확장 가능한 parallel fuzzing 인프라 구축 및 성능 비교 분석 (2-3) github issue fuzz 및 한계점
5) 미해결 이슈 (bug)를 찾아 Fuzz시도
https://github.com/google/leveldb/issues 속 bugs 태그가 붙은 이슈들 중 해결이 된 것과 해결이 되지 않은 이슈들을 골라서 Fuzzing을 해 볼 생각이다.
(1) leveldb에 엄청 긴 문자열을 넣으면 오류가 나는 현상
ver. (Aug 18,2019)
#include <iostream>
#include <cassert>
#include <cstdlib>
#include <string>
#include <leveldb/db.h>
using namespace std;
int main(void)
{
leveldb::DB *db = nullptr;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "./testdb", &db);
assert(status.ok());
cout<<sizeof(size_t)<<endl;
std::string key = "A";
std::string value = string(4300000000,'h');
std::string get_value;
leveldb::Status s = db->Put(leveldb::WriteOptions(), key, value);
if (s.ok())
s = db->Get(leveldb::ReadOptions(), "A", &get_value);
if (s.ok())
cout << get_value.size() << endl;
else
cout << s.ToString() << endl;
delete db;
return 0;
}[zhou@localhost test_leveldb]$ make
g++ hello_leveldb.cc -o hello_leveldb -lpthread -lleveldb -std=c++11
[zhou@localhost test_leveldb]$ ./hello_leveldb
8
Corruption: unknown WriteBatch tag42억바이트의 문자열을 삽입할 때 까지는 작동이 잘 되나, 43억 바이트 이상이면 삽입이 되지않음. size_t 변수는 운영체제의 비트에 따라 최대값이 변하는데, 32비트면 unsigned int (0~4,294,967,295)가 범위지만, 64비트면 unsigned long long(0~18446744073709551615)이 최대 범위라고 한다.
하지만 64비트도 4,294,967,295까지가 범위라고 실행되므로 fuzzing을 해보는 것도 괜찮다고 생각이 든다.
https://github.com/google/leveldb/issues/718
= 해당 이슈가 leveldb 32bit에서 재현되는지 실험
코드를 똑같이 우분투 16.04 32비트에서 구버전의 leveldb를 클론받아 make를 해주었다. 위 이슈가 올라온날이 2019년 8월이라, 2019년 5월의 PR이 적용된 파일을 받아서 컴파일 하였다.
https://github.com/google/leveldb/pull/664
git reset --hard [6571279](https://github.com/google/leveldb/commit/6571279d6de21fe33caa31b2ea4170d34b15b10e)

AFL++는 우분투 20.04 버전 이상에서 지원을 하기 때문에, 이 2019년 5월 버전을 g++을 이용한 일반적인 컴파일을 시도하고, issue와 똑같은 에러가 발생하는지 확인해 볼 예정이다.
****cmake를 3.9 이상으로 설치를 미리해주어야 , leveldb를 빌드할 때 오류가 발생하지 않는다. 32비트에선 cmake가 공식적으로 지원하지 않는다.

아무튼 빌드를 하려고 하니, 43억은 32비트상 받아들이지 못한다.

42억으로도 빌드를 해보니 이런 오류가 발생했다.

terminate called after throwing an instance of 'std::length_error'
what(): basic_string::_S_create
Aborted (core dumped)32비트가 허용하는 숫자를 넘어설 때 이런 문구가 발생한다고 한다.
= 해당 이슈가 leveldb 64bit에서 재현되는지 실험
연구실 컴퓨터 기준으로 진행해봤다.
‘42억

42억 1

killed가 뜨며 실행되지 않아, testdb를 제거하고 다시 시도해보았다.
rm -r testdb
42억 1까지는 잘 되는 모습이다.
이번엔 43억을 시도해봤다.

