%ED%91%9C
https://velog.io/@exploit017/%EC%95%84%EC%8A%A4%ED%82%A4-%EC%BD%94%EB%93%9C%ED%91%9C
-
EUC-KR
KS X 1001, KS X 1003이라는 문자 집합을 기반으로 하는 대표적인 완성형 한글 인코딩 방식
- 완성형 인코딩: 초성, 중성, 종성의 조합으로 완성된 글자에 고유한 코드를 부여
ex) '가'= 1, '나' = 2 - 조합형 인코딩: 각 초성, 중성, 종성에 비트열을 할당하여 조합
EUC-KR은 한글 한 글자에 2바이트=16비트 코드를 부여
즉, EUC-KR로 인코딩된 한글은 네 자리 16진수로 표현
 https://ithub.tistory.com/277
https://ithub.tistory.com/277
-
CP949
EUC-KR로는 표현할 수 없는 문자까지 커버하고자 고안된 방식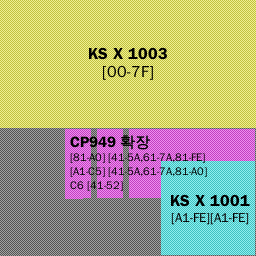 https://ko.wikipedia.org/wiki/%EC%BD%94%EB%93%9C_%ED%8E%98%EC%9D%B4%EC%A7%80_949
https://ko.wikipedia.org/wiki/%EC%BD%94%EB%93%9C_%ED%8E%98%EC%9D%B4%EC%A7%80_949
-
UTF-8
- 유니코드: 여러 나라의 문자를 아우르는 표준 문자 집합
각 글자에 부여된 값 자체를 인코딩된 값으로 삼지 않고 이 값을 다양한 방식으로 인코딩 ex) UTF-8, UTF-16 등
- UTF-8: 1바이트 ~ 4바이트까지의 인코딩 결과를 만듦
 코드 포인트 범위에 따른 UTF-8 인코딩 방식
https://d2.naver.com/helloworld/76650
코드 포인트 범위에 따른 UTF-8 인코딩 방식
https://d2.naver.com/helloworld/76650
참고문헌
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=299014282&start=slayer


꾸준히!