
✅ fetch join이란?
JPQL에서 성능 최적화를 위해 제공하는 기능으로써, 특정 엔티티를 DB에서 가져올 때 연관된 엔티티 또는 컬렉션까지 모두 가져오는 방법이며, 주로
N+1 문제를 해결하기 위해 자주 사용된다.
❗️ N+1 문제
먼저 조회하는 엔티티를 가져오는 쿼리가 1번 실행된 후에, 연관된 엔티티를 가져오기 위해 각각의 쿼리가 N번 더 나가게 되는 경우를 말한다.
✅ fetch join 사용 전략
즉시 로딩(EAGER)을 사용하면 예상치 못한 쿼리가 나가게 되는데, 이를 방지하기 위해 default 값이 EAGER인
xxToOne관계의 경우 지연 로딩(LAZY)으로 설정 해두고, fetch join을 사용해 연관된 엔티티를 한꺼번에 가져오는 전략을 많이 사용한다.
✅ fetch join과 일반 join
우선
fetch join과일반 join은 역할이 다르다.
- 먼저
일반 join의 경우, sql의 join과 역할이 같다. 연관된 엔티티를 함께 조회하는 것이 아니라, select 절에 있는 데이터만 조회한다.
- 반면
fetch join의 경우, 결과적으로 sql로 변환되어 db상 join 쿼리가 나가는 것은 동일하지만, 엔티티 입장에서 엔티티 객체 그래프를 조회할 때 사용하는 기능이며, 엔티티를 온전히 조회할 수 있어야 한다.
예를 들어, 1:N 관계인 member와 board 엔티티가 존재하고, board를 DB에서 조회하는 경우를 생각해보자.
select b from board b join fetch b.member 처럼 JPQL로 fetch join을 사용하면,
select m.*, b.* from board join member ... 와 같은 쿼리가 나갈 것이다.
=> 연관된 엔티티 전부를 한꺼번에 가져오는 것이다.
이 점을 생각해보면, fetch join은 join과 달리 엔티티의 특정 컬럼을 projection(select 절에서 선택)하는 것이 불가능하다는 것을 알 수 있다.
일반 join : 필요한 데이터를 찍어서 projection할 수 있다
fetch join : 필요한 데이터를 찍어서 projection하는 것이 불가능하다.
따라서, 여러 테이블을 join해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야하는 경우에는, fetch join 보다는 일반 join을 사용하여, 필요한 데이터들만 조회해서 DTO로 반환하는 것이 효과적이다.
✅ fetch join의 특징
1. 엔티티에 직접 적용하는 글로벌 로딩 전략보다 높은 우선순위를 가진다.
- LAZY로 설정하고 fetch join을 사용할 수 있는 이유이다.
2. 둘 이상의 컬렉션은 fetch join 할 수 없다.
- 예를 들어, 1:N:M 관계인 3개의 엔티티가 존재할 때, fetch join은 한 번만 사용할 수 있다는 것이다.
3. 컬렉션을 fetch join하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없다.
fetch join이라는 것은 결국 SQL로 변환되어 join 쿼리가 나가는 것이다.
SQL join을 생각해보면, OneToMany 관계인 두 테이블을 join하면 One쪽의 데이터는 Many쪽 데이터만큼 불어난 결과를 반환한다.
이 경우, One 쪽의 데이터를 가져오는 것이 주된 목적이고, 이 때 연관된 엔티티(Many)를 부수적으로 함께 조회하고 싶었던 것인데, 조회 결과는 Many 쪽을 기준으로 조회된 것이므로, 의도한 바와는 조금 다른 결과를 얻은 것이다.
이 때, 페이징을 적용하게 되면 불어난 데이터들 때문에 원하는 개수만큼의 데이터를 얻는 것이 불가능해진다. 이 경우 하이버네이트는 경고 로그를 남기고 메모리에서 페이징을 시도하며, 이는 매우 위험하다.
예를 들어, team과 member, 즉 1:N 관계에서 컬렉션 fetch join을 시도하는 경우를 생각해보자.teamA를 대상으로 컬렉션 fetch join을 시도했고, 페이징을 적용해 2개의 데이터만 가져오려고 했다면,
의도한 결과는 아래와 같이 team을 기준으로 2개의 데이터(teamA, teamB)를 반환하는 것이다.
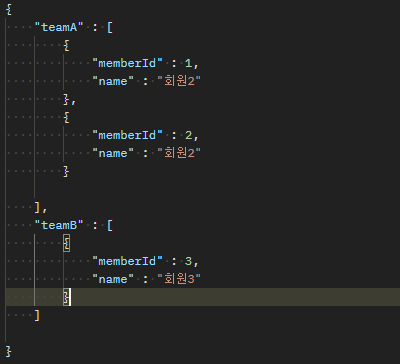
하지만 결과는 아래의 예시처럼 member를 기준으로 데이터를 2개 가져오기 때문에, 필요한 teamB는 누락된 채로 반환되어 페이징이 꼬일 것이다.
예시
반면, OneToOne, ManyToOne 같은 단일 값 연관 필드들은 fetch join을 해도 데이터가 불어날 일이 없으므로 페이징이 가능하다.
✅ fetch join과 즉시 로딩(EAGER)
언뜻 보면
fetch join과즉시 로딩(EAGER)이 비슷하다고 느낄 수 있지만, 둘은 완전히 다르다.
먼저, 즉시 로딩은 결과적으로 N+1 문제를 해결하지 못한다.
다시 위의 member와 board 엔티티가 존재하고 board를 DB에서 조회하는 경우를 생각해보자.
즉시 로딩의 경우, 먼저 board를 가져오는 쿼리만 날리고, member는 조회하지 않는다.
그 후에, 즉시 로딩으로 설정되어 있기 때문에 연관된 member를 각각 쿼리를 날려 추가로 조회한다(N+1)
따라서 즉시로딩을 사용해도 여전히 N+1 문제가 발생한다.
- 반면,
fetch join의 경우 위에서 보았듯이 하나의 쿼리로 모두 가져오기 때문에 N+1 문제를 해결할 수 있다.
자료 출처 : 김영한님의 자바 ORM 표준 JPA 프로그래밍 - 기본편