43억을 시도하니까 Corruption: unknown WriteBatch tag가 표시된다.
64비트에도 여전히 43억은 제대로 처리하지 못하는 모습을 확인할 수 있다.
버그가 재현이 되는 것을 확인하였다.
(2) LEVELDB FUZZ
AFLPlusPlus로 fuzz를 할 때 input 하는 테스트케이스의 용량은 1mb가 최대이므로 testcase의 용량을 unsigned int 보다 더 크게 fuzz를 하려던 초기 계획은 무산 되었다.
다만, 초기 key를 testfile로 받고 value를 43억보다 큰 숫자로 받게 하는 testcode로 fuzzing하면 무언가 나오지 않을까? 라는 생각에 다음과 같이 코드를 작성하였다
//bytetest.cpp
#include <iostream>
#include <fstream>
#include <cassert>
#include <sstream>
#include <vector>
#include <string>
#include "leveldb/db.h"
#include "leveldb/write_batch.h"
using namespace std;
void addKeyValues(leveldb::DB *db, std::ifstream& file) {
if (file.is_open()) {
leveldb::Status s;
string line;
string key;
string value;
double tmp = 4300000000;
while (getline(file, line)) {
key = line;
value = string(tmp+,'h');
string get_value;
s=db->Put(leveldb::WriteOptions(), key, value);
if (s.ok())
s = db->Get(leveldb::ReadOptions(), key, &get_value);
if (s.ok())
std::cout << get_value.size() << std::endl;
else
std::cout << s.ToString() << std::endl;
}
} else {
cout << "File not opened" << endl;
return;
}
return;
}
int main(int argc, char * argv[])
{
leveldb::DB *db = nullptr;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "./testdb", &db);
assert(status.ok());
cout<<sizeof(size_t)<<endl;
string filename = argv[1];
std::ifstream file(filename);
addKeyValues(db, file); //custom function to load DB with key-value pairs
delete db;
return 0;
}
이후, 원래 하던 것 처럼 컴파일을 해주었다 (afl-clang-lto 사용)
/AFLplusplus/afl-clang-lto++ -o ./testbyte_leveldb ./test.cpp leveldb/libleveldb.a -I ./leveldb -fsanitize=address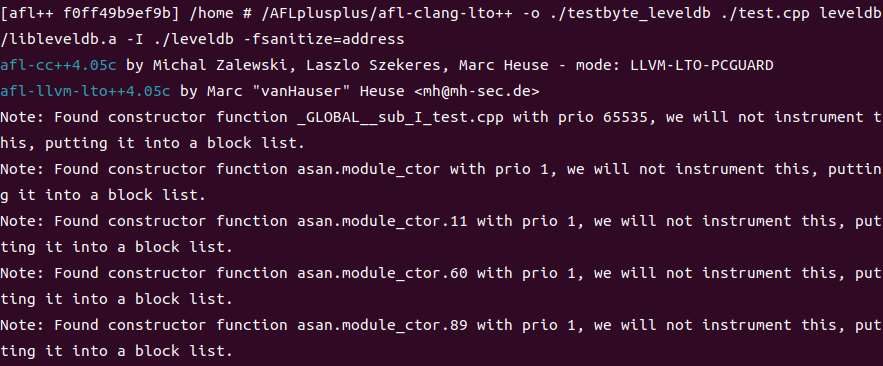

