이번 포스팅에서는 text와 audio 데이터를 이용한 한국어 감정 분류 모델을 만들어보겠습니다.
데이터셋은 AI-Hub의 '감정 분류를 위한 음성 데이터셋'을 이용하였습니다.
위 데이터셋은 총 3회차(4차년도, 5차년도, 5차년도_2)에 걸쳐 수집한 음성 데이터가 들어있는데요, 각 음성 파일에 대응하는 발화문과 감정 label도 포함되어있습니다.
라이브러리 import 및 데이터 로드
우선, 필요한 라이브러리를 import 해줍니다.
import os
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from numpy import dot
from numpy.linalg import norm
import seaborn as sns
import matplotlib.pyplot as plt
import urllib.request
from sentence_transformers import SentenceTransformer
import librosa
import librosa.display
from IPython.display import Audio이번 포스팅에서는 5차년도의 데이터만을 이용하려고 합니다. 데이터를 로드하고 shape을 확인합니다.
txt_data = pd.read_csv("/Data/5차년도.csv", encoding= 'CP949')
print(f"txt_data 길이: {len(txt_data)}")
print(f"txt_data shape: {txt_data.shape}")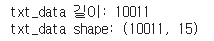
데이터 구성은 다음과 같습니다.

다행히 결측치는 없네요 :)

텍스트 데이터 관찰 및 전처리
데이터를 좀 더 살펴보면, 발화문의 감정 label을 상황 label로 보기에는 어려운 데이터들이 관찰됩니다. 1번-5번 감정 label과 감정세기를 종합하여 가장 감정세기가 큰 감정 label로 해댱 발화문의 감정 label를 다시 설정해주겠습니다.
우선, 감정 label을 모두 소문자로 바꿔주겠습니다.
txt_data['1번 감정'] = txt_data['1번 감정'].apply(str.lower)
txt_data['2번 감정'] = txt_data['2번 감정'].apply(str.lower)
txt_data['3번 감정'] = txt_data['3번 감정'].apply(str.lower)
txt_data['4번 감정'] = txt_data['4번 감정'].apply(str.lower)
txt_data['5번 감정'] = txt_data['5번 감정'].apply(str.lower)
소문자로 잘 바뀐 것을 확인할 수 있습니다.
1-5번 감정 label마다 감정 세기를 더하여 감정 세기가 제일 큰 감정을 해당 발화문의 감정 label로 설정합니다. 감정 세기가 동일할 경우에는 sentiments 딕셔너리의 순서를 따라 다음과 같이 우선순위가 부여됩니다.: angry > sadness > happiness > fear > disgust > surprise > neutral
즉, angry와 sadness의 감정 세기가 같다면 해당 발화문의 label은 angry가 됩니다.
임의로 설정한 기준이니만큼 추후에 조정이 필요할 것 같습니다 :)
def get_keys(dic): #returns a key for max values in dic
key_list = list(dic.keys())
val_list = list(dic.values())
pos = val_list.index(max(val_list))
return key_list[pos]
final_label = []
for i in range(len(txt_data)):
sentiments = {'angry':0, 'sadness':0, 'happiness':0, 'fear': 0, 'disgust':0, 'surprise':0, 'neutral':0}
sentiments[txt_data.iloc[i]['1번 감정']] += txt_data.iloc[i]['1번 감정세기']
sentiments[txt_data.iloc[i]['2번 감정']] += txt_data.iloc[i]['2번 감정세기']
sentiments[txt_data.iloc[i]['3번 감정']] += txt_data.iloc[i]['3번 감정세기']
sentiments[txt_data.iloc[i]['4번 감정']] += txt_data.iloc[i]['4번감정세기']
sentiments[txt_data.iloc[i]['5번 감정']] += txt_data.iloc[i]['5번 감정세기']
final_label.append(get_keys(sentiments))
final_label_df = pd.DataFrame(final_label, columns=['final_label'])
new_txt_data = pd.concat([txt_data[['wav_id', '발화문']], final_label_df], axis = 1)데이터의 분포를 살펴보겠습니다.
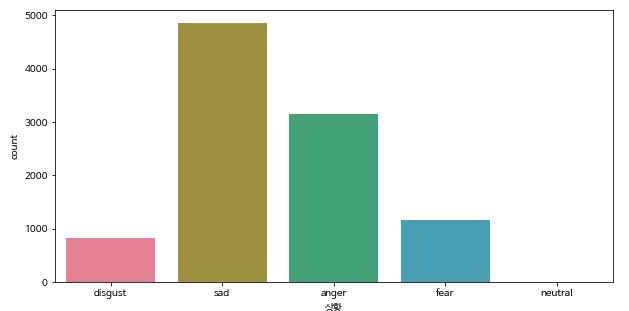
'상황' column을 기준으로 데이터의 분포를 보면 다음과 같이 sad > anger > fear > disgust >neutral 순으로 데이터가 많은 것을 관찰할 수 있었습니다.
