오차역전파
신경망에서는 gradient descent를 통해 가중치 매개변수 값을 업데이트합니다. 이 때, 가중치 매개변수 값을 오차역전파를 이용하여 계산할 수 있습니다.
다음의 상황을 가정해보겠습니다.
- 문제: 이진 분류
- loss function L: cross-entropy (log loss) function
- 훈련 샘플 갯수: 1개 (∴ loss function = cost function)
- 활성화 함수 g(x)=1+e−z1; sigmoid function
- y^=g(wx+b)
업데이트를 진행할 가중치 매개변수를 θ라 하면, coss function E(θ)는 다음과 같습니다.
- E(θ)=L(y−y^)=−(tln(y^)+(1−t)ln(1−y^))
y^이 w와 b에 관한 함수 이므로, E(θ) 역시 w와 b에 관한 함수입니다. 따라서, w와 b가 업데이트할 가중치 매개변수입니다.
경사하강법에 의해, 각 layer에서 가중치 매개변수는 다음과 같이 업데이트할 수 있습니다.
- wt+1:=wt−ϵ∂w∂E(θ)
- bt+1:=bt−ϵ∂b∂E(θ), where ϵ: learning rate, t: learning step
즉, local gradient인 ∂w∂E(θ), ∂b∂E(θ) 값을 계산해야합니다.
∂w∂E(θ), ∂b∂E(θ) 값은 chain rule을 이용하여 global gradient인 ∂y^∂E(θ)값을 통해 보다 쉽게 계산할 수 있습니다.
구체적으로 다음과 같이 주어진 상황을 생각해봅니다.
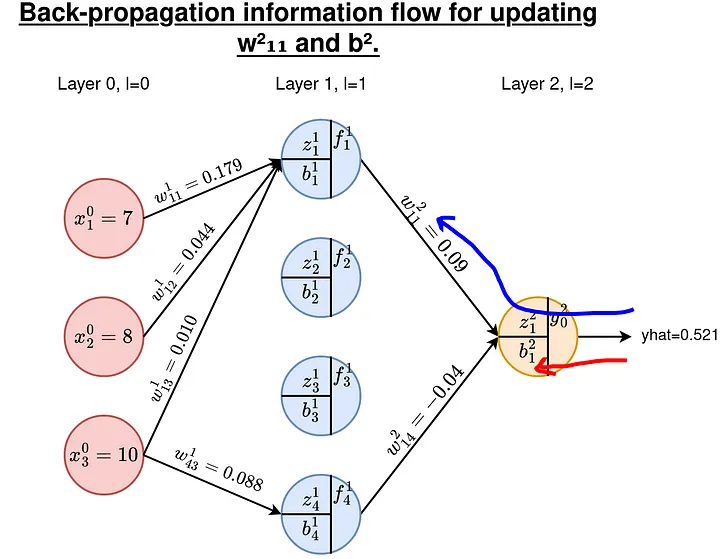 https://towardsdatascience.com/how-does-back-propagation-work-in-neural-networks-with-worked-example-bc59dfb97f48
https://towardsdatascience.com/how-does-back-propagation-work-in-neural-networks-with-worked-example-bc59dfb97f48
chain rule에 의해
∂w112∂E=∂y^∂E∂z12∂y^∂w112∂z12
이므로, 각 term을 구한 후 곱해서 결과값을 얻을 수 있습니다.
∂y^∂E=∂y^∂(−(tln(y^)+(1−t)ln(1−y^)))=−y^t+1−y^1−t
∂z12∂y^=∂z12∂g(z12)=∂z12∂,(1+e−z121)=(1−y^)y^
∂w112∂z12=∂w112∂(f11w112+f12w122+f31w132+f41w142+b12)=f11
∴ ∂w112∂E=(−y^t+1−y^1−t)((1−y^)y^)f11
참고문헌