정상적으로 컴파일이 된 모습을 확인할 수 있다.
컴파일이 완료 된 후, testcase에 들어갈 test.txt를 생성하였고,
**test**그다음에 afl-fuzz를 진행하였다.
afl-fuzz -i /home/testcase/ -o ./out ./testbyte_leveldb @@그러면, 이러한 오류가 발생한다.
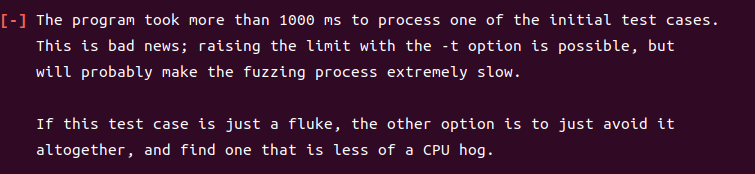
한 테스트케이스당 1초가 넘게 걸리니 -t 플래그를 사용해서 시간 한도를 올리는 것은 가능하지만 아마도 퍼징 과정을 극도로 느리게 만들 것이라고 한다.
될 수 있으면 이런 테스트 케이스를 피하라고 한다
그래도 -t 플래그를 사용해서 시간 한도를 올려줄 생각이다.
afl-fuzz -i /home/testcase/ -t 6000 -o ./out ./testbyte_leveldb @@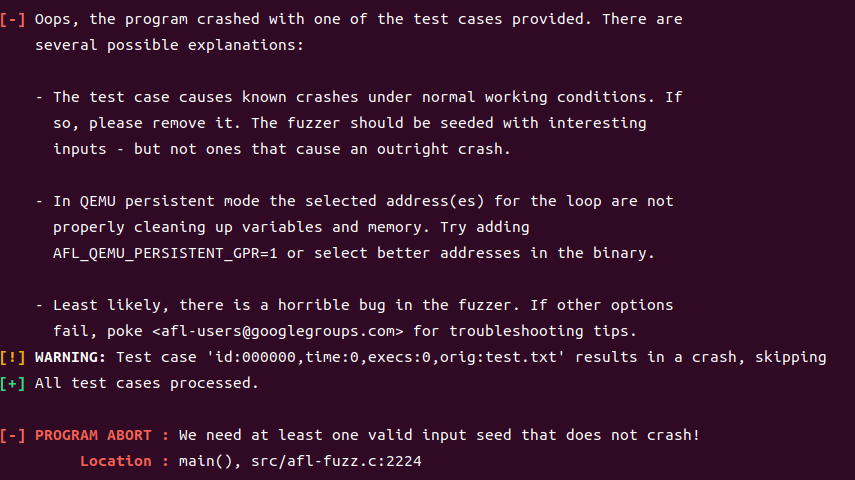
이랬더니 .. input이 crash가 나면 안된다고 해서 생각을 해보았다.
저번에 쓰던 랜덤코드를 활용해 unsigned int보다 작은 수를 생성해 crash가 안나게 하면 되지 않을까 라는 생각이 들었다
unsigned int의 범위는 4294967295 이지만 그보다 작은 4200000000에 1과 1억 사이의 random한 값을 더해 key와 value를 put해보려고 했으나 .. 20억정도 보다 숫자가 커지면 실행이 되지 않았다
또한 간헐적으로 오류가 발생하는 코드는 아까와 같은 오류코드가 계속 뜨면서 fuzz자체가 되지 않는다.
결국 진행 할 수가 없는 상황이라 버그가 발생하지 않는 코드로 fuzz를 진행하려한다.
//bytetest.cpp
#include <iostream>
#include <fstream>
#include <cassert>
#include <sstream>
#include <vector>
#include <string>
#include <cstdlib>
#include <ctime>
#include "leveldb/db.h"
#include "leveldb/write_batch.h"
using namespace std;
void addKeyValues(leveldb::DB *db, std::ifstream& file) {
if (file.is_open()) {
leveldb::Status s;
string line;
string key;
string value;
//RANDOM VALUE
srand((unsigned int)time(NULL));
int rnd = rand();
rnd = (int)rnd % 210000000;
//0 < value < 210000000
if (rnd == 0) {
rnd = 1;
}
cout << "rnd is" << rnd << endl;
double tmp = 100000000;
while (getline(file, line)) {
key = line;
value = string(tmp+rnd,'h');
string get_value;
s=db->Put(leveldb::WriteOptions(), key, value);
if (s.ok())
s = db->Get(leveldb::ReadOptions(), key, &get_value);
if (s.ok())
std::cout << get_value.size() << std::endl;
}
} else {
cout << "File not opened" << endl;
return;
}
return;
}
int main(int argc, char * argv[])
{
leveldb::DB *db = nullptr;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "./testdb", &db);
assert(status.ok());
cout<<sizeof(size_t)<<endl;
string filename = argv[1];