바꾼 label을 기준으로 데이터의 분포를 살펴보겠습니다.
fig, ax = plt.subplots(figsize=(10, 5))
sns.countplot(x = new_txt_data['final_label'], palette = "husl", ax = ax)
plt.show()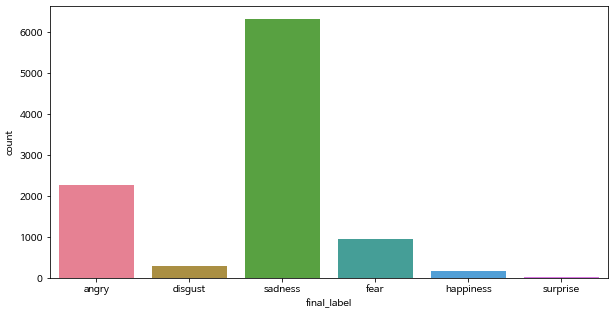
이번에도 sad로 label된 데이터가 가장 많네요. 그런데 데이터가 균등하게 분포되어있지 않아서 이 부분을 조정해야겠네요.
현재는 발화문과 발화문에 대응하는 음성 데이터를 함께 쓸 계획이기 때문에 우선은 조정하지 않고 음성 데이터 처리로 넘어가보겠습니다.
음성 데이터 로드
우선, 음성 데이터 파일을 로드하겠습니다. AI-Hub에서 다운받은 파일은 zip인데요, colab 환경에서 다음과 같이 압축 해제를 수행할 수 있습니다. 파일 경로는 물론 상황에 맞게 수정해야합니다 :)
# %cd zip '폴더 path'
# !zip -FFv '압축을 해제할 원본 zip path' --out '폴더 path/copied.zip'
# !unzip -qq '폴더 path/copied.zip'
압축을 해제한 폴더 안에 있는 오디오 파일을 로드합니다. 모든 오디오 파일을 처리하려고 하니 colab 환경에서는 용량이 부족하여 우선 1000개만 사용해봅니다.
audio_path = 'Data/5차년도_wav'
wav_list = os.listdir(audio_path)
wav_list_tmp = random.sample(wav_list, 1000) #colab 용량 한계로 1000개만 랜덤으로 선택한 1000개의 데이터에 대하여 발화문, wav_id, final_label로 구성된 데이터 프레임을 생성하겠습니다.
(혹시 더 나은 방법이 있다면 피드백 부탁드립니다!)
wav_list_tmp_id = [] #wav 파일명에서 .wav 제외하고 순수한 wav_id를 추출
for i in range(1000):
wav_list_tmp_id.append(wav_list_tmp[i][:-4])
wav_list_tmp_label, wav_list_tmp_sentence = [], []
for x in wav_list_tmp_id:
wav_list_tmp_label.append(new_txt_data[new_txt_data['wav_id'] == x]['final_label'].values[0])
wav_list_tmp_sentence.append(new_txt_data[new_txt_data['wav_id'] == x]['발화문'].values[0])
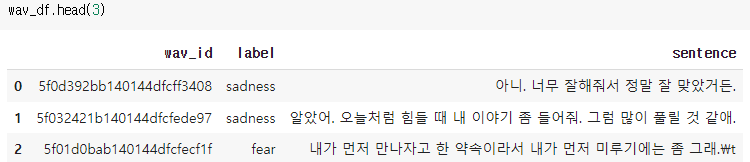
wav_df = pd.DataFrame(
{'wav_id': wav_list_tmp_id,
'final_label': wav_list_tmp_label,
'sentence': wav_list_tmp_sentence
})잘 생성이 되었네요 :)
랜덤으로 선택한 1000개의 label 분포는 어떤지 확인해보겠습니다.
fig, ax = plt.subplots(figsize=(10, 5))
sns.countplot(x = wav_df['final_label'], palette = "husl", ax = ax)
plt.show()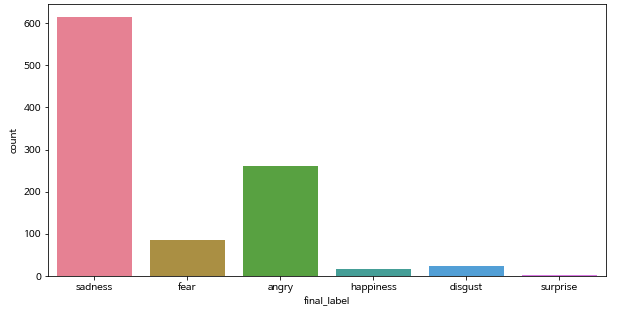
전체 데이터와 유사한 양상을 보이네요. 랜덤으로 잘 선택된 것 같습니다.
다음 포스팅부터 본격적으로 발화문(텍스트)와 음성 데이터로부터 feature vector를 추출하여 학습을 진행시켜보겠습니다.
To do
- 데이터 라벨링 조정 (같은 감정 세기를 같은 감정의 정확한 label은 어떤 것일까?)
- 데이터 분포 조정 (각 label당 데이터 갯수가 동일하도록)