std::ifstream file(filename);
addKeyValues(db, file); //custom function to load DB with key-value pairs
delete db;
return 0;
}
afl-fuzz -i /home/testcase/ -t 60000 -o ./out ./testbyte_leveldb @@시간제한을 60초까지나 늘려줬다. 이렇게 까지 늘려주지 않으면 아까와 같은 오류코드가 뜨면서 fuzzing이 되지않는다. 애초에 너무 용량이 크고 막대해서 fuzz가 힘들었던 모양이다.
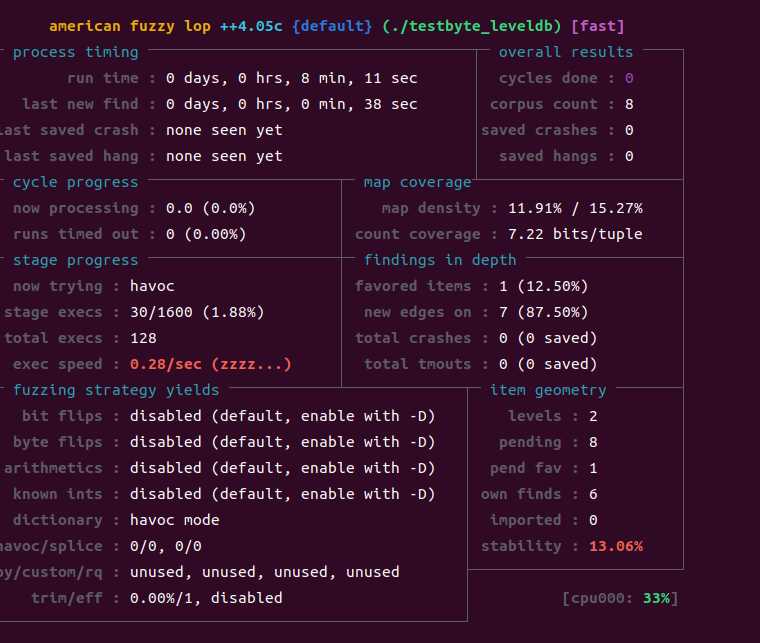
결국 버그가 발생한다는 것은 알겠지만, 이 점을 활용해서 fuzz를 할 수 없었다는 것이 결론이다. 결국 버그는 미해결 된 상태로 LEVELDB를 Fuzz하는 것을 마무리 할 수 밖에 없었다.
6) LevelDB Fuzzing 한계점
levelDB는 다른 CVE 케이스들과는 근본적인 차이점이 있다. Xpdf, tcpdump, libtiff, visualboy advance와 같은 프로그램들은 자체적으로 가장 중심이 되는 프로그램이 하나가 있고, 거기에 정해진 형식의 input값만을 받아서 작동한다. 예를 들어 Xpdf는 pdfToText라는 프로그램이 있어서 pdf 파일을 input값으로 주면 그 파일을 텍스트 파일로 변환해준다. 중요한 건 pdfToText 파일은 Xpdf를 개발한 사람들이 만든 코드로 컴파일된거라서 이 프로그램만 퍼징해도 pdfToText와 관련있는 모든 코드들이 cover가 된다.
하지만 **levelDB의 경우, 자체적으로 작동시킬 수 있는 코드가 없다. LevelDB의 기능들은 구현되어 있지만, 실제로 그 기능들을 활용하기 위해서는 결국 사용자가 cpp 코드를 따로 작성해서 해당 기능들을 사용해야 관련된 코드들이 동작한다.** 문제는 여기에 있다. LevelDB는 키-값 저장 시스템이라 Put, Get, Delete이 가장 주된 operation이지만, 이거 아외에도 levelDB의 헤더파일들을 살펴보면 훨씬 더 많은 기능들이 있다는 것을 알 수 있다. 당장 깃허브 문서를 보면 Iterator의 활용, Slice라는 클래스, Batch를 활용한 atomic update가 있을 뿐 더러, 이외에도 header file에는 아직 제대로 구현해보지는 못했지만 destroy_db와 db가 이상해진 걸 대비해서 복구시키는 repair_db도 있다. 즉, **leveldb 코드 전체의 커버리지를 늘리기 위해서는 결국 각 기능들을 전부 사용자가 올바르게 구현한 뒤, 올바른 input값을 줘서 fuzzing을 하게 해야 한다.** (1) Parallelization을 활용한 방안
AFL++의 parallelization은 방법 자체는 간단하다. 퍼징할 때 옵션에 **-M과 -S**를 주고, 각 fuzzer마다 **sanitizer**등의 기능들을 다르게 추가해주기만 하면 된다. 문제는 leveldb를 가동시키기 위해 코드를 직접 작성해야 한다는 점이 발목을 잡는다. 하나의 코드를 여러 개의 fuzzer가 fuzzing해봤자, leveldb의 극히 일부분만 fuzzing 작업이 될 것이라는 점이다. 생각나는 방안은 다음과 같다. 우선 leveldb에서 구현할 수 있는 모든 기능들을 최대한 많이 구현한다. 다만, 이 모든 기능들을 하나의 코드에 구현하는 건 힘들어 보이므로 여러개의 코드 파일로 나눠야 한다. 그리고 각 코드 파일들을 각각 컴파일한 뒤, 따로따로 fuzzing이 parallel하게 진행되어야 할 것이라고 생각한다. 이렇게 하면 하나의 fuzzer는 leveldb의 특정 기능들을 테스트할 것이고, 다른 fuzzer는 leveldb의 다른 기능들을 fuzzing할 것이라고 기대하고 있다. 물론 Put, Get, Delete는 가장 핵심이 되는 기능이기 때문에 중복이 될 것이라고 생각한다. 그래도 현재로서는 이 방안이 가장 효과적이지 않을까 생각한다.
